Auteur
Health Uyari
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 6 GitHub stars
Code Basarisiz
- exec() — Shell command execution in backend/scripts/export-demo-fixtures.py
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
🎬 16-role AI film studio · End-to-end short video pipeline · Multi-agent · Self-hosted
🎬 Auteur
一个由 16 位 AI 角色组成的剧组,端到端自动化生产中文短视频
一句话发起 → 选题、编剧、分镜、生图、配音、配乐、剪辑、复盘 全部跑完 → 落地 MP4
![]()
English | 中文
🎮 在线 Demo · 点这里直接玩 →
基于真实流水线产出的「今天体验的人生副本:偷外卖的人的一生」打包成可点击演示,30 秒看完整剧组协作 + 自动剪辑 + 数据复盘全流程,无需安装。
✨ Auteur 是什么?
Auteur 把"做一条短视频"拆成一个完整的虚拟剧组——不是一串 prompt,是一个有分工、有审稿、有反馈、有数据复盘的生产体系。
🎯 选题策划 → 📝 编剧(+🔍 自审 +📚 史实核查) → 🎙️ 配音演员
↓
🎬 摄影指导(+🎬 自审)→ 🎨 美术指导(+🖼️ 审片官)→ 🎵 作曲 → 🖼️ 封面 → 🎞️ 制片合成
↓
📊 数据分析师 ← 🌐 浏览器扩展(抖音 / B 站 / 视频号 / 快手 数据回写)
↓
反哺下一轮 🎯 选题脑暴
给一个主题,按一下生成,剧组就把流水线跑完——脚本、字幕、分镜、生图、配音、BGM、封面、合成视频,全部落库可追溯,每一步都可中断、人工介入、单独重做。
🚀 三个让人想 star 的特点
1️⃣ 16 位 AI 角色协作,不是 prompt 链
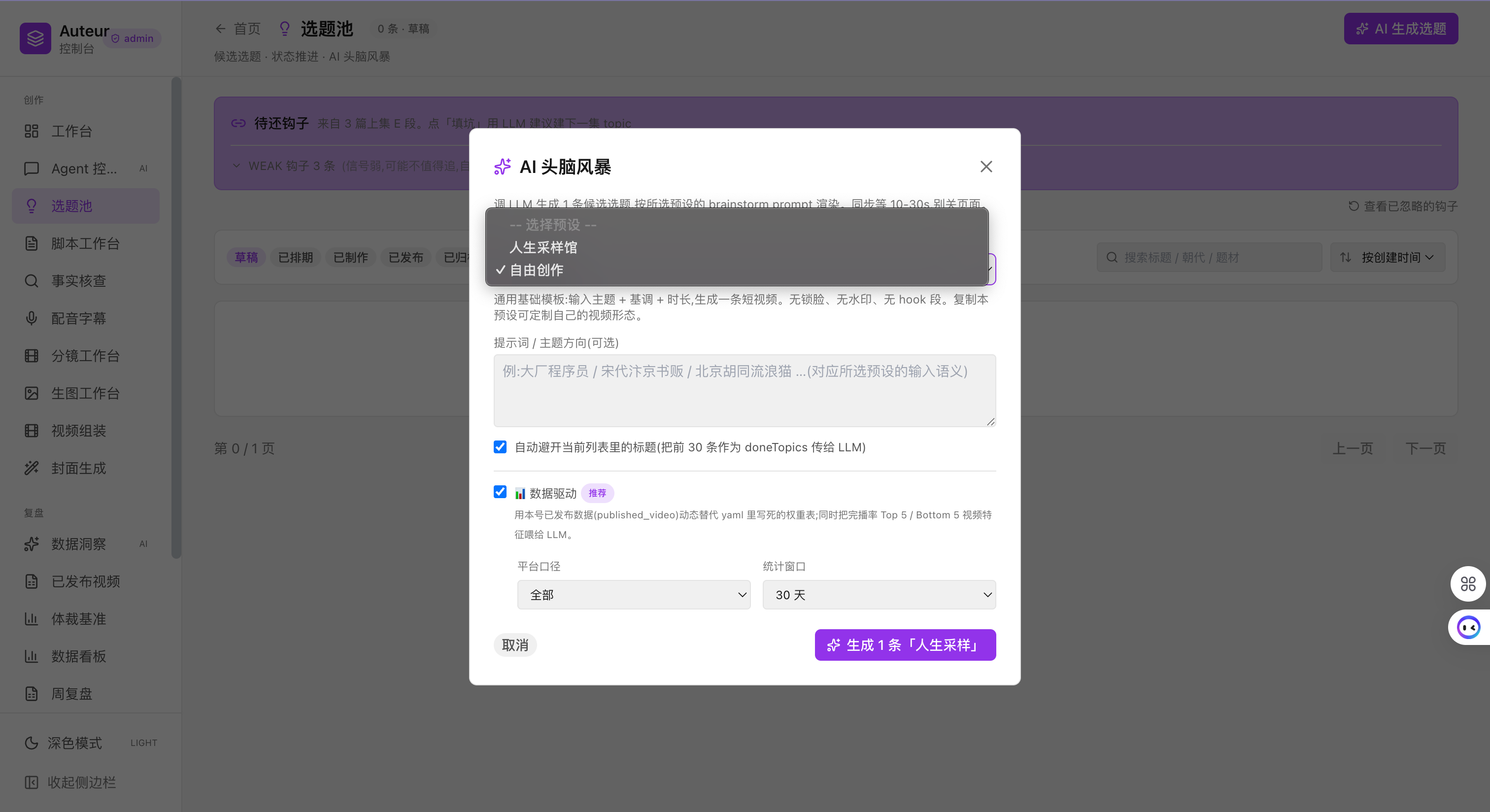
AI 头脑风暴工作台:多角色 + 历史数据 + 系列脉络共同生成选题候选
业内常见做法是把 LLM 的 prompt 串成一条链——一个出错全盘重跑,中间产物看不到摸不着。
Auteur 不一样:每个角色都是一个独立的 Spring Service,有自己的 prompt 模板、自己的 LLM 调用与重试策略、自己的 DB 产物表。
| 类别 | 角色 | 干什么 |
|---|---|---|
| 创意层 | 🎯 选题策划 | 基于历史数据 + 系列脉络给 5–10 个候选,按题材/钩子打分 |
| 📝 编剧 | 拆多段叙事结构,高分走旗舰模型,普通走批量便宜模型 | |
