mnemon
Health Pass
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 125 GitHub stars
Code Fail
- execSync — Synchronous shell command execution in internal/setup/assets/openclaw/hooks/mnemon-prime/handler.js
- rm -rf — Recursive force deletion command in scripts/e2e_test.sh
Permissions Pass
- Permissions — No dangerous permissions requested
This tool provides persistent, cross-session memory for AI agents using a graph-based knowledge store. It acts as an MCP server that allows language models to remember, link, and recall information across different conversations without requiring extra API keys.
Security Assessment
The tool operates as a single binary handling deterministic storage and graph indexing, with no hardcoded secrets detected and no dangerous permissions requested. However, the automated scan flagged two code issues. First, there is synchronous shell command execution found within an OpenClaw handler script. Second, a recursive force deletion command (`rm -rf`) is present in an end-to-end test script. While the deletion command is standard for automated testing environments, executing synchronous shell commands in handlers can pose a security risk if the input is manipulable. Overall risk is rated as Medium.
Quality Assessment
The project demonstrates strong health and maintenance signals. It is licensed under the permissive MIT license, ensuring clear usage rights. The repository is highly active, with the most recent code push occurring just today. It also enjoys a solid foundation of community trust, currently backed by 125 GitHub stars.
Verdict
Use with caution — the tool is well-maintained and generally safe, but developers should review the synchronous shell execution handler before deploying in production.
LLM-supervised persistent memory for AI agents — graph-based recall, cross-session knowledge, single binary. Works with Claude Code, OpenClaw, and any CLI agent.
![]()
Mnemon
English | 中文
LLM-supervised persistent memory for AI agents.
![]()
![]()
LLM agents forget everything between sessions. Context compaction drops critical decisions, cross-session knowledge vanishes, and long conversations push early information out of the window.
Mnemon gives your agent persistent, cross-session memory — a four-graph knowledge store with intent-aware recall, importance decay, and automatic deduplication. Single binary, zero API keys, one setup command.
Claude Max / Pro subscriber? Mnemon works entirely through your existing subscription — no separate API key required. Your LLM subscription is the intelligence layer. Two commands and you're done.
Why Mnemon?
Most memory tools embed their own LLM inside the pipeline. Mnemon takes a different approach: your host LLM is the supervisor. The binary handles deterministic computation (storage, graph indexing, search, decay); the LLM makes judgment calls (what to remember, how to link, when to forget). No middleman, no extra inference cost.
| Pattern | LLM Role | Representative |
|---|---|---|
| LLM-Embedded | Executor inside the pipeline | Mem0, Letta |
| File Injection | None — reads file at session start | Claude Code Memory |
| MCP Server | Tool provider via MCP protocol | claude-mem |
| LLM-Supervised | External supervisor of a standalone binary | Mnemon |
Mnemon also addresses a gap in the protocol stack. MCP standardizes how LLMs discover and invoke tools. ODBC/JDBC standardizes how applications access databases. But how LLMs interact with databases using memory semantics — this layer has no protocol. Mnemon's three primitives — remember, link, recall — form an intent-native protocol: command names map to the LLM's cognitive vocabulary (remember not INSERT, recall not SELECT), and output is structured JSON with signal transparency rather than raw database rows.
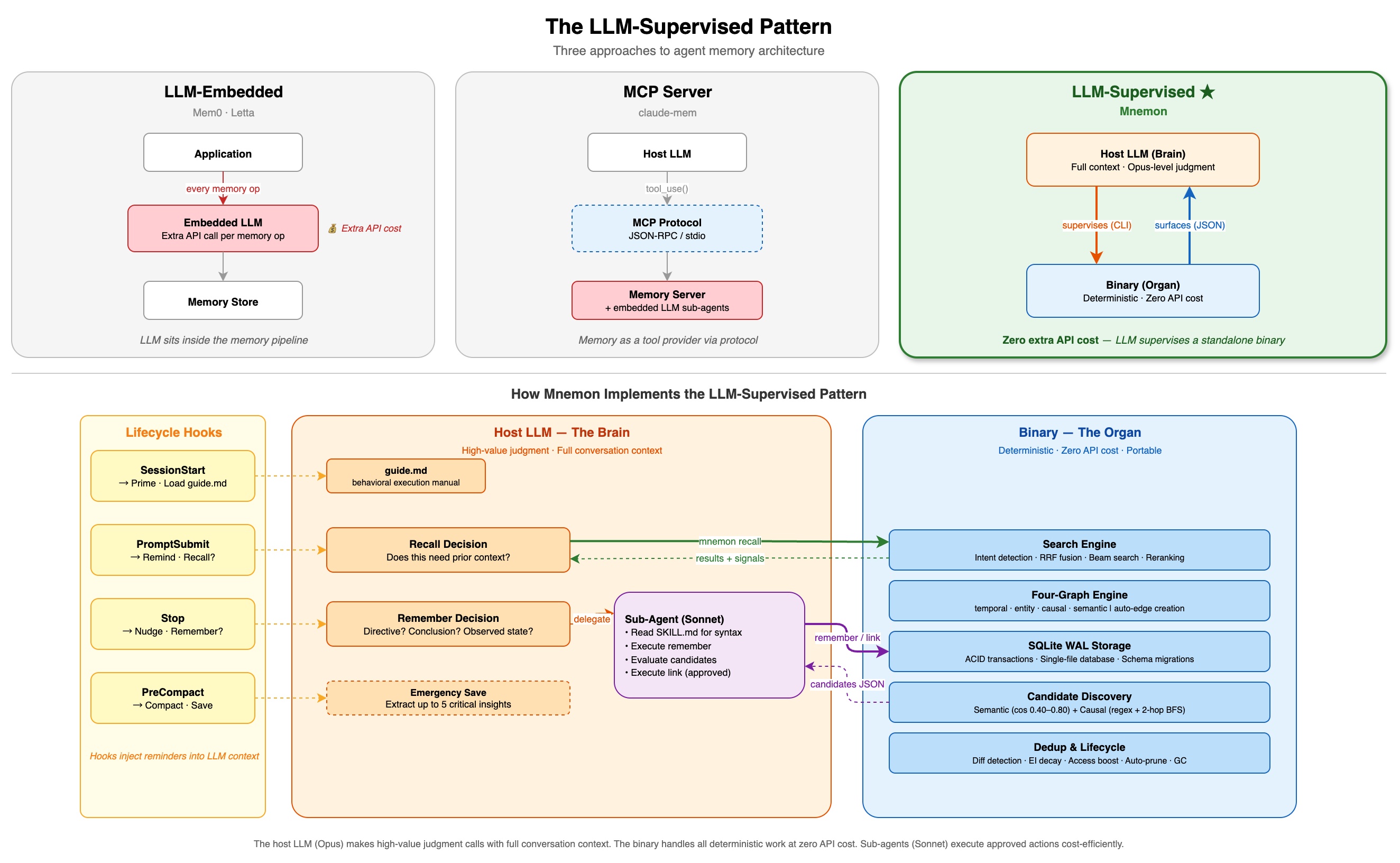
The LLM-Supervised pattern: hooks drive the lifecycle, the host LLM makes judgment calls, the binary handles deterministic computation.
Memory has a compound interest effect — the longer it accumulates, the greater its value. LLM engines iterate constantly, skill files cost nearly nothing to write, but memory is a private asset that grows with the user. It is the only component in the agent ecosystem worth deep investment.
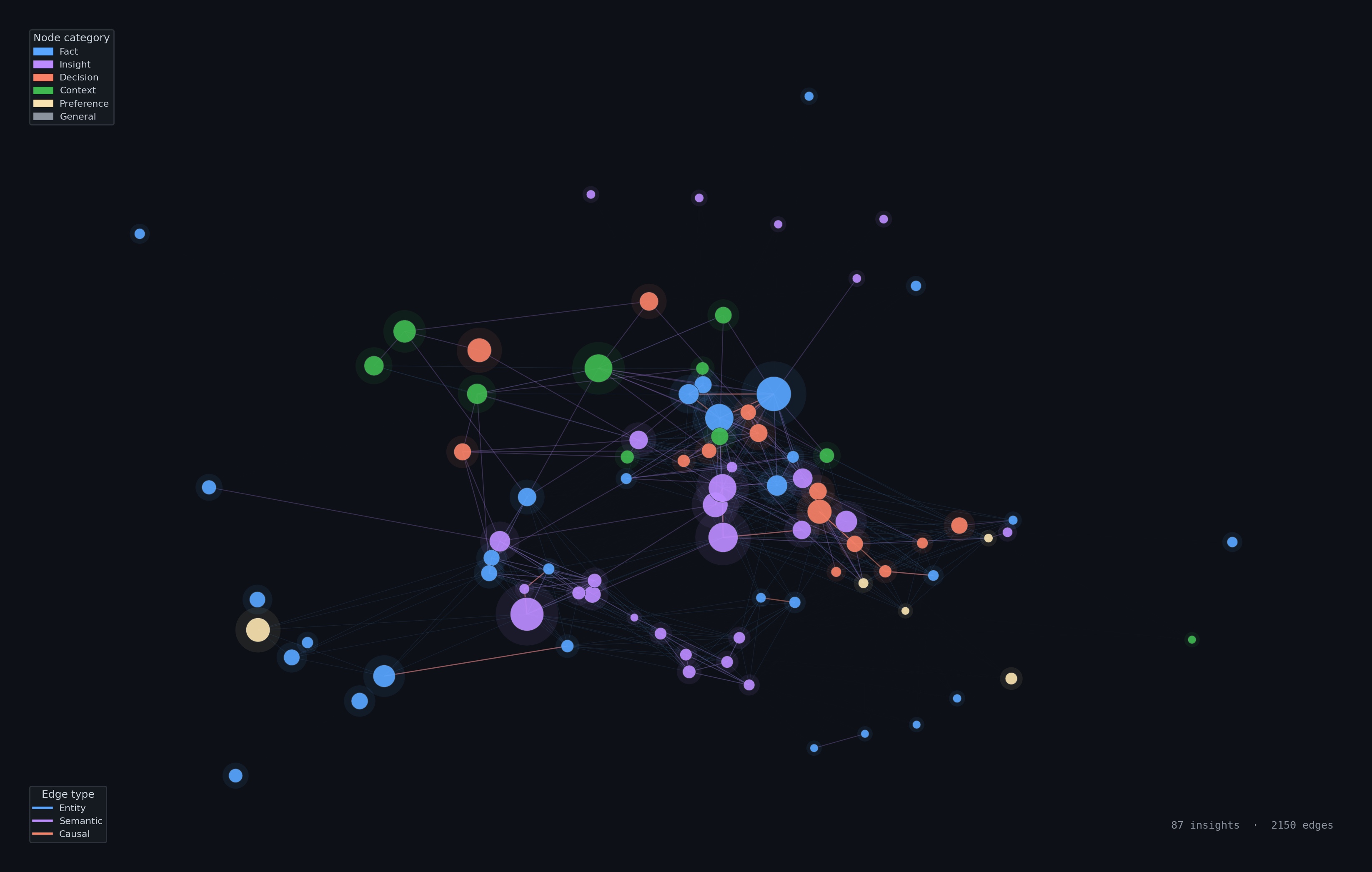
A real knowledge graph built by Mnemon — 87 insights, 2150 edges across four graph types.
See Design & Architecture for details.
Quick Start
Install
Homebrew (macOS / Linux):
brew install mnemon-dev/tap/mnemon
Go install:
go install github.com/mnemon-dev/mnemon@latest
From source:
git clone https://github.com/mnemon-dev/mnemon.git && cd mnemon
make install
Verify installation:
mnemon --version
Claude Code
mnemon setup
mnemon setup auto-detects Claude Code, then interactively deploys skill, hooks, and behavioral guide. Start a new session — memory just works.
OpenClaw
mnemon setup --target openclaw --yes
One command deploys skill, hook, plugin, and behavioral guide to ~/.openclaw/. Restart the OpenClaw gateway to activate.
NanoClaw
NanoClaw runs agents inside Linux containers. Use the /add-mnemon skill to integrate:
- Install mnemon on the host (see above)
- In your NanoClaw project, run
/add-mnemon— Claude Code will modify the Dockerfile, add a container skill, and set up volume mounts - Each WhatsApp group gets its own isolated memory store, with optional global shared memory (read-only)
The skill is available at .claude/skills/add-mnemon/ in the NanoClaw repo.
Uninstall
mnemon setup --eject
How it works
Once set up, memory operates transparently — you use your LLM CLI as usual. Mnemon integrates via Claude Code's hook system, injecting memory operations at key lifecycle points:
Session starts
│
▼
Prime (SessionStart) ─── prime.sh ──→ load guide.md (memory execution manual)
│
▼
User sends message
│
▼
Remind (UserPromptSubmit) ─── user_prompt.sh ──→ remind agent to recall & remember
│
▼
LLM generates response (guided by skill + guide.md rules)
│
▼
Nudge (Stop) ─── stop.sh ──→ remind agent to remember
│
▼
(when context compacts)
Compact (PreCompact) ─── compact.sh ──→ extract critical insights to remember
Four hooks drive the memory lifecycle. Prime loads the behavioral guide — a detailed execution manual for recall, remember, and sub-agent delegation. Remind prompts the agent to evaluate recall and remember before starting work. Nudge reminds the agent to consider remember after finishing work. Compact instructs the agent to extract and save critical insights before context compression. The skill file teaches command syntax. The guide (~/.mnemon/prompt/guide.md) defines the detailed rules for when to recall, what to remember, and how to delegate.
You don't run mnemon commands yourself. The agent does — driven by hooks and guided by the skill and behavioral guide.
Features
- Zero user-side operation — install once, memory runs in the background via hooks
- LLM-supervised — the host LLM decides what to remember, update, and forget; no embedded LLM, no API keys
- Hook-based integration — four lifecycle hooks: Prime (load guide), Remind (recall & remember), Nudge (remember), and Compact (save before compression)
- Four-graph architecture — temporal, entity, causal, and semantic edges, not just vector similarity
- Intent-native protocol — three primitives (
remember,link,recall) map to the LLM's cognitive vocabulary, not database syntax; structured JSON output with signal transparency - Intent-aware recall — graph traversal + optional vector search (RRF fusion), enabled by default for all queries
- Built-in deduplication —
rememberauto-detects duplicates and conflicts; skips or auto-replaces - Retention lifecycle — importance decay, access-count boosting, and garbage collection
- Optional embeddings — works fully without Ollama; add local Ollama for enhanced vector+keyword hybrid search
Vision
All your local agentic AIs — across sessions and frameworks — sharing one pool of live memory.
Claude Code ──┐
│
OpenClaw ─────┤
│
NanoClaw ─────┤
├──▶ ~/.mnemon ◀── shared memory
OpenCode ─────┤
│
Gemini CLI ───┘
The foundation is in place: a single ~/.mnemon database that any agent can read and write. Claude Code's hook integration is the reference implementation; OpenClaw uses a plugin-based approach; NanoClaw integrates via container skills and volume mounts. The same pattern can be replicated for any LLM CLI that supports event hooks or system prompts.
The longer-term direction is a memory gateway: protocol decoupled from storage engine. The current SQLite backend is the first adapter; the protocol surface (remember / link / recall) can sit on top of PostgreSQL, Neo4j, or any graph database. Agent-side optimization (when to recall, what to remember) and storage-side optimization (indexing, graph algorithms) evolve independently. See Future Direction for details.
FAQ
Do different sessions share memory?
Yes. By default, all sessions use the same default store — a decision remembered in one session is available in every future session.
Can I isolate memory per project or agent?
Yes. Use named stores to separate memory:
mnemon store create work # create a new store
mnemon store set work # set as default
MNEMON_STORE=work mnemon recall "query" # or use env var per-process
Different agents/processes can use different stores via the MNEMON_STORE environment variable — no global state contention.
Local or global mode?mnemon setup defaults to local (project-scoped .claude/), recommended for most users. Global (mnemon setup --global, installed to ~/.claude/) activates mnemon across all projects — convenient if you want other frameworks (e.g., OpenClaw) to share memory by forwarding requests through Claude Code CLI, but may add maintenance overhead.
How do I customize the behavior?
Edit ~/.mnemon/prompt/guide.md. This file controls when the agent recalls memories and what it considers worth remembering. The skill file (SKILL.md) is auto-deployed and should not need manual editing.
What is sub-agent delegation?
Memory writes don't happen in the main conversation. The host LLM (e.g., Opus) decides what to remember, then delegates the actual mnemon remember execution to a lightweight sub-agent (e.g., Sonnet). This saves tokens and keeps memory operations out of the main context.
Configuration
| Environment Variable | Default | Description |
|---|---|---|
MNEMON_DATA_DIR |
~/.mnemon |
Base data directory |
MNEMON_STORE |
(active file or default) |
Named memory store for data isolation |
Ollama-specific (only relevant if using embeddings):
| Environment Variable | Default | Description |
|---|---|---|
MNEMON_EMBED_ENDPOINT |
http://localhost:11434 |
Ollama API endpoint |
MNEMON_EMBED_MODEL |
nomic-embed-text |
Embedding model name |
Development
make build # build binary
make install # build + install to $GOBIN
make test # run E2E test suite
mnemon setup # interactive setup
mnemon setup --eject # remove all integrations
make help # show all targets
Dependencies: Go 1.24+, modernc.org/sqlite, spf13/cobra, google/uuid
Documentation
- Design & Architecture — philosophy, algorithms, integration design
- Usage & Reference — CLI commands, embedding support, architecture overview
- Architecture Diagrams — system architecture, pipelines, lifecycle management
References
Mnemon combines the paradigm of one paper with the methodology of another, grounded in the structural insight that graph memory is isomorphic to LLM attention. See Theoretical Foundations for details.
- RLM — Zhang, Kraska & Khattab. Recursive Language Models. 2025. Establishes the paradigm: LLMs are more effective as orchestrators of external environments than as direct data processors.
- MAGMA — Zou et al. A Multi-Graph based Agentic Memory Architecture. 2025. Provides the methodology: four-graph model (temporal, entity, causal, semantic) with intent-adaptive retrieval.
- Graph-LLM Structural Insight — Joshi & Zhu. Building Powerful GNNs from Transformers. 2025; and the Graph-based Agent Memory survey (Chang Yang et al., 2026). Confirms that LLM attention is computationally equivalent to GNN operations — graph memory is a structural match, not an engineering convenience.
License
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found