harness-eval
Health Warn
- No license — Repository has no license file
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 5 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
Eval framework that ranks agentic coding frameworks (Superpowers, Compound Engineering, Agent Skills, GSD) by having each build the same spec with the same harness+model in isolated sandboxes, graded on a weighted evidence-based rubric: PRD adherence, code quality, speed, token spend
harness-eval
An evaluation framework that definitively ranks agentic coding frameworks by
having each one build the same product from the same spec, with the same
harness and model, in isolated sandboxes — then grading every artifact on a
weighted, evidence-based rubric.
First question answered: which of Superpowers, Compound Engineering,
Agent Skills, and GSD builds the best implementation of the
Symphony Service Specification (an
issue-tracker-driven orchestration daemon) when driven by Claude Code +
Opus 4.6? The architecture deliberately holds every other variable fixed so
the framework is the only thing being measured — and swaps cleanly for phase
2 (other harnesses like OpenCode/Codex, other models like GLM via z.ai).
Status
Built (merged or in review) — each capability was specified underopenspec/changes/
before implementation:
- Core harness — candidate registry, orchestration with isolation +
budgets + provenance, headless build sessions, two-instrument grading
(evidence-based evaluator + blind code-quality judge), telemetry, andresults.json+scorecard.md. (setup-harness-eval-framework) - Results dashboard — cross-run leaderboard, per-run scorecards, trial
drill-downs with evidence, and live re-weighting. (add-results-dashboard) - PRD library + bring-your-own-PRD — a target abstraction spanning several
product shapes (symphony-daemon,cli-tool, plusrest-apiandweb-app
adapted from ViBench), aninit --target … --specscaffolder, and
freeze/attribution rules. (add-prd-library) - Pluggable models — a model-profile registry, worker/judge resolution,
GLM via z.ai validated end-to-end, amodel probeconnectivity check,
and cross-vendor-judge + cost-basis caveats in results/scorecards.
(add-pluggable-models) - Pluggable providers/harnesses — Docker, E2B, macOS Virtualization, and
worktree providers share the same sandbox contract; harness registry entries
are validated per implemented driver. See
docs/HARNESS-ONBOARDING.md.
In review on branches: the Eval Studio web UI (review + configure on
shadcn/ui — this branch). Not yet built: a language-effectiveness
evaluation mode. See
ROADMAP.md.
How it works
registry (pinned frameworks) ──┐
eval target (PRD + test plan) ─┼─▶ orchestrator ─▶ per-trial sandbox ─▶ headless build session(s)
run config (budgets, weights) ─┘ │ │
▼ ▼
provenance + telemetry archived workspace + transcripts
│ │
└────────────▶ grading ◀────────────┘
evaluator (test plan, evidence)
+ blind judge (code quality)
│
▼
results.json ─▶ scorecard.md + web dashboard
- Candidate registry (
config/registry.yaml) — each framework under
test is declared with version-pinned install commands, its prescribed
session script (e.g. GSD's/gsd-new-projectphases vs Superpowers' single
prompt), and a content-free continuation allowlist. Fairness rules are
enforced: every candidate gets the identical rendered base prompt; only
framework-prescribed command wrappers differ. - Eval targets (
targets/<name>/) — a target couples a PRD, a frozen
weighted test plan derived from it (content-hashed at run start; fatal
cold-start gates; optional bonus steps), and any fixtures the evaluator
needs (e.g. a mock Linear GraphQL API and a stub Codex app-server for the
Symphony daemon). Bring your own spec: see
docs/BRING-YOUR-OWN-PRD.md. - Isolation providers — every trial runs in a fresh environment behind
oneSandboxProviderinterface: Daytona and E2B for cloud runs,
Docker and macOS Virtualization for local container/VM runs, and
git worktrees as a zero-dependency local fallback. Container/VM
providers share one pinned trial image (infra/trial-image/Dockerfile:
Node 22, Bun, Claude Code at an exact version) and preflight before any
spend or long-running work (image present, tier lifetime caps, daemon
health). - Build phase — the orchestrator drives Claude Code headless
(claude -p, stream-JSON) through the candidate's session script, with
per-trial wall-clock/cost caps, generic continuation handling at approval
gates, infra-vs-candidate failure classification (infra retries with
backoff; candidate failures are graded as-is), and full provenance
(versions, hashes, snapshot IDs) at every terminal state. Telemetry comes
from the harness's own session JSON: duration, token breakdown, cost,
turns. Workspaces and transcripts are archived (with secret redaction)
before sandbox teardown. - Grading phase — two independent instruments:
- An evaluator agent executes the frozen test plan against the built,
running artifact (cold-start fromsetup.sh/start.sh, driven against
the target's mock services), recording pass/partial/fail with cited
evidence per step. It is forbidden from repairing the artifact. - A blind code-quality judge scores five criteria (tests,
architecture, error handling, dead code, docs) 0–10, three samples each
with medians, on a copy scrubbed of framework-identifying files so it
cannot anchor on which framework produced the code. The judge model is
pinned and never the worker model. - Both run on your Claude subscription via headless Claude Code (default)
or the Anthropic SDK (--driver sdk).