| 🔍 编剧自审 | LLM 自审打分,低于阈值把审稿意见塞回去重写一稿 | |
| 📚 史实核查 | 抽脚本中的事实声明,逐条验证,给修复建议或自动改写 | |
| 🪝 钩子分析师 | 反向提取"下集预告"作为下期种子(系列连续性) | |
| 视觉层 | 🎬 摄影指导 | 拆 20–28 个分镜,可选 PRECISE_BY_CUE 模式按 SRT 逐字锚定 |
| 🎬 摄影自审 | 校验景别多样性、特写比例、anchor 命中率等硬指标 | |
| 🎨 美术指导 | 批量出图,并发限速 + 失败重试 + 锁脸 reference 注入 | |
| 🖼️ 审片官 | 出图后自动检查:构图 / 手部 / 水印 / 锁脸一致性 | |
| 🖼️ 封面设计 | 抽脚本要点出多版封面,含品牌识别 | |
| 声音层 | 🎙️ 配音演员 | 火山豆包 TTS 合成 narration + SRT,回写真实音频时长 |
| 🎵 作曲选曲 | LLM 打 mood 标签 → Jamendo CC 协议曲库选曲 → 锁定 | |
| 统筹层 | 🎬 总导演 | 跨角色的视觉风格 + 叙事弧线 + 关键节拍中央笔记,所有人都读 |
| 🎞️ 制片 | SRT → ShotTimingResolver → ImageClip 拼接 → ffmpeg/Remotion 渲染 | |
| 复盘层 | 📊 数据分析师 | 拉浏览器扩展回写的真实播放数据,做完播率/钩子归因/周复盘 |
| 🧭 系列规划 | 把上一期 hook 转成下一期 topic 种子 |
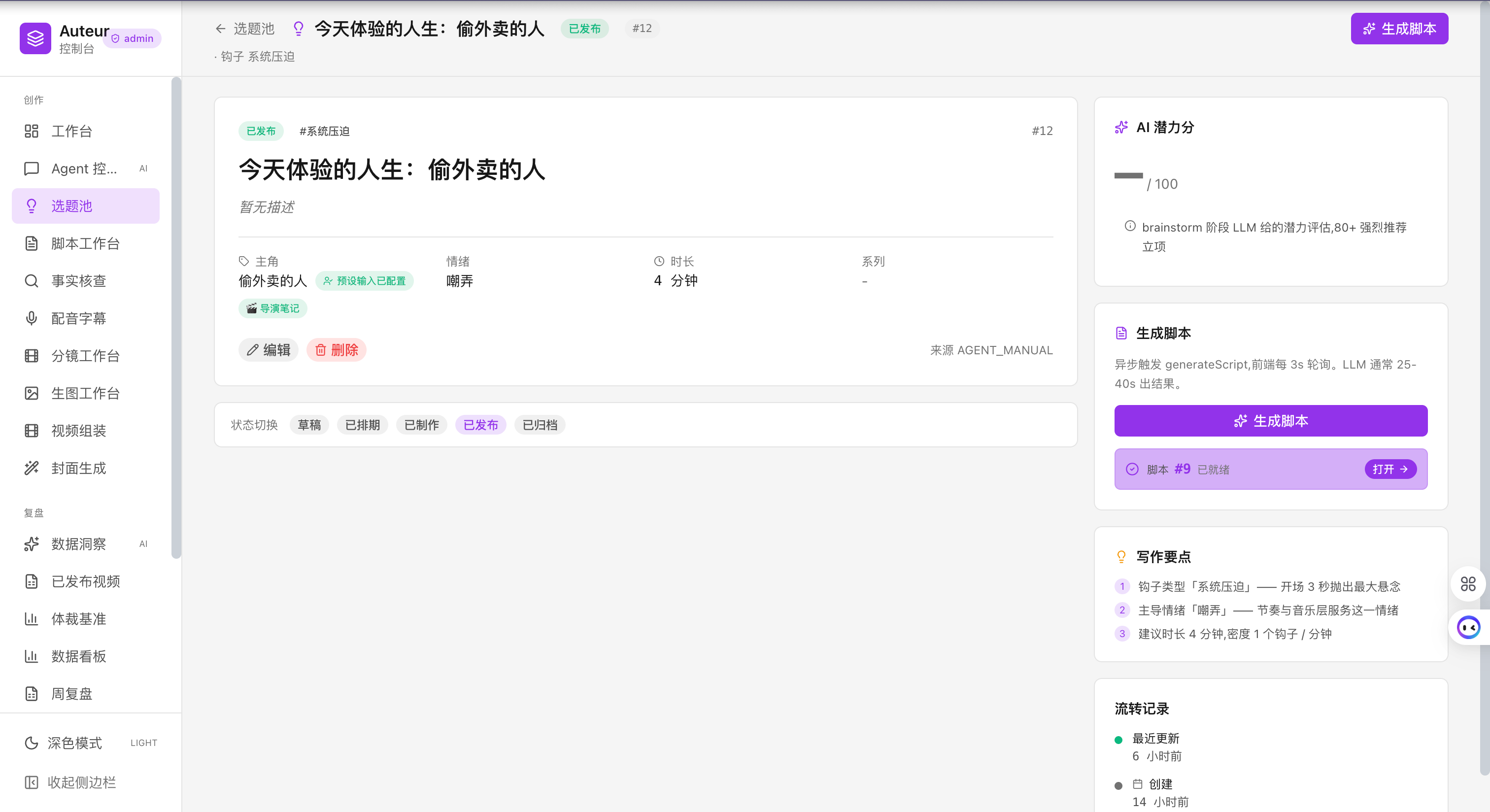
选题池:跨预设管理候选选题,系统自动按"潜力分"排序,数据回写后权重持续校准
协作的关键设计:
- 🔗 显式产物交接 — 每个角色读上游 DB 表、写下游 DB 表。任何一步失败都可单独重跑,中间产物 UI 里全部能看、能改、能删
- 🔄 自审反馈环 — 自审角色(编剧 / 摄影 / 美术)打分低于阈值时,审稿意见塞回原角色重写一次。把 LLM 的不确定性局限到"自己给自己改一稿"的小循环里,不污染整条流水线
- 📓 导演笔记共享 —
DirectorNoteService维护一个跨角色的视觉/叙事中央笔记,编剧、摄影、美术、制片都读。避免每个角色各自漂移 - 🚦 流水线状态机 —
pipeline_run表跟踪每段 PENDING / RUNNING / DONE / FAILED,前端实时进度,断点续跑
2️⃣ 自动化剪辑:让画面与字幕一帧不差
普通流水线最让人崩溃的事:画面和字幕掐不准。
Auteur 在生成时就把这个问题堵掉了。
🎯 PRECISE_BY_CUE:分镜与音频字面对齐
