segundo-cerebro
Health Uyari
- No license — Repository has no license file
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 14 GitHub stars
Code Uyari
- network request — Outbound network request in src/auth/handler.ts
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
Personal knowledge graph MCP server on Cloudflare D1 + Vectorize. Deploy your own sovereign second brain in one click — Claude captures atomic concepts, finds cross-domain analogies, and links them with substantive justifications. Latticework thinking as a service, running entirely in your Cloudflare account.
Segundo Cérebro — um grafo de conhecimento pessoal pro Claude, rodando no Cloudflare
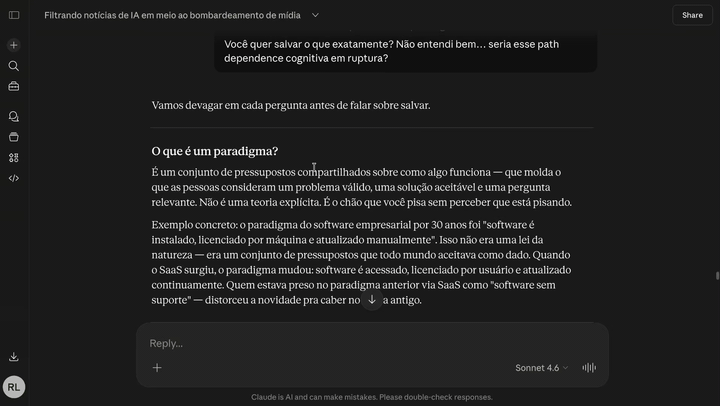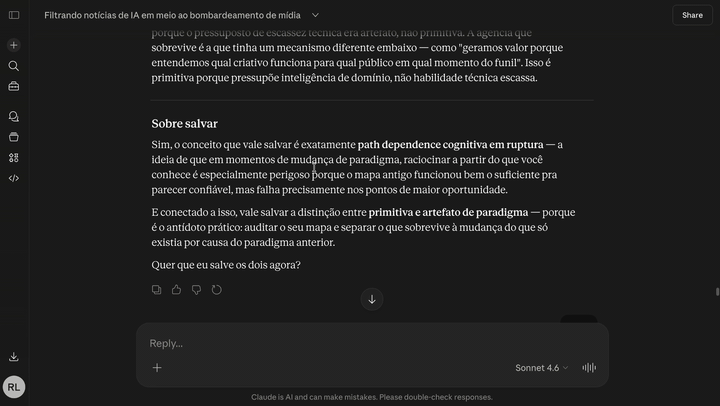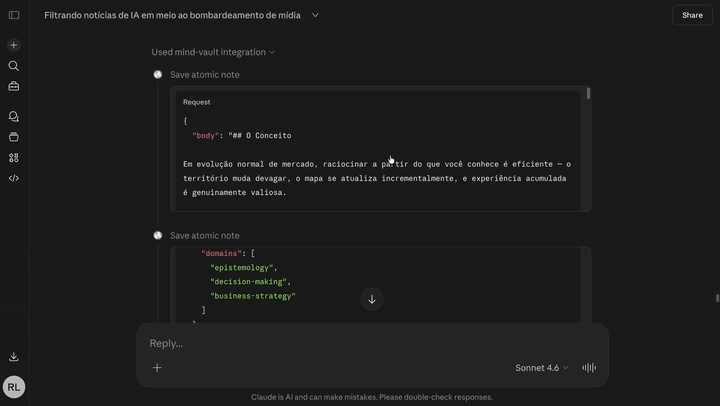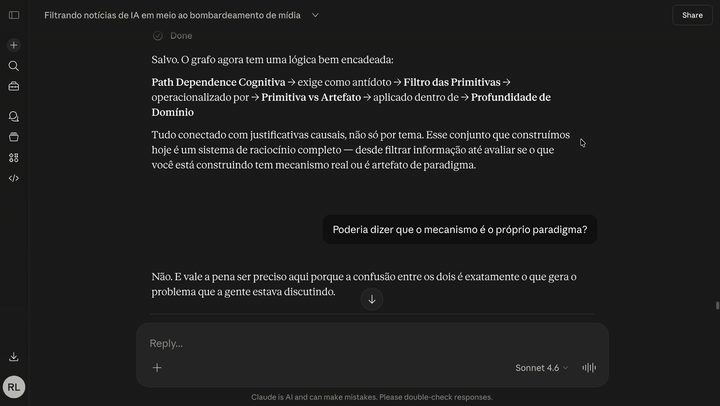
A ferramenta de pensamento latticework pra quem conversa com o Claude. Segundo Cérebro é um grafo de conhecimento self-hosted, de usuário único, que roda 100% na sua conta Cloudflare e conecta no Claude Code, Claude Desktop ou Claude Web como servidor MCP. Você conversa com o Claude sobre uma ideia, ele decide o que vale guardar, atomiza o conceito, varre o vault atrás de analogias entre domínios diferentes, e salva a nota com edges que nomeiam o mecanismo compartilhado — não só "relacionado".