- An evaluator agent executes the frozen test plan against the built,
- Reporting —
results.json(stable schema) +scorecard.mdper run,
cross-run combination viascripts/combined-report.ts, and the web
dashboard. Composite weights are config, recomputable at report time
without re-running anything.
What the scores mean
- Composite — weighted sum using the slider weights, recomputed live
- PRD adherence — Graded Score 0–100, ViBench methodology: evaluator
agent executes the frozen spec-derived test plan against the built,
running artifact with per-step evidence; weighted partial credit; fatal
cold-start failures zero the rest; absolute scale - Code quality — blind LLM judge: five criteria × 3 samples each on a
framework-marker-scrubbed copy, per-criterion medians averaged; absolute
scale - Speed* — agent working time (setup/grading excluded), min-max
normalized within this run — fastest 100, slowest 0, explicitly flagged as
not comparable across runs - Token spend* — total session cost, same within-run normalization
- ±σ and Trials — variance behind the inconclusive flag, and
right-censoring semantics
Default weights: PRD adherence 40%, code quality 25%, speed 17.5%, token
spend 17.5% — adherence dominates because a fast, cheap implementation of
the wrong thing is worthless. Rankings whose top-two composite ranges
overlap are flagged inconclusive.
Quick start
bun install
cp .env.example .env # add the keys for the providers you use
bun run src/cli.ts validate # registry + target + fixtures
bun run src/cli.ts run \
--candidates superpowers --trials 1 \
--provider worktree # one smoke trial (worktree = zero-dependency local)
bun scripts/grade-trial.ts runs/<run-dir> superpowers-t1 --driver cc
bun run src/cli.ts report runs/<run-dir> # (re)generate results + scorecard
bun run src/cli.ts report runs/<run-dir> --weights 0.5,0.35,0.075,0.075
Build the local trial image once: docker build -t harness-eval-trial:2.1.170-1 infra/trial-image/.
Provider setup guides: docs/MACOS-VZ-SETUP.md,infra/e2b-template/README.md, infra/daytona-snapshot notes in the
Dockerfile header. Harness/provider onboarding:
docs/HARNESS-ONBOARDING.md. Cloud
(laptop-free) runs: infra/run-all-cloud.sh pattern —
orchestrator-in-a-sandbox.
Results dashboard
bun run dashboard # http://127.0.0.1:4870 (localhost-only, read-only)
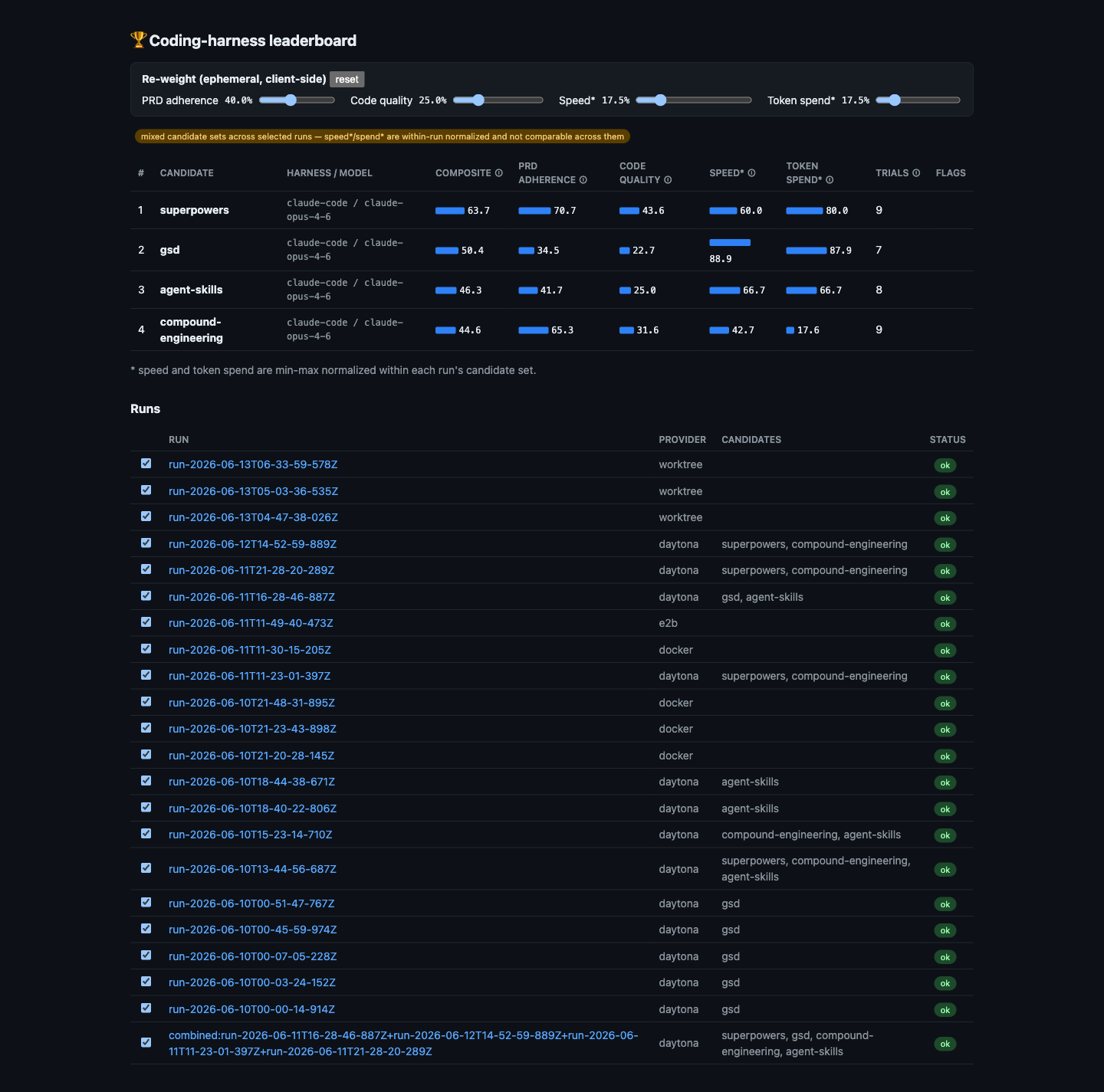
Leaderboard across runs (filter by run; speed/spend flagged as within-run
normalized), per-run scorecards with variance and exclusions, trial
drill-downs (every test-plan step with evidence, judge samples with
justifications, telemetry), a step-comparison matrix with hover tooltips
(what each step tests; why partial credit was docked), info icons explaining
every scoring column, and live re-weighting sliders that recompute
composites client-side via the same scoring module the CLI uses. Runs with