启用后,摄影指导给每个 shot 一段精确的字面 anchor_text(必须是脚本里的连续子串)。后端在 SRT 解析后把 anchor 在音频时间轴上反查出真实秒数:
镜头时长 = anchor 在 SRT 里实际占的秒数 ✅ 不再交给 LLM 估算
后端会自动校验:
- ✅ anchor 是否真的是脚本子串(normalize 后比对)
- ✅ 相邻 shot 的 anchor 在脚本里位置是否单调递增(防 LLM 乱排)
- ⚠️ 没命中 anchor 的镜头会标
anchor_match=false,视频还能渲,但日志和 UI 都提示
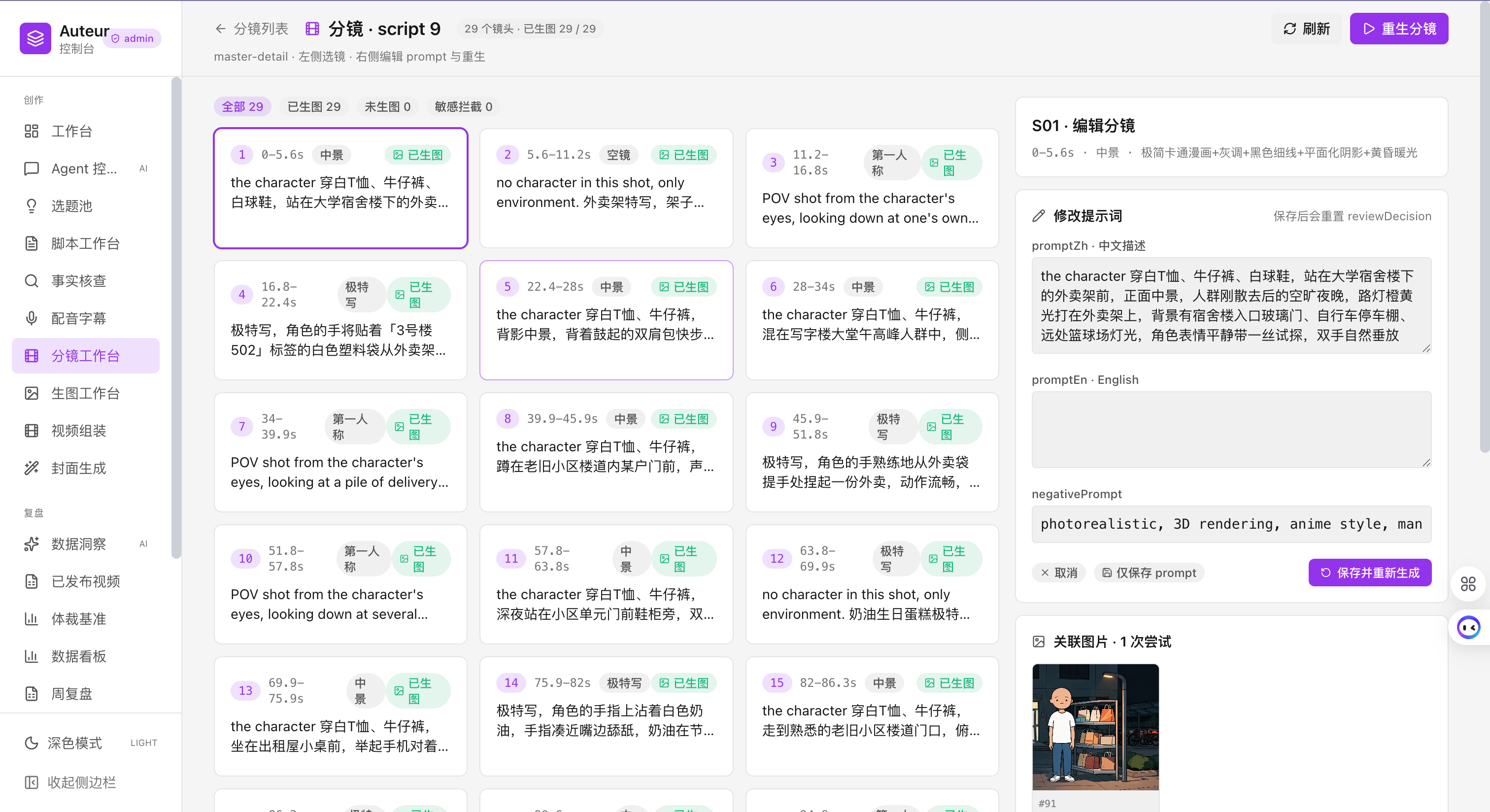
分镜工作台:中英 prompt + anchor + 真实时长,一镜一卡片,可单镜重生成
🎞️ 一键合成,制片角色全自动接管
VideoAssemblyService + FfmpegVideoRenderer / RemotionVideoRenderer 自动完成:
- 📐 解析 SRT →
ShotTimingResolver算每镜真实时长 - 🎬 拼接 ImageClip / VideoClip
- 🔥 烧字幕(subtitles burn-in)
- 🎵 sidechaincompress BGM ducking —— 旁白响起时背景乐自动压低,旁白结束后自动回升
- 📦 直出最终 MP4(横屏 1920×1080 / 竖屏 1080×1920 双 composition 内置)
不需要你打开任何剪辑软件。不需要 Premiere、不需要剪映、不需要 DaVinci。
3️⃣ AI Agent 对话式控制:自然语言驱动整条剧组
不想点 UI?跟 AI 助手说一句"重新生成第 3 个选题的脚本,配音换成女声 v2"——它会理解、规划、调工具、跑完。
Auteur 内置一个 Agent 聊天工作台(/chat),底层是带工具调用 + 审批门槛 + Skill 上下文加载的对话循环:
你:「把昨天那条选题的镜头 5 重新出图,风格更暗一点」
↓
🤖 Agent 加载 adjusting-content skill → 调 get_topic 找到选题 →
查 storyboard_shot 第 5 镜 → 改 prompt 风格关键词 →
调 regenerate_image_for_shot → 等待 → 返回新图给你确认
- 🛠️ 40+ 工具 覆盖选题 CRUD / 流水线触发 / 预设修改 / 内容编辑 / 资产发布
- 📚 Skills 自动加载(
adjusting-content/pipeline-triggering/topic-creation/preset-modification/content-editing)—— Agent 自己找剧本 - ✅ 危险操作审批门槛 —— 改预设、删数据这类动作前端弹出审批卡,你按一下才执行