Não é um app de notas. É uma ferramenta de pensamento.
- ✅ Conceitos, não páginas. Cada nota é uma ideia só, título em uma linha, resumida numa frase (teste Feynman).
- ✅ Edges com substância. 9 tipos de relação (
analogous_to,same_mechanism_as,contradicts,refines, …), cada uma exigindo um why de no mínimo 20 caracteres — o mecanismo por trás da conexão. - ✅ Cross-domain por design. O recall é balanceado por domínio — o vault entrega a conexão inesperada de outro campo, porque é ali que o insight mora.
- ✅ Multilíngue. Escreva em português, inglês, ou o que for da conversa. O modelo de embedding (
bge-m3) recupera em 100+ idiomas. - ✅ Soberano. Tudo vive na sua conta Cloudflare — D1 (SQLite), Vectorize (embeddings), Workers AI. Zero terceiros, zero lock-in, zero assinatura.
- ✅ OAuth 2.1 + registro dinâmico de cliente. Claude Desktop e Claude Web plugam só com a URL; sem malabarismo de token.
Pra quem é isso?
- Quem vive no Claude Code e quer que o que aprende se acumule entre sessões, em vez de evaporar no fim de cada conversa.
- Quem procura uma alternativa "Claude-native" ao Obsidian ou Notion pra capturar ideias — especificamente no estilo cross-domain, guiado por analogia, do latticework de modelos mentais do Charlie Munger ou do Zettelkasten do Luhmann.
- Escritores, pesquisadores, pensadores que leem entre áreas e querem um segundo cérebro que obriga a procurar a sobreposição estrutural em vez de enterrar as notas em pastas.
Segundo Cérebro não é substituto pra app de captura diária. Ele é pro subconjunto do seu pensamento que vale preservar com rigor — as ideias que você vai querer reencontrar, num contexto diferente, daqui a alguns anos.
Quando faz sentido (e quando não)
Segundo Cérebro é uma ferramenta opinativa — é uma disciplina embrulhada num servidor MCP. Antes de instalar, vale bater as duas listas abaixo.
✅ Vai te servir bem se…
- Você lê ou trabalha entre múltiplos domínios e quer que as analogias estruturais entre eles apareçam sozinhas. O ponto do vault é notar que um padrão que você acabou de ver em engenharia de software é a mesma forma de algo que você leu em biologia evolutiva ano passado.
- Você já vive dentro do Claude Code, Claude Desktop ou cliente compatível com Claude. Segundo Cérebro é um servidor MCP — o valor vem de estar ao alcance sem sair da conversa.
- Você toma decisões de julgamento cujo raciocínio vale preservar — decisões de design, conclusões de pesquisa, apostas estratégicas. O vault protege o porquê pra você revisitar depois.
- Você tá no Pro, Max ou na API e pode arcar com os ~2.400 tokens de overhead por requisição fria. No Max 5x/20x isso é desprezível.
- Você compra o método Munger/Luhmann: um conceito por nota, links com whys substantivos, estrutura cross-domain em vez de pastas. Se você não compra o método, a ferramenta vai parecer atrito.
⚠️ Talvez não seja pra você agora se…
- Você tá no Claude Free. O overhead do MCP come ~27% da sua janela de 5h antes de você digitar qualquer coisa. Volta quando subir pra Pro.
- O que você quer é diário ou lista de tarefa. O vault é rigoroso por design — rejeita captura efêmera. Pra esse uso, Obsidian, Notion ou Apple Notes resolvem melhor.
- Você trabalha só num domínio estreito. A proposta de valor é recall cross-domain. Quem atua num domínio só extrai quase tudo de uma pasta de markdown simples +
grep. - Você não usa o Claude como interface principal. O vault é navegável por um dashboard web, mas a disciplina de escrita só funciona quando tem um LLM mediando o fluxo de save. Sem isso, você vai voltar a despejar notas.
- Você ainda está no modo "quero capturar tudo". Segundo Cérebro pune saves de baixo sinal — notas relaxadas poluem recalls futuros. Se você não consegue articular um tldr de uma frase, talvez valha amadurecer a ideia antes de guardar.