unknown results schema versions are listed with a regenerate hint instead of
rendering.
Eval Studio (shadcn/ui)
bun run studio # http://127.0.0.1:4871 (localhost-only)
A richer web UI on shadcn/ui that adds run
configuration to review: pick target × frameworks × harness × worker-model ×
provider from the live registries, with validation that mirrors the CLI exactly
and a copyable run command + budget envelope; plus the full review experience
(leaderboard, scorecards, trial drill-downs) reusing the same scoring module.
Themed from a single DESIGN.md token spec. See
docs/EVAL-STUDIO.md. (In review; supersedes the dashboard
once it reaches launch parity.)
Specific features
- Frozen, hash-bound grading: PRD and test plan content hashes are
recorded per run; drift fails loudly. The Symphony plan maps every §18.1
REQUIRED conformance item to ≥1 step, validated programmatically. - Evidence-or-it-didn't-happen: every adherence verdict cites commands
run and output observed; every judge score carries a written justification
and all raw samples. - Fairness engineering: identical prompts, version-pinned frameworks
(with post-install asserts that fail on upstream drift), blind judging,
judge ≠ worker model, per-trial state isolation verified by contamination
tests. - Fail-before-spend: provider preflights, model/credential probes, and
budget ceilings (per-trial wall-clock + cost, per-run total) withcapped
rather than silent truncation. - Crash resilience: per-step evaluator checkpoints and per-criterion
judge checkpoints — billing or network failures resume instead of losing
paid work. - Subscription-billed grading: graders run on headless Claude Code with
a Max-plan OAuth token by default; no API credits required. - Pluggable LLM models: a model-profile registry drives the worker (and
judge) model from config; GLM via z.ai is implemented and validated
end-to-end through Claude Code's Anthropic-compatible endpoint, with
cross-vendor-judge and cost-basis caveats recorded. Kimi/MiniMax/Qwen are
config-only additions on the roadmap. - OpenSpec-driven development: every capability is specified before
implementation underopenspec/(proposal → design → spec deltas → tasks);
see ROADMAP.md for what's specified but not yet built.
Project layout
config/ registry, run defaults
targets/ eval targets: PRD + frozen test plan + fixtures per product shape
src/ orchestrator, providers, drivers, grading, dashboard, CLI
scripts/ grade-trial, combined-report
infra/ trial image (shared by all providers), cloud orchestrator script
runs/ run artifacts (gitignored): workspaces, transcripts, grades, scorecards
docs/ leaderboards, retrospective, setup guides
openspec/ specs and change proposals
Built with Bun; created with bun init (bun v1.3.8).
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found