- 🔁 可中断 / 可继续 / 可回滚 —— 每条消息持久化到 DB,session 重开能继续
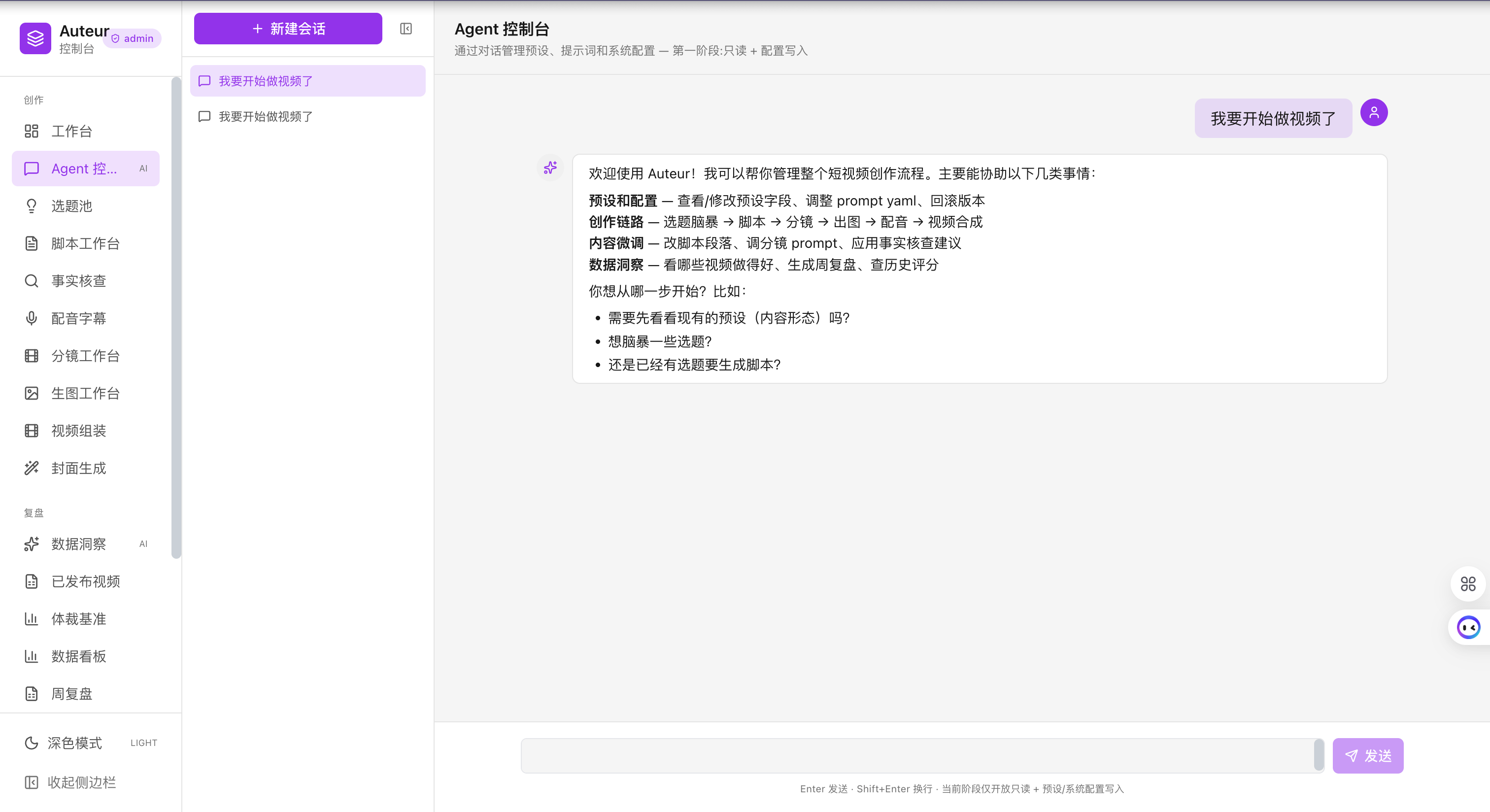
/chat 工作台:自然语言下指令,Agent 自动加载 skill、调工具、串联流水线
这意味着:你可以一边跟 AI 聊创作思路,一边它在后台真的把活干完了。
🎨 其它关键设计
预设驱动(preset-driven):不改一行代码切换内容形态
每种"内容形态"(横屏纪录片 / 竖屏故事 / 锁脸人设短剧……)由一行预设决定:
preset:
brainstorm_prompt_yaml # 给"选题策划"的剧本
script_prompt_yaml # 给"编剧"
script_critic_prompt_yaml # 给"编剧自审"
script_critic_threshold: 80 # 自审分数阈值
storyboard_prompt_yaml # 给"摄影"
storyboard_mode: PRECISE_BY_CUE # 强制按 SRT cue 锚定
bgm_mood_prompt_yaml # 给"作曲"
image_config_json: # 模型/锁脸/参考图/style suffix
voice_config_json: # 音色/语速/音量
composition_id: LifeCopy # Remotion composition
format_width / format_height
watermark_text
hook_segment_enabled
bgm_enabled
- ✅ 每次保存写一份
preset_version快照,UI 一键回滚到任意版本 - ✅ 导出 =
GET /api/presets/{id}拿 JSON,导入 =POST /api/presets,直接放进 Git 做版本控制 - ✅ 仓库内置:
freeform(通用基础模板,默认 seed) +LifeCopy(横屏锁脸人设 + 漫画风 + 翻书音效 hook + PRECISE_BY_CUE,代码内置但默认不 seed)
数据回写驱动复盘(元学习层)
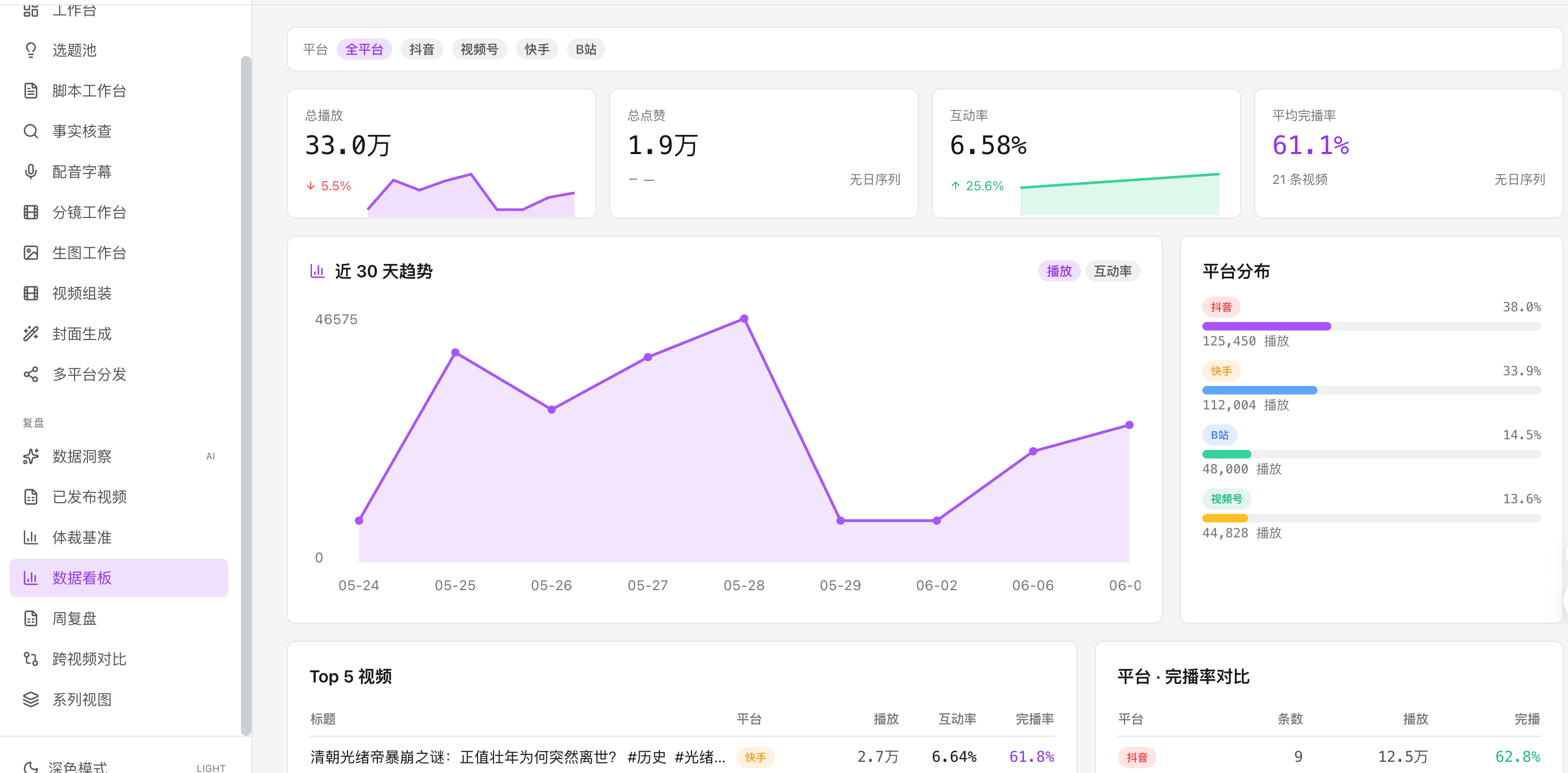
数据看板:抖音/B站/视频号/快手 后台数据自动回写,完播率 × 钩子 × 题材交叉归因,反哺下一轮选题脑暴
extension/ 是一个浏览器扩展,插到抖音 / B 站 / 视频号 / 快手 的"创作者后台"页面,自动抓播放数 / 完播率 / 互动数据 POST 回 Auteur,落到 published_video 表。
WeeklyReviewService 每周根据这些数据算:
- 哪些 朝代 × 题材 × 钩子 组合表现最好(特征贡献度归因)
- 上周哪些计划落地了 / 没落地
- 给下周的选题脑暴一个"权重表 + 重点改进项"
下一次"选题策划"角色就会读这份周报,按数据权重影响候选打分。这是流水线的元学习层 —— 越跑越懂你的受众。
本地优先 + 可降级:缺哪个外部依赖都能跑
| 依赖 | 没配会怎样 |
|---|---|
| 火山 TOS 对象存储 | 自动降级到 backend/storage/ 本地路径 + /api/files/... 静态服务 |
| 火山豆包 TTS | 配音环节 graceful disabled,前端会提示 |
| Jamendo BGM API | BGM 不推荐,制片照常合成(没 BGM 而已) |
| Remotion | auteur.video.provider=ffmpeg 走纯 ffmpeg 路径 |
| LLM 网关 | OpenAI 兼容协议,自部署 vLLM、DeepSeek、智谱、Anthropic 都行 |
后端不会因为某个外部依赖缺失而启动失败 —— 降级路径都打过。
🏗️ 架构
backend/ Spring Boot 3.3 + JPA + Flyway + MySQL 16 个 AI 角色 + Agent 对话循环 + 流水线编排 + REST API
frontend/ Vue 3 + Vite + TypeScript + Pinia 创作工作台 + 预设库 UI + AI Agent 聊天界面
renderer/ Remotion (TypeScript) 视频合成器(可选,ffmpeg 默认走通)
extension/ Chrome 扩展(4 平台) 回写抖音 / B 站 / 视频号 / 快手 后台数据
数据流以 DB 表为骨架:
topic → script → storyboard_shot → image_asset → voice_asset → video_asset → published_video → weekly_review
每一阶段产物落库,所有 AI 角色之间不直接 RPC,全部通过 DB 解耦。这意味着:随便挑一段重跑、随便挑一段人工介入、随便挑一段拿出来看,全都行。
⚡ 快速启动
🐳 推荐路径:Docker Compose 一键启动
零配置 3 分钟跑起来,只需要 Docker Desktop:
git clone <this repo> && cd Auteur
cp .env.example .env # 想改 MySQL 密码 / 端口可以编辑
docker compose up -d --build # 第一次会拉镜像 + maven build + npm build,约 3-5 分钟
启动完打开 http://localhost:5174:
- 右上角切到 admin 模式 →「系统设置」
- 填 LLM
base-url + api-key(必填,OpenAI 兼容协议都行:vLLM / DeepSeek / 智谱 / 自部署网关) - 火山豆包 TTS / 火山 TOS / Jamendo client-id 想用就填,留空对应功能 graceful 降级,后端不挂
配置存
app_config表,不需要碰任何 yml 文件。改密钥也是 UI 上改完保存即生效。
docker compose logs -f backend # 看后端日志
docker compose down # 停服务(数据保留)
docker compose down -v # 停服务 + 清空 DB 和产物(慎用)
容器布局:
- 🐬
auteur-mysql— MySQL 8.0 + utf8mb4 + 中国时区 - ☕
auteur-backend— JRE 21 + ffmpeg + Noto CJK 字体(字幕烧录用),Springdockerprofile - 🌐
auteur-frontend— nginx serve 构建产物 + 反代/api到后端,长连接超时 900s 给生图/合成
💡 Remotion 默认在 Docker 里关闭(走纯 ffmpeg 路径,镜像更小)。想要可视化调试 composition,宿主机另跑
cd renderer && npm install && npm run dev。
🛠️ 本地开发(不用 Docker)
0. 前置依赖
- JDK 21
- Node.js 20+ / npm(或 pnpm)
- MySQL 8.0+
- ffmpeg(
brew install ffmpeg/apt install ffmpeg) - LLM 中继:自部署 vLLM 或任意 OpenAI 兼容协议网关
1. 数据库
CREATE DATABASE auteur CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
Flyway 在 backend/src/main/resources/db/migration/ 启动时自动建表。PresetSeeder 在 preset 表为空时从 preset_seeds/freeform/ 注入示例预设。
2. 配置
cd backend/src/main/resources
cp application-local.yml.example application-local.yml
# 编辑 application-local.yml,填 spring.datasource.password
# LLM / TTS / TOS / Jamendo 等密钥启动后在前端「系统设置」UI 填,落 app_config 表
3. 启动
# 后端
cd backend && mvn spring-boot:run # :8082
# 前端
cd frontend && npm install && npm run dev # :5174,代理 /api → :8082
# Remotion(可选;首次会拉 Chromium ≈150 MB)
cd renderer && npm install
npm run dev # 打开 Remotion Studio 预览 composition
后端在合成阶段自动调 npx remotion render,不需要手动起 Studio —— 只在你想可视化调试 composition 时开。
跑通第一条视频
- 「选题池」→「AI 头脑风暴」→ 选
freeform预设 → 写主题 → 生成 - 选题详情 →「配置预设输入」→ 填
theme / tone / duration_minutes - 「生成脚本」(异步,~30s)
- 脚本工作台 → 跳过事实核查(freeform 默认不跑)→「配音字幕」生成
- 「分镜工作台」生成镜头 prompt →「生图工作台」批量出图
- 「视频组装」点击合成 → ffmpeg/Remotion 渲染 → 落到
backend/storage/video/
或者直接打开「AI 助手」(/chat),跟它说:"帮我用 freeform 预设做一条关于唐朝长安宵禁的视频",它会全程接管。
🎨 自定义新预设
- 「预设库」→「新建预设」(admin 模式按右上角切换)
- 填基本信息 +
input_schema:定义你想让用户填的字段(这会变成创建 topic 时的动态表单) - 编辑三份核心 prompt yaml:brainstorm / script / storyboard,用
{{key}}引用input_schema字段 - 选 composition:横屏 →
StoryHorizontal,竖屏 →StoryVertical,特殊形态 → 自己写一个 Remotion composition 注册到renderer/src/Root.tsx - 保存 → 在选题池用这个预设建 topic
⚙️ 配置参考
application-local.yml 必填:
spring.datasource.password: <你的 MySQL 密码>
auteur.llm.base-url: <OpenAI 兼容 LLM 网关>
auteur.llm.api-key: <key>
可选(留空则对应功能降级,后端不挂):
| 配置项 | 用途 |
|---|---|
auteur.voice.volcano.api-key |
火山豆包 TTS。空 → 配音不可用 |
auteur.tos.access-key/secret-key/bucket |
火山 TOS。空 → 走本地路径,公网访问受限 |
auteur.bgm.jamendo.client-id |
Jamendo 选曲。空 → BGM 推荐不可用 |
auteur.video.ffmpeg.binary-path |
ffmpeg 路径。默认 /opt/homebrew/bin/ffmpeg |
auteur.video.remotion.enabled |
Remotion 合成。默认 true,需 cd renderer && npm install 跑过一次 |
auteur.alert.feishu.webhook-url |
飞书告警机器人。空 → 不告警 |
auteur.extension.token |
浏览器扩展回写校验。生产部署务必覆盖默认值 |
🔐 安全说明
application-local.yml已加入.gitignore,永远不要把真实凭据 commitextension/浏览器插件回写时校验auteur.extension.token,生产环境必须通过环境变量覆盖默认值- 预设的
visibility=private是软标记(不是真鉴权),只在 UI 层按X-Auteur-Admin头隔离 —— 部署到公网时需要在反向代理层加真实鉴权(Nginx basic auth / OAuth2 proxy 都行) - LLM 中继自托管推荐:vLLM + Caddy 反代 + IP 白名单。商业网关(DeepSeek / Anthropic / 智谱)走 https + key rotation
🤝 贡献
PR / Issue 欢迎。详细流程、cookbook(怎么加新角色 / 新预设 / 新 Agent 工具)、commit 规范见 CONTRIBUTING.md。
提 PR 时确保:
- backend 改动
mvn -B -DskipTests compile通过 - frontend 改动
npm run build通过(含 vue-tsc 严格类型检查) - 改 schema → 加 Flyway migration 用递增
V*编号 - 改预设相关代码 → 同步更新
preset_seeds/<name>/seed 文件
用 AI 助手(Claude Code / Cursor)改代码?读一下 CLAUDE.md —— AI 进项目前的 onboarding cheat sheet。
📜 License
MIT License © 2026 宁鑫
随便用、随便改、随便商用 —— 保留版权声明即可。
如果这个项目让你觉得"哦原来短视频流水线可以做成这样",欢迎 ⭐ Star —— 这是对作者最直接的鼓励。
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi