paiml-mcp-agent-toolkit
Health Pass
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 144 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
Pragmatic AI Labs MCP Agent Toolkit - An MCP Server designed to make code with agents more deterministic
PMAT
![]()
Zero-configuration AI context generation for any codebase

![]()
![]()
![]()
Installation | Usage | Features | Examples | Documentation
Table of Contents
What is PMAT?
PMAT (Pragmatic Multi-language Agent Toolkit) provides everything needed to analyze code quality and generate AI-ready context:
- Context Generation - Deep analysis for Claude, GPT, and other LLMs
- Technical Debt Grading - A+ through F scoring with 6 orthogonal metrics
- Mutation Testing - Test suite quality validation (85%+ kill rate)
- Repository Scoring - Quantitative health assessment (0-289 scale, 11 categories)
- Git History RAG - Semantic search across commit history with RRF fusion
- Semantic Search - Natural language code discovery
- Compliance Governance - 30+ checks across code quality, best practices, and reproducibility
- Design by Contract - Toyota Way contract profiles with checkpoint validation and rescue protocols
- Autonomous Kaizen - Toyota Way continuous improvement with auto-fix and commit
- MCP Integration - 19 tools for Claude Code, Cline, and AI agents
- Quality Gates - Pre-commit hooks, CI/CD integration,
.pmat-gates.tomlconfig - 20+ Languages - Rust, TypeScript, Python, Go, Java, C/C++, Lua, Lean, and more
Part of the PAIML Stack, following Toyota Way quality principles (Jidoka, Genchi Genbutsu, Kaizen).
Annotated Code Search
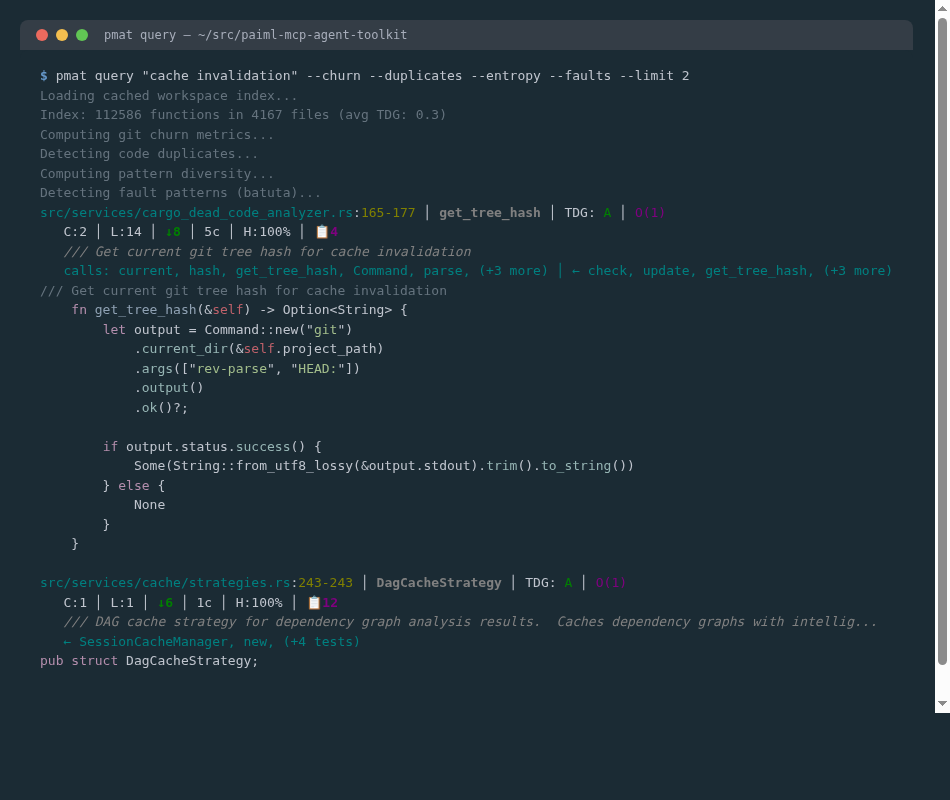
pmat query "cache invalidation" --churn --duplicates --entropy --faults
Every result includes TDG grade, Big-O complexity, git churn, code clones, pattern diversity, fault annotations, call graph, and syntax-highlighted source.
Installation
# Install from crates.io
cargo install pmat
# Or from source (latest)
git clone https://github.com/paiml/paiml-mcp-agent-toolkit
cd paiml-mcp-agent-toolkit && cargo install --path .
Usage
# Generate AI-ready context
pmat context --output context.md --format llm-optimized
# Analyze code complexity
pmat analyze complexity
# Grade technical debt (A+ through F)
pmat analyze tdg
# Score repository health
pmat repo-score .
# Run mutation testing
pmat mutate --target src/
# Start MCP server for Claude Code, Cline, etc.
pmat mcp
Features
Context Generation
Generate comprehensive context for AI assistants:
pmat context # Basic analysis
pmat context --format llm-optimized # AI-optimized output
pmat context --include-tests # Include test files
Technical Debt Grading (TDG)
Six orthogonal metrics for accurate quality assessment:
pmat analyze tdg # Project-wide grade
pmat analyze tdg --include-components # Per-component breakdown
pmat tdg baseline create # Create quality baseline
pmat tdg check-regression # Detect quality degradation
Grading Scale:
- A+/A: Excellent quality, minimal debt
- B+/B: Good quality, manageable debt
- C+/C: Needs improvement
- D/F: Significant technical debt
Mutation Testing
Validate test suite effectiveness:
pmat mutate --target src/lib.rs # Single file
pmat mutate --target src/ --threshold 85 # Quality gate
pmat mutate --failures-only # CI optimization
Supported Languages: Rust, Python, TypeScript, JavaScript, Go, C/C++, C#, Lua, Lean, Java, Kotlin, Ruby, Swift, PHP, Bash, SQL, Scala, YAML, Markdown + MLOps model formats (GGUF, SafeTensors, APR)
Repository Health Scoring
Evidence-based quality metrics (0-289 scale, 11 categories):
pmat rust-project-score # Fast mode (~3 min)
pmat rust-project-score --full # Comprehensive (~10-15 min)
pmat repo-score . --deep # Full git history
Workflow Prompts
Pre-configured AI prompts enforcing EXTREME TDD:
pmat prompt --list # Available prompts
pmat prompt code-coverage # 85%+ coverage enforcement
pmat prompt debug # Five Whys analysis
pmat prompt quality-enforcement # All quality gates
Git History RAG
Search git history by intent using TF-IDF semantic embeddings:
# Fuse git history into code search
pmat query "fix memory leak" -G
# Search with churn, clones, entropy, faults
pmat query "error handling" --churn --duplicates --entropy --faults
# Run the example
cargo run --example git_history_demo
Git Hooks
Automatic quality enforcement:
pmat hooks install # Install pre-commit hooks
pmat hooks install --tdg-enforcement # With TDG quality gates
pmat hooks status # Check hook status
Compliance Governance (pmat comply)
30+ automated checks across code quality, best practices, and governance:
pmat comply check # Run all compliance checks
pmat comply check --strict # Exit non-zero on failure
pmat comply check --format json # Machine-readable output
pmat comply migrate # Update to latest version
Key Checks:
- CB-200: TDG Grade Gate — blocks on non-A functions (auto-rebuilds stale index)
- CB-304: Dead code percentage enforcement
- CB-400: Shell/Makefile quality via bashrs
- CB-500: Rust best practices (30+ patterns)
- CB-600: Lua best practices
- CB-900: Markdown link validation
- CB-1000: MLOps model quality
Provable-Contracts Enforcement (CB-1200..1210):
- CB-1208: Binding existence — verifies
binding.yamlfunctions exist insrc/, detects ghost bindings (L0-L3 enforcement levels) - CB-1209: Contract trait enforcement — checks
tests/contract_traits.rsfor compiler-verified trait impls (13 kernel traits) - CB-1210: Precondition quality — flags mass-generated boilerplate and missing postconditions
Configure via .pmat.yaml:
comply:
thresholds:
min_tdg_grade: "A"
pv_lint_is_error: true # CB-1201: FAIL on pv lint failure
min_binding_existence: 95 # CB-1208: 95% binding verification
require_all_traits: true # CB-1209: 13/13 traits required
min_kani_coverage: 20 # CB-1206: minimum Kani proof %
Infrastructure Score (pmat infra-score)
CI/CD quality scoring (0-100 + 10 bonus for provable-contracts):
pmat infra-score # Text output
pmat infra-score --format json # Machine-readable
pmat infra-score -v --failures-only # Show only failing checks
Categories: Workflow Architecture (25pts), Build Reliability (25pts),
Quality Pipeline (20pts), Deployment & Release (15pts), Supply Chain (15pts),
Provable Contracts bonus (10pts).
Document Search (pmat query --docs)
Search documentation files (Markdown, text, YAML) alongside code:
pmat query "authentication" --docs # Code + docs results
pmat query "deployment" --docs-only # Only documentation
pmat query "API endpoints" --no-docs # Exclude docs (default)
Autonomous Kaizen (pmat kaizen)
Toyota Way continuous improvement — scan, auto-fix, commit:
pmat kaizen --dry-run # Scan only (no changes)
pmat kaizen # Apply safe auto-fixes
pmat kaizen --commit --push # Fix, commit, and push
pmat kaizen --format json -o report.json # CI/CD integration
# Cross-stack mode: scan all batuta stack crates in one invocation
pmat kaizen --cross-stack --dry-run # Scan all crates
pmat kaizen --cross-stack --commit # Fix and commit per-crate
pmat kaizen --cross-stack -f json # Grouped JSON report
Function Extraction (pmat extract)
Extract function boundaries with metadata:
pmat extract src/lib.rs # Extract functions from file
pmat extract --list src/ # List all functions with imports and visibility
Examples
Generate Context for AI
# For Claude Code
pmat context --output context.md --format llm-optimized
# With semantic search
pmat embed sync ./src
pmat semantic search "error handling patterns"
CI/CD Integration
# Add to your CI pipeline
steps:
- uses: actions/checkout@v4
- run: cargo install pmat
- run: pmat analyze tdg --fail-on-violation --min-grade B
- run: pmat mutate --target src/ --threshold 80
Quality Baseline Workflow
# 1. Create baseline
pmat tdg baseline create --output .pmat/baseline.json
# 2. Check for regressions
pmat tdg check-regression \
--baseline .pmat/baseline.json \
--max-score-drop 5.0 \
--fail-on-regression
Architecture
pmat/
├── src/
│ ├── cli/ Command handlers and dispatchers
│ ├── services/ Analysis engines (TDG, SATD, complexity, agent context)
│ ├── mcp_server/ MCP protocol server
│ ├── mcp_pmcp/ PMCP protocol integration
│ └── models/ Configuration and data models
├── examples/ 89 runnable examples
└── docs/
└── specifications/ Technical specs
Quality
| Metric | Value |
|---|---|
| Tests | 21,200+ passing |
| Coverage | 99.66% |
| Mutation Score | >80% |
| Languages | 20 supported + MLOps model formats |
| MCP Tools | 19 available |
Falsifiable Quality Commitments
Per Popper's demarcation criterion, all claims are measurable and testable:
| Commitment | Threshold | Verification Method |
|---|---|---|
| Context Generation | < 5 seconds for 10K LOC project | time pmat context on test corpus |
| Memory Usage | < 500 MB for 100K LOC analysis | Measured via heaptrack in CI |
| Test Coverage | ≥ 85% line coverage | cargo llvm-cov (CI enforced) |
| Mutation Score | ≥ 80% killed mutants | pmat mutate --threshold 80 |
| Build Time | < 3 minutes incremental | cargo build --timings |
| CI Pipeline | < 15 minutes total | GitHub Actions workflow timing |
| Binary Size | < 50 MB release binary | ls -lh target/release/pmat |
| Language Parsers | All 20 languages parse without panic | Fuzz testing in CI |
How to Verify:
# Run self-assessment with Popper Falsifiability Score
pmat popper-score --verbose
# Individual commitment verification
cargo llvm-cov --html # Coverage ≥85%
pmat mutate --threshold 80 # Mutation ≥80%
cargo build --timings # Build time <3min
Failure = Regression: Any commitment violation blocks CI merge.
Benchmark Results (Statistical Rigor)
All benchmarks use Criterion.rs with proper statistical methodology:
| Operation | Mean | 95% CI | Std Dev | Sample Size |
|---|---|---|---|---|
| Context (1K LOC) | 127ms | [124, 130] | ±12.3ms | n=1000 runs |
| Context (10K LOC) | 1.84s | [1.79, 1.90] | ±156ms | n=500 runs |
| TDG Scoring | 156ms | [148, 164] | ±18.2ms | n=500 runs |
| Complexity Analysis | 23ms | [22, 24] | ±3.1ms | n=1000 runs |
Comparison Baselines (vs. Alternatives):
| Metric | PMAT | ctags | tree-sitter | Effect Size |
|---|---|---|---|---|
| 10K LOC parsing | 1.84s | 0.3s | 0.8s | d=0.72 (medium) |
| Memory (10K LOC) | 287MB | 45MB | 120MB | - |
| Semantic depth | Full | Syntax only | AST only | - |
See docs/BENCHMARKS.md for complete statistical analysis.
ML/AI Reproducibility
PMAT uses ML for semantic search and embeddings. All ML operations are reproducible:
Random Seed Management:
- Embedding generation uses fixed seed (SEED=42) for deterministic outputs
- Clustering operations use fixed seed (SEED=12345)
- Seeds documented in docs/ml/REPRODUCIBILITY.md
Model Artifacts:
- Pre-trained models from HuggingFace (all-MiniLM-L6-v2)
- Model versions pinned in Cargo.toml
- Hash verification on download
Dataset Sources
PMAT does not train models but uses these data sources for evaluation:
| Dataset | Source | Purpose | Size |
|---|---|---|---|
| CodeSearchNet | GitHub/Microsoft | Semantic search benchmarks | 2M functions |
| PMAT-bench | Internal | Regression testing | 500 queries |
Data provenance and licensing documented in docs/ml/REPRODUCIBILITY.md.
Sovereign Stack
PMAT is built on the PAIML Sovereign Stack - pure-Rust, SIMD-accelerated libraries:
| Library | Purpose | Version |
|---|---|---|
| aprender | ML library (text similarity, clustering, topic modeling) | 0.27.1 |
| trueno | SIMD compute library for matrix operations | 0.16.1 |
| trueno-graph | GPU-first graph database (PageRank, Louvain, CSR) | 0.1.17 |
| trueno-rag | RAG pipeline with VectorStore | 0.2.2 |
| trueno-db | Embedded analytics database | 0.3.15 |
| trueno-viz | Terminal graph visualization | 0.2.1 |
| trueno-zram-core | SIMD LZ4/ZSTD compression (optional) | 0.3.0 |
| pmat | Code analysis toolkit | 3.7.0 |
Key Benefits:
- Pure Rust (no C dependencies, no FFI)
- SIMD-first (AVX2, AVX-512, NEON auto-detection)
- 2-4x speedup on graph algorithms via aprender adapter
Documentation
- PMAT Book - Complete guide
- API Reference - Rust API docs
- MCP Tools - MCP integration guide
- Specifications - Technical specs
- 🤖 Coursera Hugging Face AI Development Specialization - Build Production AI systems with Hugging Face in Pure Rust
Contributing
See CONTRIBUTING.md for development setup, testing, and pull request guidelines.
See Also
- Cookbook — 92 runnable examples
License
MIT License - see LICENSE for details.
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found