- Você precisa de acesso offline ou armazenamento local. O vault roda no D1 + Vectorize da Cloudflare. Suas notas saem da sua máquina.
- Você se importa em preservar a forma exata do que escreveu. O vault empurra pra atomização e reescrita — é ferramenta de pensamento, não de arquivo.
A frase honesta
Segundo Cérebro vale a pena quando você trata ele como uma disciplina pras ideias que você vai querer de volta, não como lugar pra despejar coisa. Se essa distinção não ressoa, talvez o próximo mês seja uma hora melhor.
💰 Custo: R$ 0 — roda inteiro no free tier da Cloudflare
Antes de sair deployando, lê isso: você não vai ser cobrado. Segundo Cérebro roda no free tier da Cloudflare, que é generoso o suficiente pra um vault pessoal nunca chegar perto dos limites:
| Serviço | Free tier | O que um vault pessoal consome |
|---|---|---|
| Workers (o servidor) | 100.000 requisições/dia | ~50 reqs/dia em uso ativo |
| D1 (o banco) | 5 GB de armazenamento, 5M leituras/dia, 100k escritas/dia | Alguns MB, centenas de leituras |
| Vectorize (a busca) | 5M vetores armazenados, 30M queries/mês | Alguns milhares no máximo |
| Workers AI (embeddings) | 10.000 neurônios/dia | Algumas centenas |
| KV (tokens OAuth + cache do grafo) | 100k leituras/dia, 1k escritas/dia (por namespace) | Poucas leituras por login + layout de grafo cacheado |
Não precisa de cartão de crédito pra criar conta na Cloudflare. Dá pra cadastrar só com email em cloudflare.com/sign-up, confirmar o email, e pronto. Mesmo se você estourasse o free tier (não vai), a Cloudflare mostra aviso antes de cobrar qualquer coisa — nunca uma fatura surpresa.
⚠️ O custo real: tokens do Claude
A infra é grátis, mas conectar o MCP ao Claude não é grátis do ponto de vista do orçamento de tokens. Você precisa entender isso antes de decidir se Segundo Cérebro vale pro seu padrão de uso.
O que custa
| Custo | Tokens | Quando você paga |
|---|---|---|
| Overhead sempre-ligado do MCP | ~2.400 | Toda requisição enquanto o MCP tiver conectado (cacheável, TTL de 5 min) |
Resposta do recall |
100–300 | Por chamada (retorna só os tldrs, nunca o corpo — barato por design) |
Resposta do get_note |
500–2.000 | Por chamada (corpo completo) |
Os ~2.400 tokens vêm das descrições de tool e instruções de uso que o MCP injeta no system prompt (src/mcp/instructions.ts + os 9 schemas de tool). Eles carregam em toda requisição enquanto o MCP tá conectado, use você o vault naquele turno ou não. O cache de prompt (TTL de 5 min) torna isso quase grátis em conversa contínua, mas você repaga em todo cold start.
Impacto por plano do Claude
A Anthropic não publica quotas exatas pros planos de consumidor, mas a leitura prática baseada em números observados pela comunidade:
| Plano | Janela de uso | Orçamento observado | Overhead MCP como % da janela |
|---|---|---|---|
| Free | 5h rolling | muito apertado (~9k tok efetivos) | ~27% — não use Segundo Cérebro no Free |
| Pro (US$ 20/mês) | 5h rolling + limite semanal | ~44k tok por janela de 5h | ~5,5% por requisição fria |
| Max 5x (US$ 100/mês) | 5h rolling + limite semanal | ~220k tok por janela de 5h | ~1,1% |
| Max 20x (US$ 200/mês) | 5h rolling + limite semanal | ~880k tok por janela de 5h | ~0,3% |
| API (Claude Code / SDK) | sem janela, paga por token | ilimitado | cobrado direto (~US$ 0,036/turno frio no Opus, ~US$ 0,0036 com cache) |
Pontos importantes sobre as janelas dos planos:
- Todos os planos pagos usam janela rolling de 5h, não reset diário. Mensagens caem 5h depois do envio. Confere em
/usageno Claude Code ou emclaude.ai/settings/usagepra ver o contador ao vivo. - Limites semanais foram adicionados em agosto/2025 no Pro e Max pra usuários pesados, além da janela de 5h. O overhead fixo do Segundo Cérebro também conta pro semanal.
- Horário de pico queima mais rápido: em dia de semana, 5–11h PT / 13–19h GMT, a Anthropic aperta os limites da sessão de 5h durante alta demanda. Uma sessão com MCP conectado e 10 turnos frios no pico pode comer um pedaço notável da janela Pro.
- Billing da API é o modelo oposto: sem janela, mas cada token é medido. Aqui o overhead do MCP vira linha de custo real. Disciplina de cache importa mais.
Recomendações práticas
- Plano Free: nem vale. O overhead do MCP come muito da sua janela minúscula.
- Plano Pro: conecta o MCP seletivamente. Em conversa que vai mexer no vault, deixa ligado. Em uma hora de UI ou debug, desconecta — você ganha bem mais folga na janela de 5h.
- Max 5x / 20x: deixa ligado. O overhead é <1% da janela e a disciplina codificada nas descrições de tool se paga na primeira vez que ela impede uma nota ruim.
- API / Claude Code: deixa ligado em sessões focadas no vault, desconecta em outras. Você paga por token de qualquer jeito; calor do cache é a sua melhor alavanca.
- Agrupa as interações com o vault numa mesma sessão. Cinco recalls seguidos ficam em cache e são quase de graça. Cinco recalls espalhados pelo dia pagam cold start cada um.
- Prefere
recallaget_note. Lê o corpo completo só quando o tldr não der conta. Uma nota de 2k tokens lida 5 vezes numa sessão são 10k tokens indo embora.
Pra metodologia completa e o breakdown por tool, veja docs/token-cost.md.
Quickstart — deixa sua IDE agêntica fazer o trabalho
Segundo Cérebro é configurado pela sua IDE agêntica (Claude Code, Cursor, Windsurf, etc), não por wizard web. O repo traz um runbook determinístico em CLAUDE.md que o agente segue ponta a ponta. A única coisa que você digita é email e passphrase. Tudo o mais — provisionar D1, Vectorize, KV, hashear a passphrase, gerar o session secret, subir os secrets, fazer deploy, aplicar o schema — é feito pra você.
O que você precisa:
- Um computador com Node.js 20+ (nodejs.org)
- Uma conta Cloudflare gratuita (cadastro — sem cartão)
- Uma IDE agêntica conectada ao Claude
O fluxo:
git clone https://github.com/orobsonn/segundo-cerebro.git
cd segundo-cerebro
npm install
npx wrangler login # abre o browser → clica "Allow" → pronto
Agora abre a pasta na sua IDE e diz:
Configura o Segundo Cérebro.
O agente lê o CLAUDE.md, te pede email e passphrase (12+ caracteres), e roda o runbook completo. Quando termina, ele te devolve a URL do Worker e a linha pra conectar o Claude Code ao MCP:
claude mcp add --transport http segundo-cerebro https://<seu-worker>.workers.dev/mcp
Abre o /app/config do teu Worker e cola o bloco de personalização que aparece lá em Claude → Settings → Personalization → Custom instructions.
Primeira conversa
Abre o Claude e joga uma ideia:
"Acabei de sacar que tech debt se comporta como juros compostos — quanto mais você ignora, pior fica a taxa."
O Claude chama recall pra varrer o vault atrás de analogias, aí oferece salvar a nota com save_note, atomizando em um conceito por nota e criando edges com justificativas why substantivas. Você vê as chamadas de tool MCP acontecendo na UI da conversa.
O que você vai ver
Tela de notas — cada conceito atomizado, tldr como teste Feynman, domínios o mais estreitos possível.
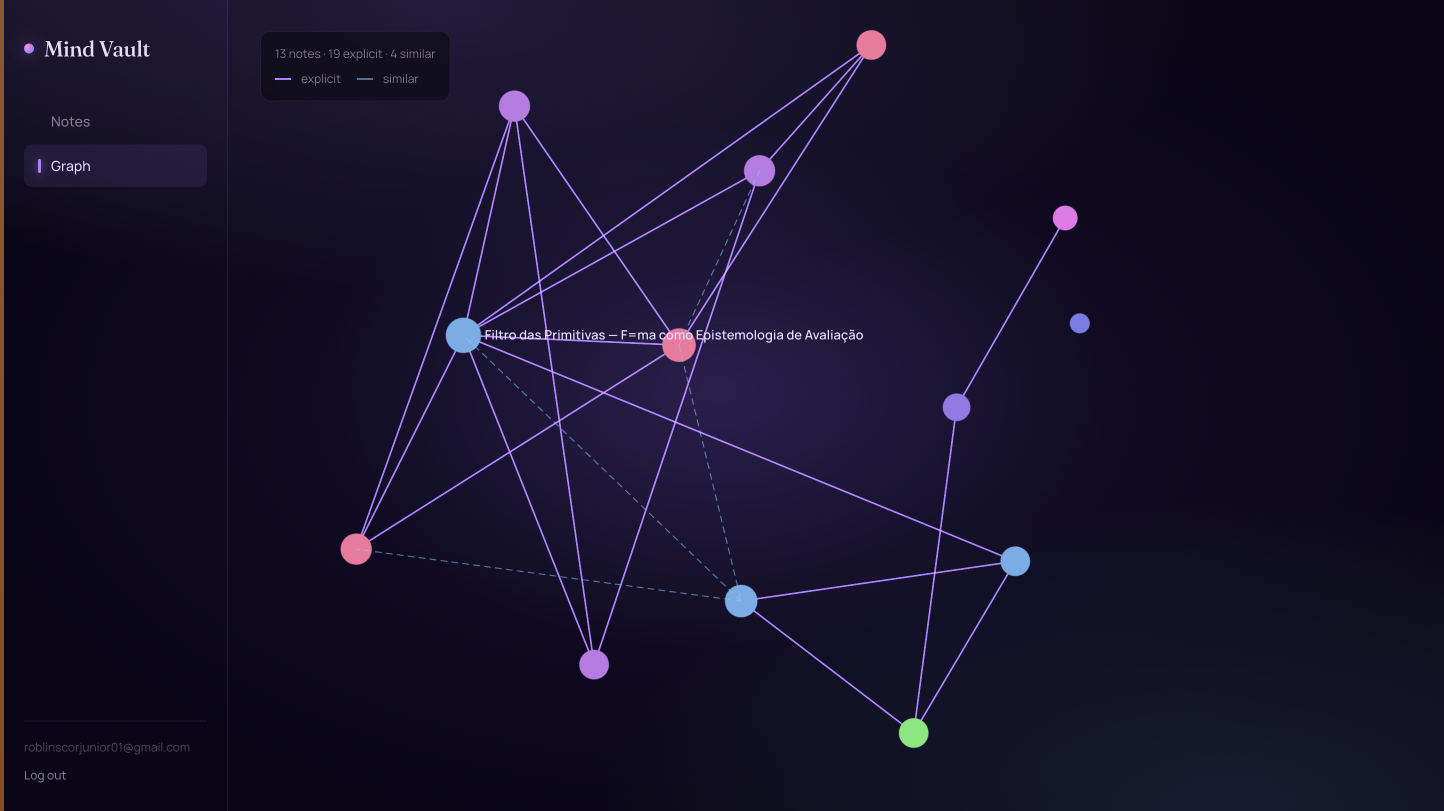
Tela de grafo — física force-directed com reveal no estilo Obsidian. Linhas roxas sólidas são edges explícitos; tracejadas em teal são edges de similaridade semântica emergidos pelo modelo de embedding; nós são coloridos por domínio.
🎯 As 3 regras de ouro do Segundo Cérebro
Se você esquecer tudo nesse README, lembra dessas três. É o método inteiro em 3 bullets:
1. Uma ideia por nota
Se o título tem "e" (ou "and"), quebra em duas notas. Uma nota = um conceito atômico. O teste: você consegue escrever um tldr de uma frase só? Se não, ela ainda tem mais de uma ideia misturada — atomiza.
Exemplo ruim: "Feedback loops e economia comportamental" — dois conceitos.
Exemplo bom: "Feedback loop negativo com atraso oscila" + "Viés de disponibilidade supera dados em decisão sob estresse" — duas notas, um edge entre elas.
2. Todo link precisa de why
O Segundo Cérebro rejeita edges com why menor que 20 caracteres. Não é frescura — é que um edge sem mecanismo explicado é lixo pro recall futuro. "Related" não ajuda ninguém.
O why tem que nomear o mecanismo compartilhado:
- ❌ "Ambos são sobre crescimento" → rejeitado. Vago.
- ✅ "Ambos têm feedback negativo com atraso, então ambos oscilam em vez de convergir" → aceito. Mecanismo nomeado.
3. Sempre recall antes de save
Antes de salvar qualquer nota, o Claude chama recall pra varrer o vault atrás de analogias em outros domínios. É aqui que o segundo cérebro se diferencia de um arquivo de notas.
Você acha que a ideia é nova. O recall traz uma nota sua de 8 meses atrás sobre sucessão ecológica que tem a mesma forma estrutural. Agora você tem dois pontos num grid, e eles se iluminam um ao outro.
Isso é o diferencial do método: não é sobre guardar bem, é sobre forçar a conexão cross-domain no momento do save.
Arquitetura
flowchart LR
User([Você])
Claude[Claude Code<br/>Desktop / Web]
Worker[Cloudflare Worker<br/>endpoint único]
OAuth[OAuth 2.1<br/>grants em KV]
MCP[Servidor MCP<br/>9 tools]
D1[(D1<br/>notas + edges<br/>FTS5)]
Vec[(Vectorize<br/>1024-dim<br/>cosine)]
AI[Workers AI<br/>bge-m3 multilíngue]
Web[Dashboard Web<br/>visualização do grafo]
User -->|chat| Claude
User -->|navega| Web
Claude -->|OAuth| Worker
Web -->|sessão| Worker
Worker --> OAuth
Worker --> MCP
MCP -->|SQL + FTS5| D1
MCP -->|embed query| AI
MCP -->|busca vetorial| Vec
AI -.->|no save| Vec
classDef edge fill:#f4f4f5,stroke:#71717a,color:#18181b
classDef store fill:#ecfdf5,stroke:#10b981,color:#064e3b
classDef compute fill:#eff6ff,stroke:#3b82f6,color:#1e3a8a
class User,Claude,Web edge
class D1,Vec,OAuth store
class Worker,MCP,AI compute
Um único Cloudflare Worker serve três responsabilidades na mesma URL:
| Rota | Função |
|---|---|
/ |
Quando configurado, redireciona pra /app/login. Quando não configurado, mostra uma página estática "termine o setup pela sua IDE agêntica" apontando pro CLAUDE.md. |
/authorize, /token, /register |
OAuth 2.1 via @cloudflare/workers-oauth-provider com registro dinâmico de cliente |
/mcp |
Endpoint MCP protegido por OAuth, servido por McpAgent (agents/mcp) envolvendo McpServer do @modelcontextprotocol/sdk |
/app/* |
Dashboard web (sessão por cookie): /app/graph, /app/notes, /app/config, /app/login |
/status |
Status do vault em JSON (notas, edges, clientes OAuth, tokens ativos, estado de conexão) |
Bindings (tudo no wrangler.toml):
DB— D1 (SQLite) pra notas, edges, tags, FTS5VECTORIZE— índice 1024-dim cosine, um vetor por notaAI— Workers AI, modelo@cf/baai/bge-m3pra embeddings multilínguesOAUTH_KV— namespace KV pra grants/tokens/registros de cliente OAuthGRAPH_CACHE— namespace KV cacheando o layout pré-computado do grafo pro dashboard webASSETS— assets estáticos (bundle do grafo)
Schema (5 tabelas):
notes(id, title, body, tldr, domains JSON, kind, created_at, updated_at)notes_fts(FTS5 virtual em title + tldr + body, sincronizado por triggers)tags(note_id, tag)(escape hatch; a estrutura real mora nos edges)edges(id, from_id, to_id, relation_type, why, created_at)comCHECKenum de 9 tipos de relação eUNIQUE(from_id, to_id, relation_type)meta(key, value)pra metadados singleton
Tools MCP (o que o Claude chama)
| Tool | Função |
|---|---|
save_note |
Nota atômica + edges em uma única chamada. Valida why de edge ≥ 20 chars, slugs de domínio contra regex, existência do edge target, e kind contra o enum fechado. |
update_note |
Edita título/body/tldr/domínios/kind/tags de uma nota existente. Re-embed automático se o tldr mudou. |
delete_note |
Remove a nota do D1 (cascata em edges/tags) e o vetor correspondente do Vectorize. Irreversível. |
recall |
Busca híbrida: embedding Workers AI + FTS5, mesclados e balanceados por domínio (máx 3 por domínio, até 5 domínios distintos). Retorna só {id, title, domain, kind, tldr} — nunca o corpo. |
expand |
Vizinhos de 1 hop de uma nota no grafo. |
get_note |
Corpo completo + tags + edges de uma nota por id. |
link |
Cria um edge entre duas notas existentes (pra quando o Claude detecta conexão entre saves anteriores no meio da conversa). |
stats |
Panorama do vault: total de notas/edges, distribuição por domínio e por kind, notas dos últimos 7 e 30 dias. |
reembed |
Regenera o embedding de uma nota (rescue pra quando o upsert vetorial falhou no save). |
As descrições de tool são escritas em inglês com instruções de fluxo obrigatório ("chama recall antes de save_note") e mensagens de erro pedagógicas ("se a conversa tá em português e você ia usar biologia-evolutiva, usa evolutionary-biology no lugar") que ensinam o Claude a se recuperar de erro em um shot.
Método e linhagem intelectual
flowchart TD
Idea([Você articula uma ideia])
Atomize{Um conceito só?<br/>título tem 'and'/'e'?}
Split[Divide em<br/>notas separadas]
Tldr{Dá pra escrever<br/>um tldr de uma frase?}
NotReady[Continua pensando —<br/>a nota não tá pronta]
Recall[recall entre domínios<br/>mesmo se 'obviamente novo']
Read[Lê TODOS os domínios<br/>retornados, não só o top hit]
Hit{Analogia cross-domain<br/>encontrada?}
Edge[Rascunha o edge com<br/>why substantivo<br/>20+ chars, nomeia o mecanismo]
Save[save_note<br/>atômico + edges em uma chamada]
Vault[(Vault cresce<br/>como latticework)]
Idea --> Atomize
Atomize -->|sim, divide| Split --> Tldr
Atomize -->|não, atômico| Tldr
Tldr -->|não| NotReady
Tldr -->|sim| Recall
Recall --> Read
Read --> Hit
Hit -->|sim| Edge --> Save
Hit -->|não| Save
Save --> Vault
Vault -.->|recall futuro<br/>traz essa nota de volta| Recall
classDef action fill:#eff6ff,stroke:#3b82f6,color:#1e3a8a
classDef check fill:#fef3c7,stroke:#f59e0b,color:#78350f
classDef terminal fill:#ecfdf5,stroke:#10b981,color:#064e3b
classDef stop fill:#fee2e2,stroke:#ef4444,color:#7f1d1d
class Recall,Read,Edge,Save,Split action
class Atomize,Tldr,Hit check
class Idea,Vault terminal
class NotReady stop
Isso não é projeto de sala limpa. Cada decisão tem raiz numa tradição:
- Charlie Munger — latticework de modelos mentais, o valor do pensamento cross-domain. Norte.
- Scott E. Page, The Model Thinker — teorema da previsão por diversidade (diversidade de modelos bate profundidade de um). Base pro recall balanceado por domínio.
- Douglas Hofstadter & Emmanuel Sander, Surfaces and Analogies — analogia como núcleo da cognição. Base pro peso dos edges
analogous_toesame_mechanism_as. - Dedre Gentner, Structure-Mapping Theory — a distinção entre similaridade superficial e estrutural. Mantém os edges honestos.
- Niklas Luhmann / Sönke Ahrens, How to Take Smart Notes (Zettelkasten) — notas atômicas, links com substância, estrutura emergente. Base pro "um conceito uma nota", "nunca linka sem um why" e "nem toda conversa vira nota".
- Richard Feynman — se você não consegue explicar simples, você não entendeu. Base pro campo
tldrobrigatório. - Karl Popper — falibilismo. Base pros edges
contradictserefinescomo cidadãos de primeira classe.
O framing público é pensamento latticework / grafo de conhecimento multi-modelo, não "modelos mentais do Munger" — a base acadêmica (Page, Hofstadter, Gentner, Luhmann) é mais rigorosa que os discursos do Munger sozinhos.
Avançado: auto-deploy no git push (opcional)
Pula essa seção se você não tem certeza de que precisa. O Quickstart acima (com
wrangler login+wrangler deploy) já basta pra uso pessoal — você só re-deploya quando muda o código, e dá pra rodarwrangler deployde novo no terminal.
Esse repo traz um workflow do GitHub Actions (.github/workflows/deploy.yml) que faz auto-deploy pro seu Worker a cada push em master ou main. Útil se você pretende modificar o Segundo Cérebro e quer suas mudanças subindo automático ao dar push no GitHub.
Pra habilitar no seu fork:
- Cria um API token da Cloudflare: vai em dash.cloudflare.com/profile/api-tokens → Create Token → usa o template "Edit Cloudflare Workers", aí adiciona essas permissões extras:
D1 Edit,Vectorize Edit,Workers KV Storage Edit,Workers AI Edit. Clica em Continue → Create Token → copia o token mostrado (ele não aparece de novo). - Copia seu Cloudflare Account ID: em qualquer página do dashboard da Cloudflare, tá na sidebar direita.
- No seu fork do GitHub, vai em Settings → Secrets and variables → Actions → New repository secret e adiciona:
CLOUDFLARE_API_TOKEN= o token do passo 1CLOUDFLARE_ACCOUNT_ID= o account ID do passo 2
- Dá push de qualquer commit em
master. O workflow rodanpm run typecheck+npm testantes do deploy, então teste quebrando bloqueia o deploy.
Dá pra acompanhar as runs em https://github.com/SEU_USUARIO/segundo-cerebro/actions.
Desenvolvimento
npm install
npm run dev # wrangler dev no Miniflare local
npm test # vitest-pool-workers (pool de workers + pool node pra auth)
npm run typecheck # tsc --noEmit
npm run build:bundle # empacota src/web/client → assets/graph.bundle.js
npm run deploy # build bundle + wrangler deploy
Os testes rodam em dois pools: o pool principal de workers (pra testes de D1 + tool MCP com Vectorize / Workers AI mockados), e um pool node separado pro teste de hash de senha (crypto.subtle tá disponível nos dois, mas o pool node mantém o módulo de auth isolado das restrições do runtime dos workers).
Segurança
Single-user por design. Não compartilha a URL do Worker. Acesso é gated por OAuth 2.1 usando email + hash de passphrase armazenados como secrets do Worker. A passphrase em si é hasheada com PBKDF2-SHA256 em 100k iterações (cap do Workers — veja src/auth/password.ts). Os tokens emitidos pelo OAuth provider ficam no namespace OAUTH_KV.
Se você quer versão multi-user, dá fork e adapta — não é mudança plug-and-play. Vai precisar de linhas por usuário no D1, filtro por usuário no Vectorize, e fluxo de registro.
No momento não tem rate limit de login. Pull requests bem-vindos.
Free tier
Os free tiers de D1 + Vectorize + Workers AI bastam pra uso pessoal. Confirma os limites atuais nas páginas de preço da Cloudflare antes de contar com eles pra vaults grandes.
FAQ
E se eu perder a passphrase?
Seus dados sobrevivem — eles vivem no D1, que é uma tabela na sua conta Cloudflare. O que você perde é o acesso ao dashboard web. Pra recuperar:
- Roda o script de hash de novo com a nova passphrase:
node scripts/hash-password.mjs "nova-passphrase" - Atualiza o secret:
echo "<novo-hash>" | npx wrangler secret put OWNER_PASSWORD_HASH - Redeploy:
npx wrangler deploy
Seus Claude Desktop / Claude Code que já estavam conectados via MCP continuam funcionando (eles usam tokens OAuth separados, não a passphrase).
Posso migrar do Obsidian ou Notion?
Não tem importer automático (ainda). Mas funciona bem assim: você conversa com o Claude sobre uma nota do Obsidian por vez, e pede pra ele salvar no vault — ele atomiza, chama recall pra buscar analogias, e salva. Esse processo de "repensar cada nota antes de salvar" é intencional — migrar em lote defeita o método.
Funciona no Windows?
Sim. Wrangler e Node rodam no Windows normal. Na hora do setup, se você usa WSL, melhor — Git Bash ou PowerShell também funcionam, só atenção à sintaxe de echo nos comandos de wrangler secret put (pode precisar trocar as aspas).
Posso exportar meu vault?
Sim. Três opções:
- Export rápido via API:
curl <seu-worker-url>/statustraz totais; pra dump completo, abre o D1 no dashboard Cloudflare e exporta como SQL. - CLI:
npx wrangler d1 export mind-vault --output=dump.sqlgera um dump SQL da sua vault. - Dashboard web: a tela de grafo serve como índice visual; clicar na nota abre o conteúdo.
Posso desligar o MCP sem perder dados?
Sim. Desconectar do Claude só remove o MCP do contexto daquela sessão — todos os seus dados continuam no D1/Vectorize da sua Cloudflare. Quando reconectar, tá tudo lá.
O vault cresce indefinidamente? Vou estourar o free tier?
Cálculo rápido: free tier do Vectorize dá 5M vetores. Uma nota = um vetor. Pra chegar a 5M notas, você teria que salvar uma nota a cada 10 segundos, sem parar, por 1 ano e meio. É efetivamente ilimitado pra uso pessoal.
Dá pra rodar dois vaults separados (pessoal + trabalho, por exemplo)?
Sim, mas cada um precisa do próprio Worker. Forka o repo, cria recursos novos no Cloudflare com nomes diferentes (mind-vault-work, etc), e faz deploy pra cada um. Não tem suporte nativo a múltiplos vaults no mesmo Worker (design single-user).
O Claude vê minhas notas em outras conversas automaticamente?
Só se você mantiver o MCP conectado. Quando conectado, o Claude pode chamar recall a qualquer momento — em geral ele chama quando a conversa bate em conceito ou ideia, não aleatoriamente. Desconecta quando quiser que o Claude não tenha acesso.
E se o Workers AI mudar o modelo de embedding?
Se o modelo atual (bge-m3) for descontinuado ou substituído por algo melhor, dá pra fazer migration rodando reembed em batch em todas as notas. O código já aguenta isso por design — o reembed existe exatamente pra esse caso.
Feito por Robson Lins · Instagram · X / Twitter · YouTube
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi