FERNme
Health Warn
- License — License: NOASSERTION
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 6 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
A lightweight memory engine for AI agents using fuzzy graphs, Hebbian updates, and optional LLM gating.
🌿 FERNme
Fuzzy-Edged Recall Network
A user-owned, near-zero-LLM memory layer for AI agents. It learns each person from their behavior — including how they talk and feel — stays token-flat forever, and lets people see, edit, and own what's remembered. The engine is substrate-agnostic: it remembers wherever an agent acts — websites today (shopping, support, booking, healthcare, tutoring, gov), desktop and mobile next.
![]()
![]()
![]()
![]()
![]()
![]()
Cheap to write · flat to read · interpretable by design · owned by the user
✨ The one-paragraph pitch
Most agent memory is written by an LLM on every turn (expensive, hallucination-prone), evaluated on question-answering (not actions), and assumes a single user. FERNme is built for the opposite world — agents that act for many people, in any domain (a sale, a booking, a resolved ticket, a completed lesson, a kept appointment — "outcome" is whatever the goal is). It starts where agents already act today — websites — and the same user-owned memory is designed to extend to desktop and mobile. Each user is a sparse, fuzzily-weighted node in a per-site graph; edges update by a Hebbian co-occurrence rule with zero LLM calls, retrieval is spreading activation, and the prompt-facing "card" stores only deviations from a population prior. The result: per-turn cost stays flat as a profile grows for years, the user can read and correct their own memory, and the same engine assembles — only with the user's consent — into a cross-site supernode they fully control.
🎯 Why FERNme (the strong points)
| 🪶 Zero-LLM writes | Memory updates are arithmetic on a graph — 0 LLM calls per interaction vs. ~2 for extraction-based memory. No write-time cost, no write-time hallucination. |
| 📉 Flat token cost forever | The prompt card holds ~25 tokens whether it's a visitor's first day or fifth year. A full-history baseline is 77× larger by 120 interactions. |
| 🧠 Strong in every regime | Ties a frequency counter on static recall, beats it 0.72 → 0.13 on drift, and wins on context (0.62 → 0.51). Decay + spreading activation unify stability and adaptivity. |
| 🪟 Glass-box & user-owned | Every preference is visible and editable. People fix what's wrong, delete everything, or export it. Privacy becomes a feature, not a liability. |
| 🏬 Built for outcomes | Evaluated by conversion, not QA. A simulated storefront shows +16% conversion lift vs. non-personalized recommendations. |
| 🧩 User-owned supernode | Sign in across sites → your memories assemble like Lego into one profile you control, default-deny, sensitive data walled off. Not surveillance — the mirror image of it. |
| 🎚 Cost/quality dial | One engine, a memory_mode switch: free key-less pure by default, opt-in gated/offline LLM enrichment when you need Mem0-grade nuance — pay only for the compute you use. |
| 🔐 Verifiable & unlearnable | Every action is logged in a tamper-evident HMAC chain the user can replay to detect any alteration; forget_everywhere wipes the profile and unlearns the person from the population prior — provable right-to-be-forgotten. |
| 🛡 Injection-proof by design | Writes are arithmetic, not LLM extraction, so page/user text can't be "talked into" becoming a belief — tested that injected instructions never enter memory. |
| 🧠 Private collective intelligence | New users benefit from crowd patterns on turn one (cold-start from a population prior), with k-anonymity + differential privacy so no individual leaks. A network-effect moat single-user memories can't have. |
| 🗣 Style & mood memory | Learns how each person communicates (terse/verbose, formal/casual, energy) and tracks their mood with trend detection, so the agent can match tone and notice when someone's frustration is rising — in any domain. |
| 🎯 Outcome-learning, any goal | Memory is reinforced by results — not just recall. record_outcome(success) strengthens what worked and weakens what backfired, where "success" is any goal (purchase, booking, resolved ticket, completed lesson…). |
| 🔍 Explainable | Ask why(user, attr) — get the evidence (observations + good/bad outcomes + dates). No black box. |
| 🔌 Deployable plumbing (research preview; harden per SECURITY.md) | SQLite or Postgres (tested on real PG 16), REST + MCP servers, consent gating, injection-safe writes, proactive triggers — all tested. |
📊 Benchmarks
Honest scope: the numbers below are on synthetic or LLM-authored data, not real
users. They validate the mechanism and surface failures; a real-human pilot is the
pending next step. The Mem0 (LLM) head-to-head needs an API key and is not yet run.
On LLM-authored people (closest to real, agentic ingestion)
A sample of 16 of 92 third-person profiles (ChatGPT-authored), read as prose only and
remembered agentically, then scored against hidden answer keys:
| metric | result |
|---|---|
| preference coverage vs. hidden key | 75% |
| communication style — formality | 100% |
| mood sign / mood arc | 94% / 100% |
| preference drift detected | 94% |
| injection attempts ignored | 100% |
| note → card compression | 7.3× |
(The "agent" here is an LLM reading prose, so these reflect agent + engine together — the
engine is solid; the extraction quality is the agent's.)
Cost, recall, and Pareto (synthetic, multi-seed)
Reproduce:
python -m fernme.eval.cost_variance·... quality·... drift·... context·... ablation·... pilot
Cost — per-turn memory tokens vs. profile size (5 seeds):
| metric | FERNme | baseline |
|---|---|---|
| card size | 24.9 ± 0.5 tokens (flat) | full history grows linearly |
| at 120 interactions | 1× | 77× ± 1.3 larger |
| LLM calls per write | 0 | ~2 (extraction memory) |
Recall quality — precision@5 vs. ground-truth preferences (5 seeds × 40 users):
| regime | 🌿 FERNme | frequency | recency |
|---|---|---|---|
| static recall | 0.74 | 0.74 | 0.47 |
| drift (taste shifts) | 0.72 ✅ | 0.13 ❌ | 0.59 |
| context (precision@3) | 0.62 ✅ | 0.51 (blind) | — |
The headline: FERNme is the only method strong everywhere. Frequency can't forget (fails drift); recency is noisy (fails static). FERNme's decay + spreading activation get both.
Cold-start ablation — population prior gives +0.06 precision@5 at turns 1–3, washing out by turn 10 (a real but modest, cold-start-only benefit).
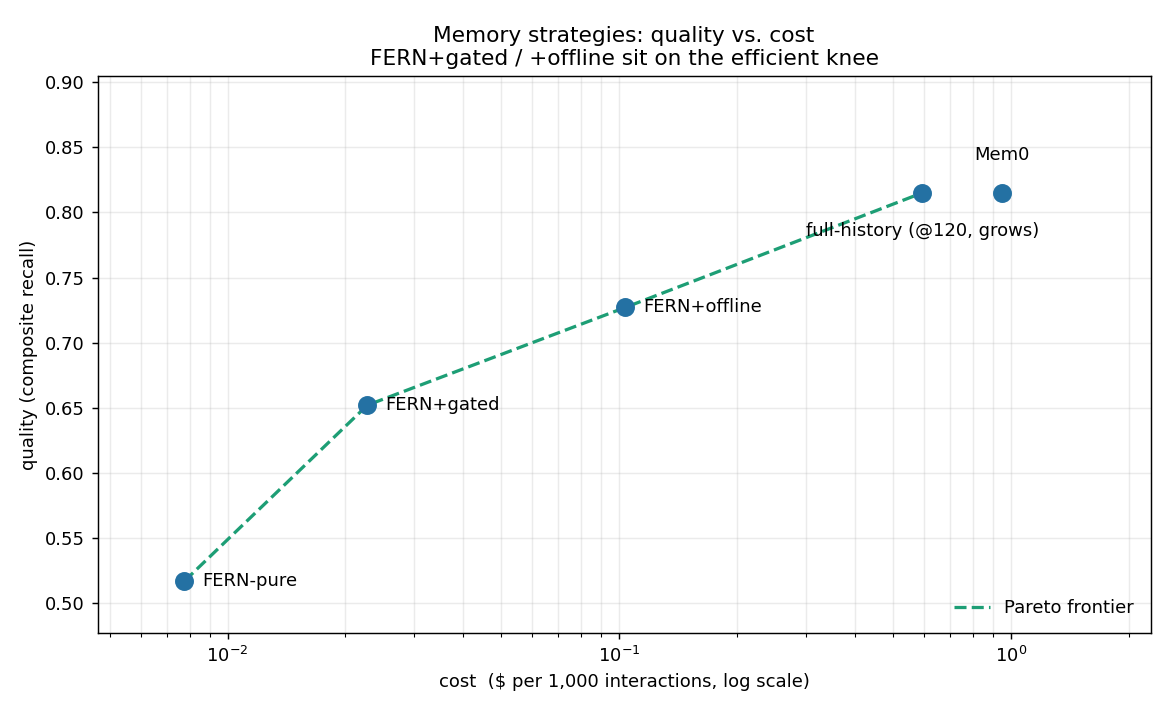
Cost / quality Pareto (python -m fernme.eval.pareto) — measured FERNme recall &
tokens, modeled LLM nuance & price (assumptions in-file). Per 1,000 interactions:
| strategy | quality | $/1k | vs Mem0 |
|---|---|---|---|
| FERNme-pure | 0.52 | $0.008 | 122× cheaper |
| FERNme+gated | 0.66 | $0.023 | 42× cheaper |
| FERNme+offline | 0.73 | $0.104 | 9× cheaper |
| full-history@120 | 0.82 | $0.59 (grows) | — |
| Mem0-style | 0.82 | $0.95 | 1× |
FERNme+gated/offline sit on the efficient knee: ~80–90% of the LLM-ceiling quality
at 1–2 orders of magnitude less cost. (Modeled assumptions; shape is the point.)
Simulated outcome pilot — fake storefront, learn-from-behavior shoppers: +16% relative conversion lift over a popularity baseline; tied at visit 1 (cold start), pulling ahead as it learns, recovering through a mid-pilot taste drift.
🎚 Memory modes (one engine, a cost/quality dial)
FERNme ships one core with a deployment-level switch — FernService(memory_mode=...).
The default is free, key-less, and tested; LLM modes are opt-in and pluggable.
| mode | LLM use | cost | status |
|---|---|---|---|
pure (default) |
none | cheapest, flat | ✅ tested, key-less |
gated |
one small call only on novel free-text | ~tiny | 🧪 experimental — needs a model |
offline |
batched consolidate() enrichment, off the hot path |
~tiny, amortized | 🧪 experimental — needs a model |
- A pluggable tagger (
tagging.py) does the LLM work; you passllm_fn, optionally
constrained to a controlled vocabulary (the real consistency lever across models). - The hot write path stays LLM-free in every mode; gated spends a call only when the
deterministic mapping finds nothing, andsvc.llm_callscounts every invocation for
cost transparency. - See the cost/quality Pareto above for where each mode lands. Honest note: the gated/
offline quality is modeled until run against a real model — the wiring is tested
here with a mock LLM, not validated for quality.
🧭 The 9 leapfrog dimensions (status)
FERNme's edge isn't the mechanism (that's now a crowded 2026 category) — it's competing
on dimensions single-user, vendor-owned, recall-optimized systems structurally can't.
| # | Dimension | Status |
|---|---|---|
| 9 | Communication-style & mood memory | ✅ built + tested |
| 2 | Outcome-learning for any goal (reinforce on results) | ✅ built + tested |
| 8 | Explainable provenance (why) |
✅ built + tested |
| 1 | Private collective priors (network-effect cold-start; k-anonymity + bounded-mean DP) | ✅ built + tested |
| 4 | Verifiable, cryptographic data ownership (tamper-evident HMAC chain, cascading unlearning) | ✅ built + tested |
| 7 | Multi-timescale memory (fast context vs. slow identity) | ✅ built + tested |
| 6 | Self-tuning forgetting (learn decay from outcomes; adapts to drift) | ✅ built + tested |
| 5 | Injection-resistant by construction (deterministic writes can't be talked into beliefs) | ✅ built + tested |
| 3 | Open user-owned memory protocol (portable across any agent, with consent) | ◑ spec stage |
These are deliberately the things HippoGraph et al. can't follow: they're single-user
(no collective priors), vendor-owned (no user-owned protocol), and recall-optimized
(no outcome loop). Built in honest, tested slices — research-dependent ones are marked.
🏗 Architecture
flowchart TD
V[Visitor on a website] -->|prompt + action| API[FERNme Service]
API --> CONSENT{consent?}
CONSENT -->|no| STOP[blocked]
CONSENT -->|yes| ENGINE
subgraph ENGINE[Engine - no LLM in the write path]
W[Hebbian write + decay] --> G[(Per-site preference graph<br/>fuzzy 0-9 edges)]
G --> R[Spreading-activation retrieval]
R --> CARD[Token-minimal card ~25 tok]
PRIOR[Population prior<br/>differential encoding] --> R
end
CARD --> AGENT[Agent: recommend / act]
G --> CAB[(Cabinet: raw event log)]
API --> STORE[(SQLite or Postgres<br/>multi-tenant)]
API --> GLASS[🪟 Glass-box editor]
API -.user signs in.-> SUPER[User-owned Supernode<br/>cross-site, default-deny]
🧠 How FERNme works (visual walkthrough)
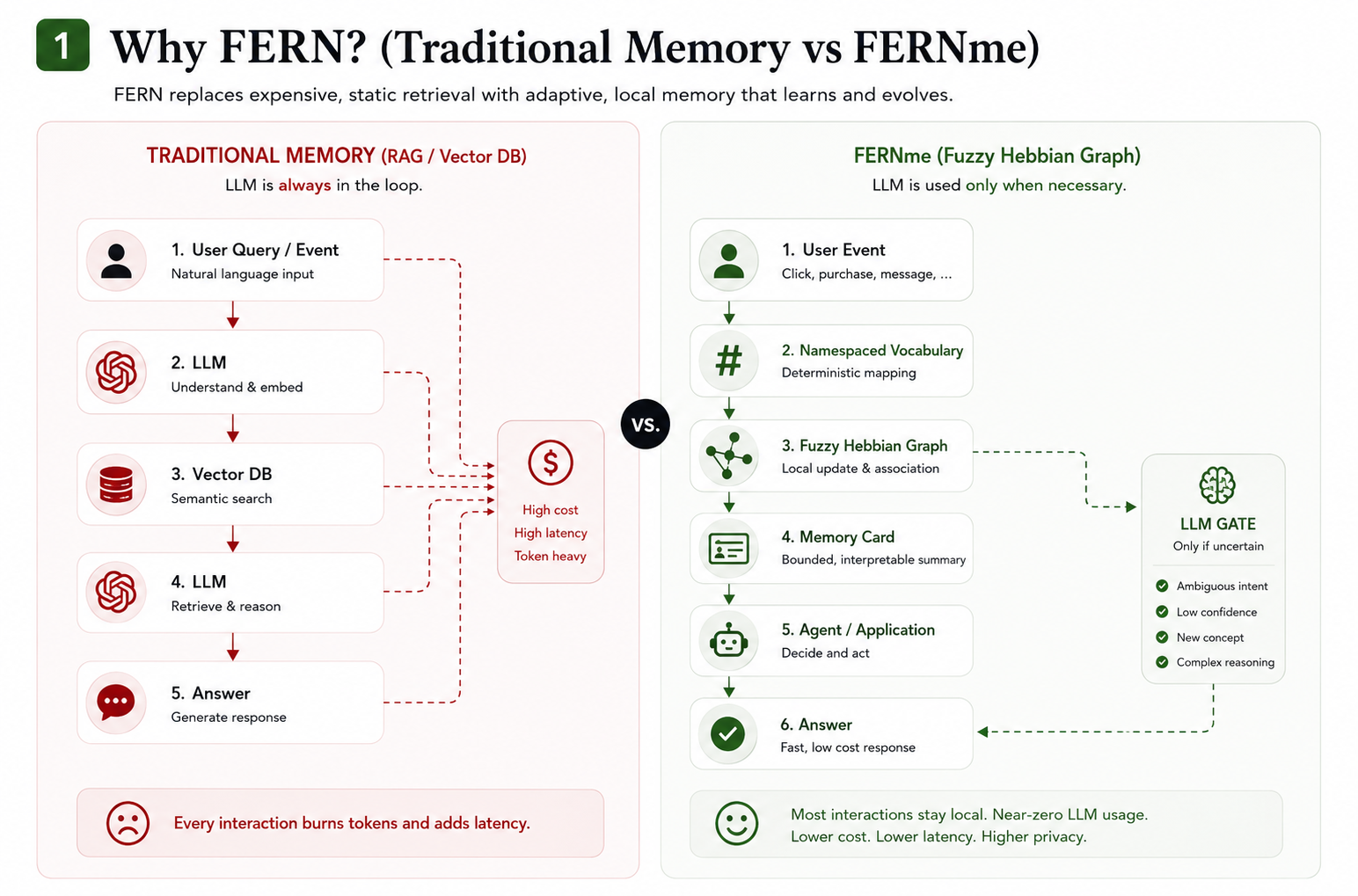
Why FERNme — adaptive local memory instead of expensive RAG/vector retrieval in the loop.
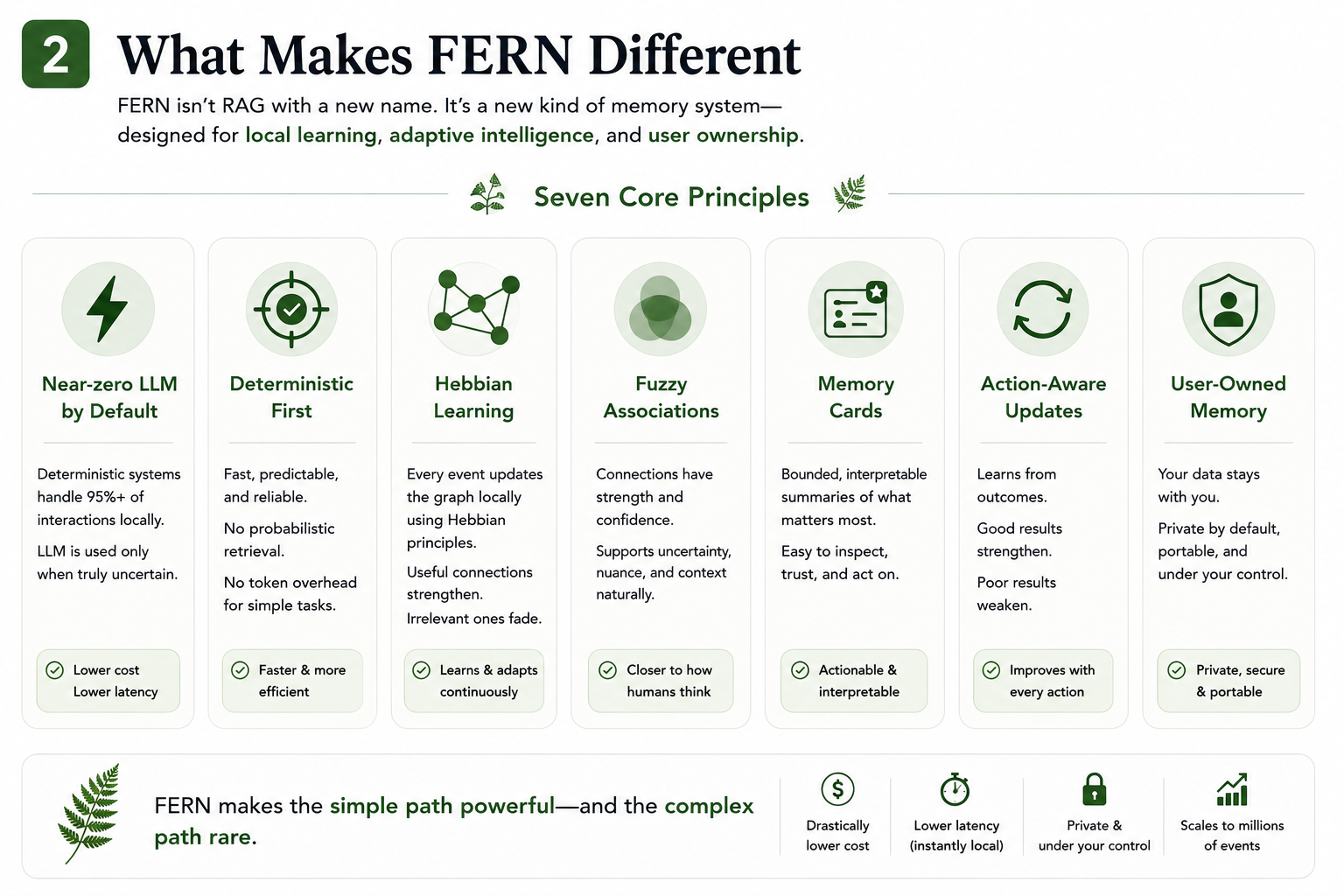
What makes it different — near-zero-LLM, deterministic-first, Hebbian, fuzzy, memory cards, action-aware, user-owned.
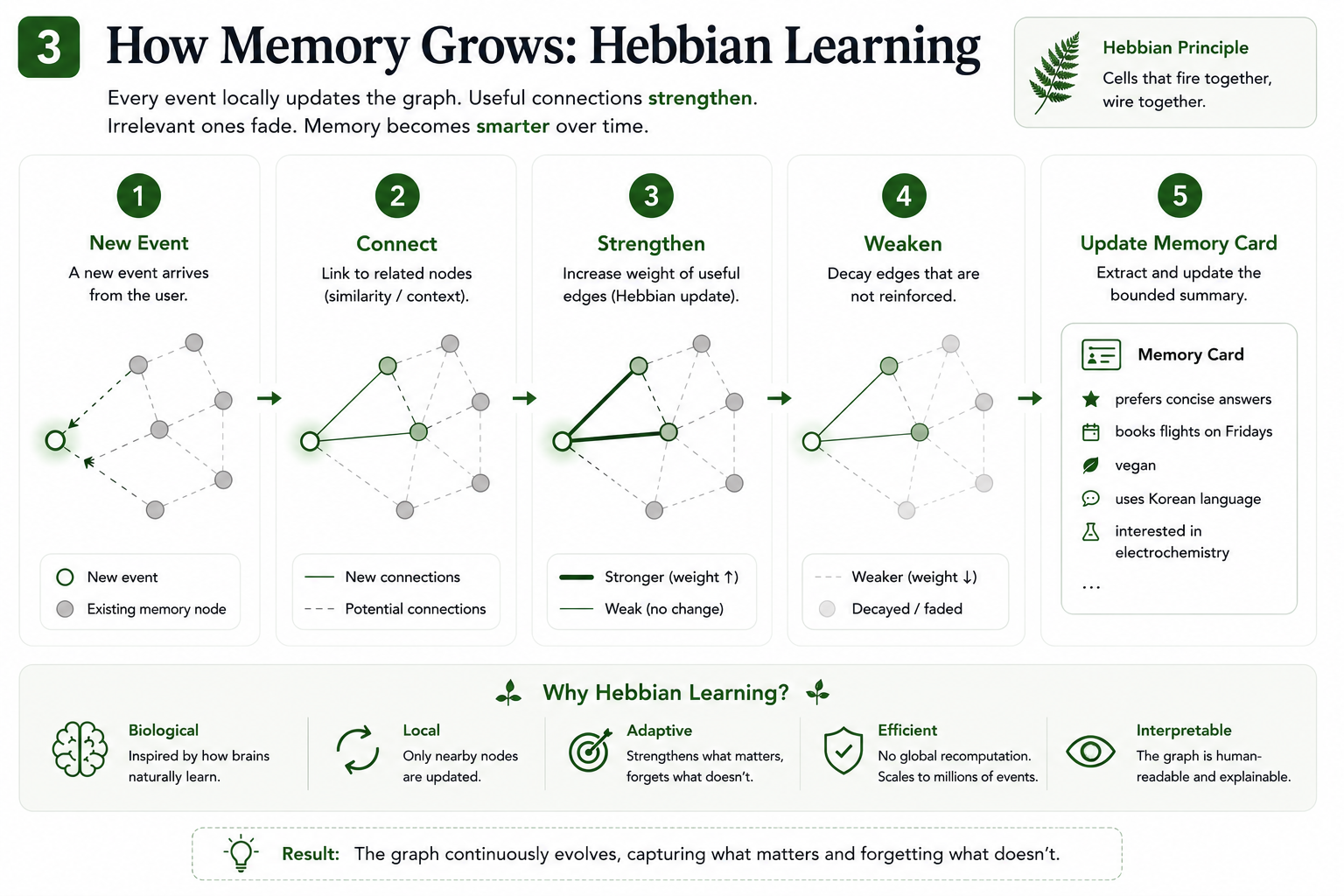
How memory grows — new event → connect → strengthen → decay → update the card (Hebbian learning).
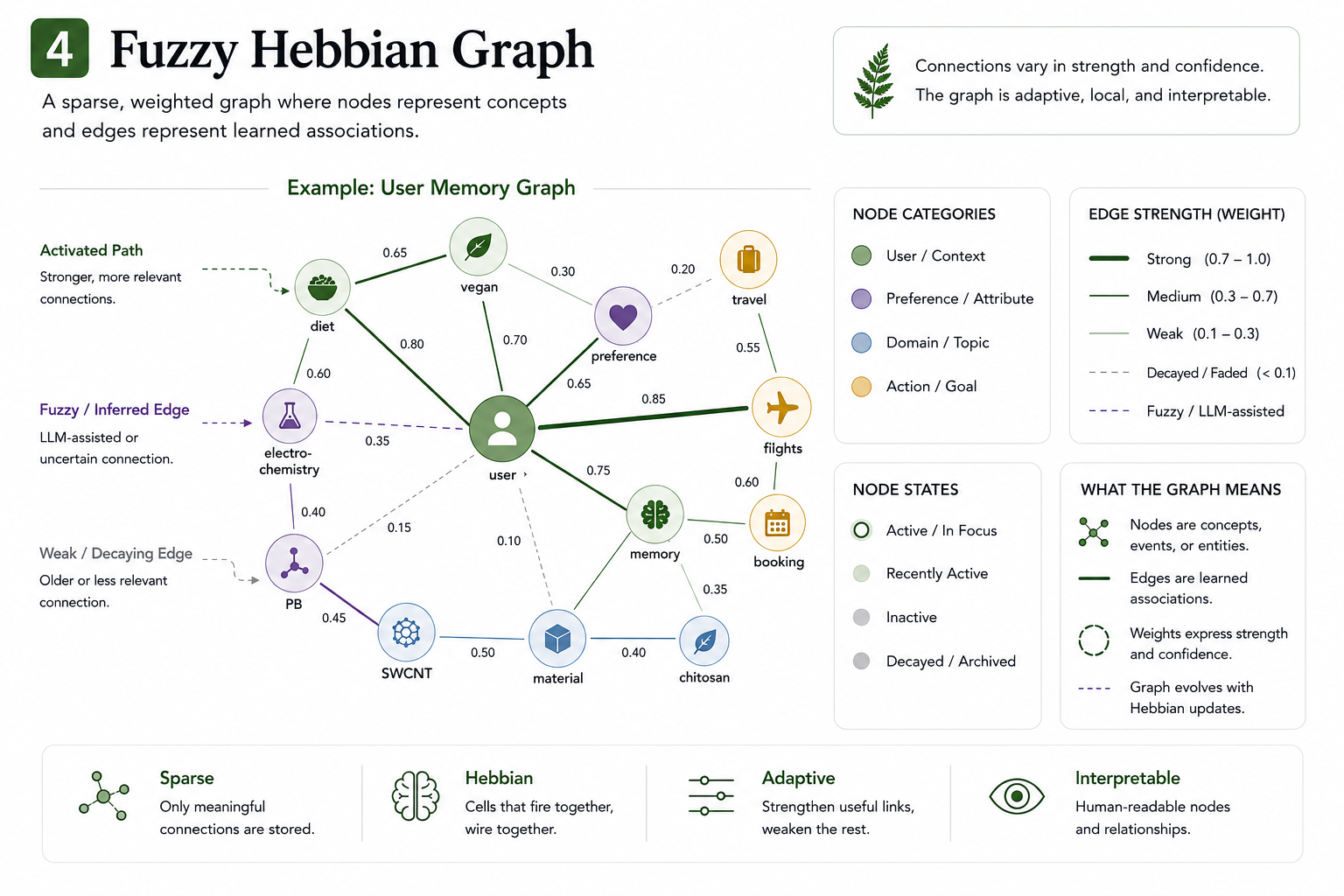
The fuzzy Hebbian graph — sparse, weighted (0–9) edges; nodes for users, preferences, topics, goals.
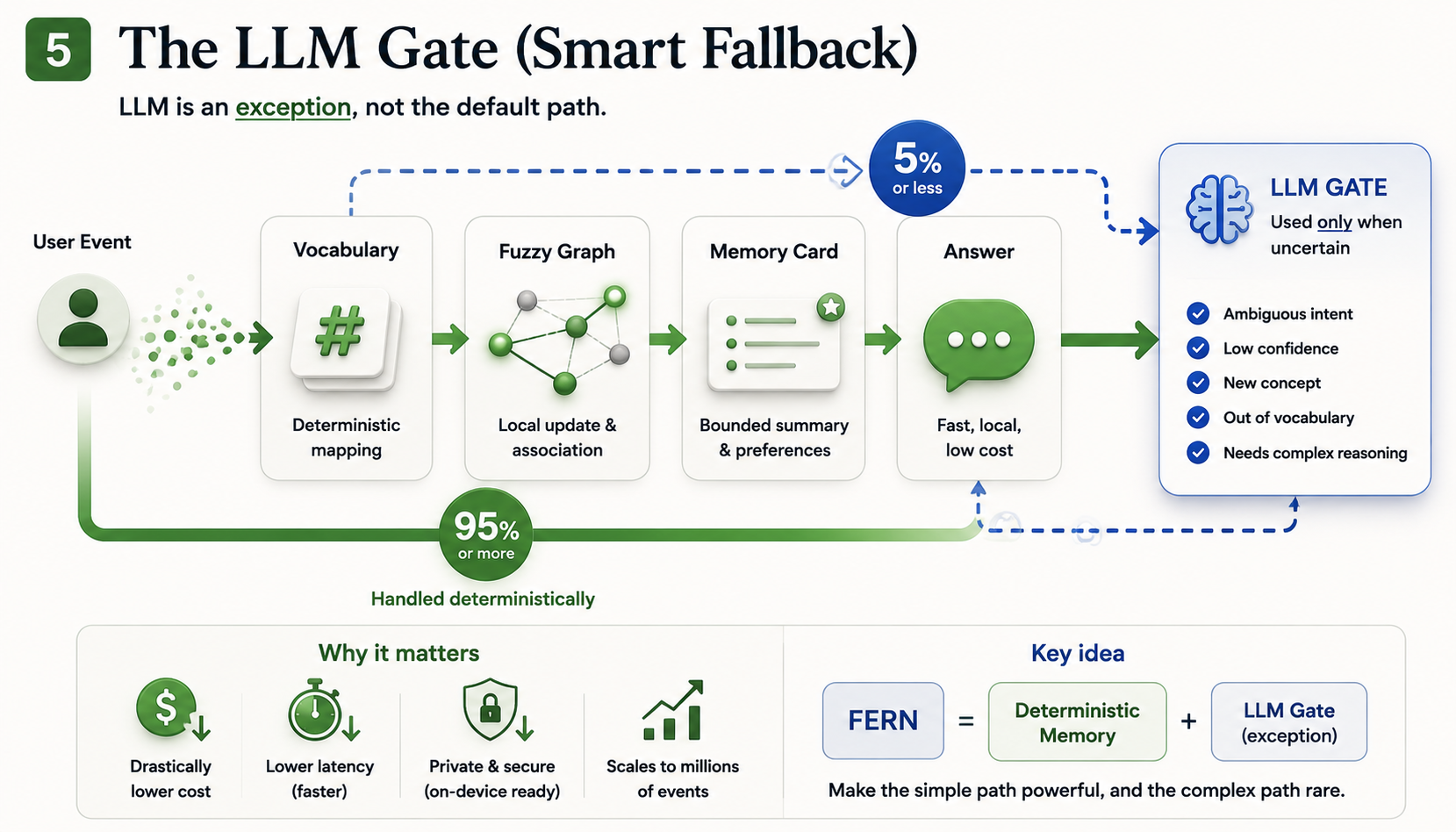
The LLM gate — an exception, not the default. Most events are handled deterministically; the LLM is a rare fallback when uncertain.

The memory card — a bounded, interpretable, token-minimal summary of what matters.
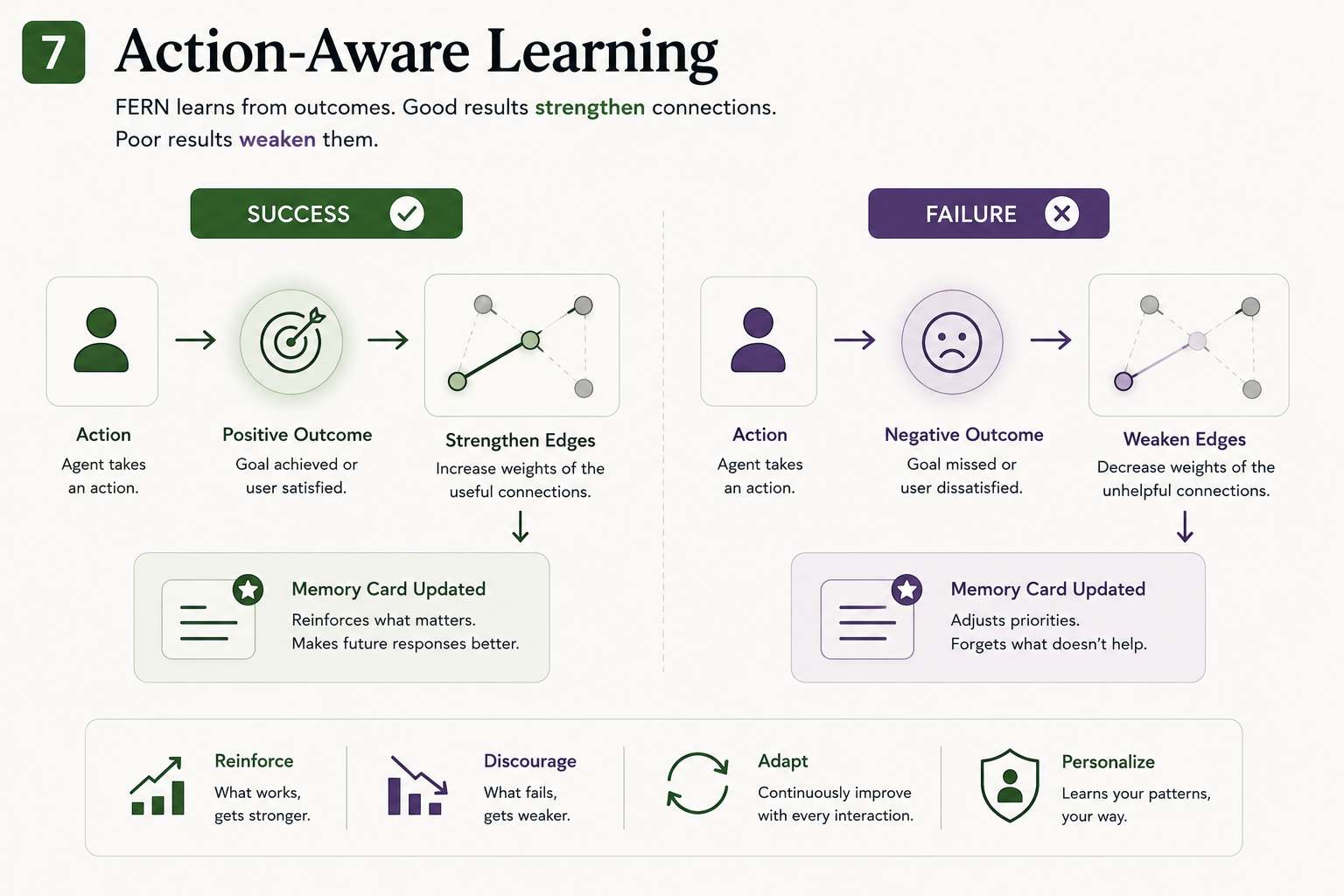
Action-aware learning — good outcomes strengthen connections, bad outcomes weaken them.
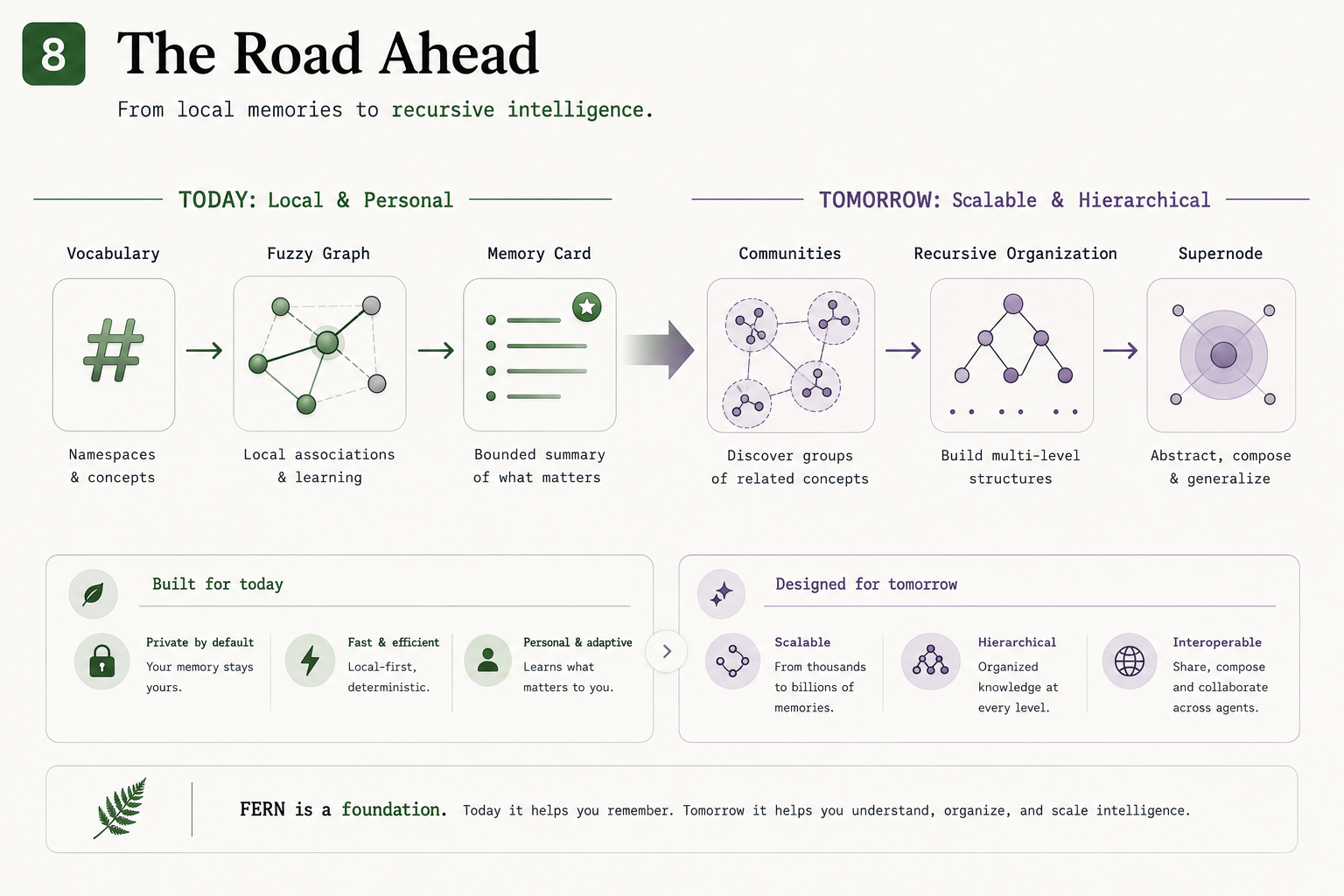
The road ahead — today's local memory; tomorrow's recursive organization and user-owned supernode (roadmap, not yet built).
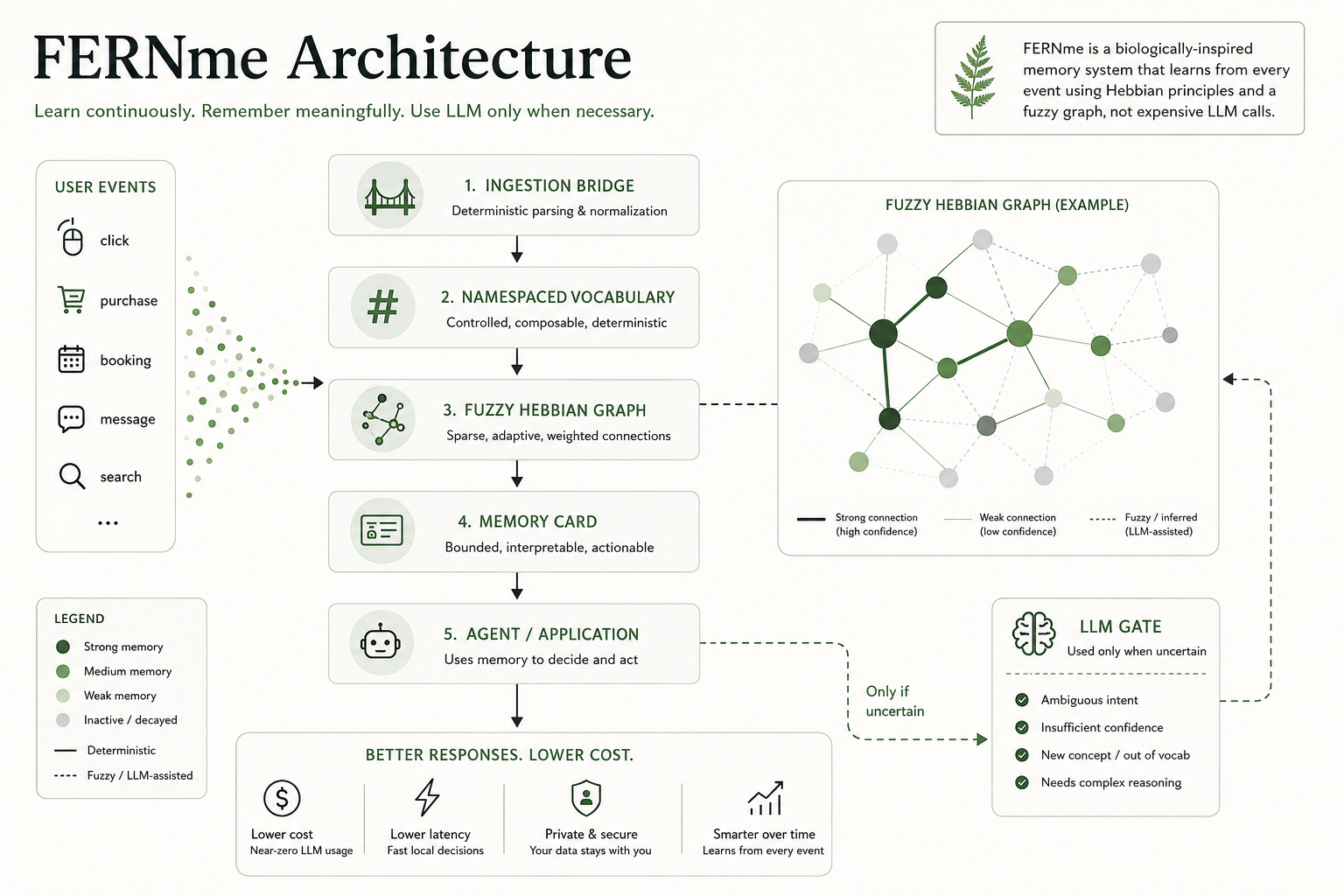
Full architecture: ingestion bridge → namespaced vocabulary → fuzzy Hebbian graph → memory card → agent, with the LLM gate only when uncertain.
🚀 Quickstart
pip install -e ".[dev,api]"
python run_demo.py # cold-start → learning → glass-box edit
python supernode_demo.py # one person, three sites, one owned profile
pytest -q # 91 tests (engine, store, supernode, safety, auth…)
# experiments
python -m fernme.eval.drift # FERNme beats a frequency counter when tastes change
python -m fernme.eval.pilot # +16% simulated conversion lift
# run it live
FERNME_API_KEY=secret uvicorn fernme.api.rest:app --port 8077 # REST API (docs at /docs)
open http://localhost:8077/ui # glass-box memory editor
open http://localhost:8077/graph # your memory as a graph — focus by site / PC / phone
python -m fernme.api.mcp_server # MCP server for agents/Claude
🗄 Storage: defaults to
~/.fernme/fernme.db(SQLite). For production usePostgresStore— same interface, tested against a real Postgres 16. Keep SQLite off cloud-synced folders.
🧱 What's inside
- Engine — saturating Hebbian write (no LLM), ACT-R decay, spreading activation, token-minimal card.
- Population prior — IDF cold-start; differential (deviation-only) storage is
enforced by an explicitprune_to_priorpass (redundant edges read through to the prior). - Stores —
SQLiteStore(zero-setup) andPostgresStore(tested vs real PG 16), one interface. - Ingestion bridge — a per-site catalog (item_id->tags) plus a controlled,
namespaced vocabulary (vocabulary.py) that canonicalizes every tag (catalog,
free text, or LLM) to one form (pref:,topic:,goal:,context:) so the same
concept never drifts across months. Deterministic by default; gated-LLM only for
novel free text. This is the product-critical layer — and the foundation a future
recursive/region organization would group on. - The Cabinet — append-only event log with
recall()for specific facts. - Supernode (
supernode.py+auth.py) — user-owned cross-site profile, built by sign-in (verified token → opaque person id), default-deny scoped views, sensitive categories walled off. - Proactive triggers — due-to-reorder + fading-favorite nudges.
- Safety — event tags treated as untrusted data: injection-pattern dropping, size/value caps.
- Interfaces — REST (
/observe /card /recall /edit /export /delete /triggers …) + MCP tools + a glass-box web UI (editor at/ui, cross-surface memory graph at/graph— one memory, focusable by site / PC / phone). - Governance — consent-gated everywhere; export & right-to-be-forgotten built in.
🔬 How FERNme compares
FERNme is a different category from conversational memories — it's a per-user preference graph evaluated by actions, not a QA memory. Don't benchmark it on LoCoMo; that's the wrong axis.
| 🌿 FERNme | Mem0 | Zep/Graphiti | Letta | MemOS | |
|---|---|---|---|---|---|
| Write | no LLM | LLM | LLM → KG | LLM-paged | LLM |
| Retrieval | spreading activation | vector | graph+time | OS paging | hybrid |
| Eval axis | outcomes | QA | temporal QA | long-horizon | QA |
| User-owned + glass-box | ✅ | – | – | – | – |
| Multi-tenant per-site | ✅ | passport | – | – | – |
Leads on: write cost, interpretability, per-site user-ownership/consent. Honestly behind on: nuanced/causal preferences (LLM extraction wins), benchmark credibility, ecosystem & distribution.
⚖️ Honest status
✅ Done & tested (91 tests): engine, SQLite + real-Postgres stores, supernode + sign-in, triggers, safety, REST/MCP, glass-box UI + memory-graph view, and the full results suite above.
🚧 Still open (genuinely needs the outside world):
- A real-human per-site pilot — only live users close the loop a simulator can't.
- The Mem0 (LLM) head-to-head — harness wired; run locally with
OPENAI_API_KEY. - Embeddings for context→attribute matching; offline LLM catalog enrichment for messy inputs.
- Desktop & mobile surfaces — the engine is substrate-agnostic; web ingestion ships today, desktop/mobile adapters are on the roadmap. The user-owned supernode is the bridge that assembles them, with consent, into one cross-surface profile.
Every claim above is backed by a test or a reproducible experiment. Where a result is simulated, it says so — a simulator proves the mechanism, not real-world behavior.
📁 Layout
fernme/
core/ graph types · fuzzy 0–9 edges · event record
write/ event→attr mapping (no LLM) · Hebbian update · decay
retrieve/ base-level + spreading activation · token-minimal card
prior/ population prior · differential encoding · IDF cold-start
store/ sqlite_store · postgres_store (one interface)
supernode.py · auth.py · triggers.py · safety.py · service.py
api/ rest.py (FastAPI) · mcp_server.py · web/glassbox.html · web/graph.html
eval/ simulator · cost · quality · drift · context · ablation · pilot
tests/ 91 tests · *_demo.py walkthroughs
📜 License & citation
Apache-2.0, © 2026 Acquilab Inc. — see LICENSE and NOTICE. Security notes in SECURITY.md; the name is a working codename (see NAMING.md).
If you use FERNme in research, please cite it via CITATION.cff.
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found