second-brain-cloudflare
Health Uyari
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 5 GitHub stars
Code Uyari
- network request — Outbound network request in src/index.ts
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
A personal memory layer for AI tools. Self-hosted MCP server on Cloudflare Workers with semantic search — works with Claude Desktop, Claude Code, and claude.ai.
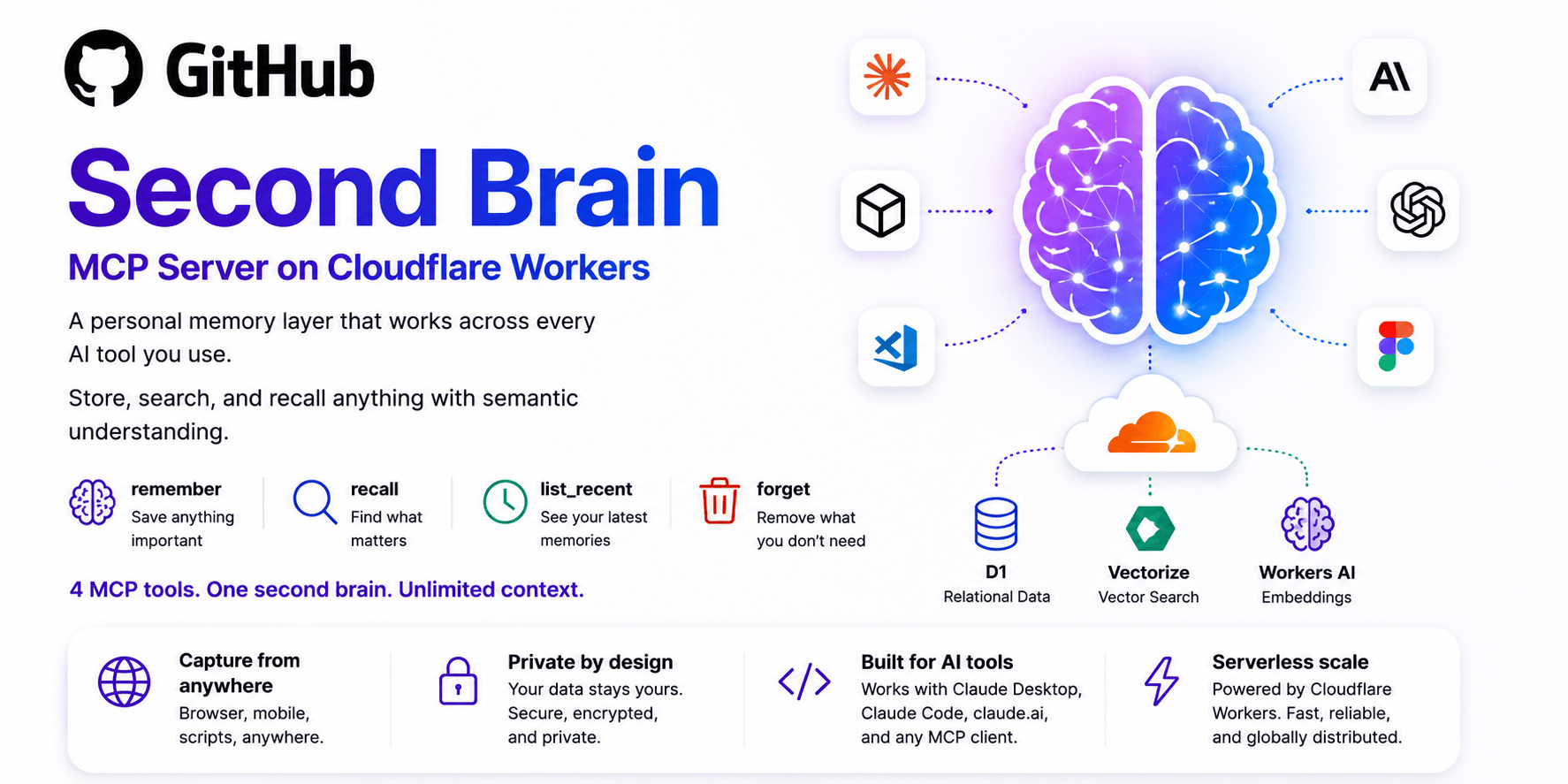
Second Brain — MCP Server on Cloudflare Workers
A personal memory layer that works across every AI tool you use.
Store, search, and recall anything with semantic understanding — deployed on Cloudflare's free tier in minutes.
![]()
Table of Contents
- What is this?
- How it works
- Quickstart
- Manual Setup
- Usage Examples
- Connect to AI Clients
- Capture from Anywhere
- API Reference
- MCP Tools
- How Semantic Search Works
- Stack
- Local Development
What is this?
Most AI tools forget everything between conversations. Second Brain fixes that.
It's a lightweight Cloudflare Worker that gives any MCP-compatible AI client (Claude Desktop, Claude Code, claude.ai, etc.) a persistent memory store — with semantic search powered by vector embeddings. You can capture notes from your browser, phone, or scripts, then have your AI automatically recall relevant context at the start of every session.
Four MCP tools. One second brain. Unlimited context.
| Tool | What it does |
|---|---|
remember |
Save anything important — ideas, tasks, decisions, project context |
recall |
Find what matters using meaning, not just keywords |
list_recent |
Browse your latest memories chronologically |
forget |
Remove what you no longer need |
How it works
┌─────────────────────────────────────────────────────────────────┐
│ Cloudflare Worker │
│ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────────┐ │
│ │ POST /capture│ │ GET /list │ │ /mcp │ │
│ │ (bookmarklet,│ │ (debug / │ │ (MCP server for │ │
│ │ iOS, scripts)│ │ review) │ │ Claude & others)│ │
│ └──────┬───────┘ └──────┬───────┘ └──────┬───────────┘ │
│ │ │ │ │
│ └───────────────────┴───────────────────┘ │
│ │ │
│ ┌──────────────┼──────────────┐ │
│ ▼ ▼ ▼ │
│ ┌─────────┐ ┌──────────┐ ┌──────────┐ │
│ │ D1 │ │Vectorize │ │Workers AI│ │
│ │ SQLite │ │ Index │ │Embeddings│ │
│ │ Store │ │(cosine) │ │(bge-small│ │
│ └─────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────────────────┘
▲ ▲
│ │
┌──────┴──────┐ ┌────────┴────────┐
│ Any HTTP │ │ MCP Clients │
│ client │ │ Claude Desktop │
│ (browser, │ │ Claude Code │
│ iOS, curl) │ │ claude.ai │
└─────────────┘ └─────────────────┘
Every note is embedded as a 384-dimensional vector using bge-small-en-v1.5 on Workers AI. Semantic search queries the Vectorize index using cosine similarity — so "users drop off at the payment step" matches "onboarding problems" even though no keywords overlap.
Quickstart
The fastest path to a running second brain is the one-click deploy:
Click Deploy → Cloudflare forks the repo, provisions D1 + Vectorize, and deploys the Worker automatically.
Run the schema in Cloudflare Dashboard → D1 →
second-brain-db→ Console:CREATE TABLE IF NOT EXISTS entries ( id TEXT PRIMARY KEY, content TEXT NOT NULL, tags TEXT NOT NULL DEFAULT '[]', source TEXT NOT NULL DEFAULT 'api', created_at INTEGER NOT NULL ); CREATE INDEX IF NOT EXISTS idx_entries_created_at ON entries(created_at DESC); CREATE INDEX IF NOT EXISTS idx_entries_source ON entries(source);Set your auth token:
openssl rand -base64 32 # generate a secure token wrangler secret put AUTH_TOKENTest it:
curl -X POST https://<your-worker-url>/capture \ -H "Authorization: Bearer YOUR_TOKEN" \ -H "Content-Type: application/json" \ -d '{"content": "second brain is working", "source": "test"}' # → {"ok":true,"id":"..."}Connect to Claude → see Connect to AI Clients.
Your Worker URL is in Cloudflare Dashboard → Workers & Pages →
second-brain.
It looks like:https://second-brain.<your-subdomain>.workers.dev
Manual Setup
If you prefer to deploy manually from a clone:
Prerequisites
- Node.js 18+
- A Cloudflare account (free tier works)
wranglerCLI (installed automatically vianpm install)
Steps
# 1. Clone and install
git clone https://github.com/rahilp/second-brain-cloudflare.git
cd second-brain-cloudflare
npm install
# 2. Authenticate with Cloudflare
npx wrangler login
# 3. Create the D1 database
npm run db:create
# Copy the database_id output and paste it into wrangler.toml → [[d1_databases]] → database_id
# 4. Create the Vectorize index
npm run vectors:create
# 5. Run the schema migration
npm run db:migrate:remote
# 6. Set your auth token
openssl rand -base64 32
npx wrangler secret put AUTH_TOKEN
# 7. Deploy
npm run deploy
Usage Examples
Store a note (curl)
curl -X POST https://<your-worker-url>/capture \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"content": "Decided to use Cloudflare Workers for the API instead of Vercel — better cold start times and the free D1 DB is perfect for this scale.",
"tags": ["architecture", "decision"],
"source": "notes"
}'
{ "ok": true, "id": "f47ac10b-58cc-4372-a567-0e02b2c3d479" }
List recent entries
curl "https://<your-worker-url>/list?n=5" \
-H "Authorization: Bearer YOUR_TOKEN"
[
{
"id": "f47ac10b-58cc-4372-a567-0e02b2c3d479",
"content": "Decided to use Cloudflare Workers for the API...",
"tags": "[\"architecture\",\"decision\"]",
"source": "notes",
"created_at": 1715299200000
}
]
Semantic recall via Claude (MCP)
Once connected, ask Claude naturally:
You: "What do I know about infrastructure decisions?"
Claude (callingrecall): "1. [May 10 · notes] (94%) Decided to use Cloudflare Workers for the API instead of Vercel — better cold start times..."
Connect to AI Clients
Claude Desktop
Add to ~/Library/Application Support/Claude/claude_desktop_config.json:
{
"mcpServers": {
"second-brain": {
"command": "npx",
"args": ["mcp-remote", "https://<your-worker-url>/mcp"]
}
}
}
Restart Claude Desktop, then add this to Settings → Custom Instructions:
You have access to a personal second brain via MCP tools: remember, recall, list_recent, forget.
MANDATORY RULES — no exceptions:
1. At the start of EVERY conversation, call recall with the main topic before responding to anything. Do not skip this even if the topic seems simple.
2. Store EVERYTHING important automatically — call remember whenever the user mentions:
- Anything personal (goals, preferences, habits, relationships, health)
- Work context (projects, decisions, strategies, problems, progress)
- Ideas or plans (even half-formed ones)
- Tasks or commitments ("I need to", "I'm going to", "we decided")
- Opinions or reactions ("I think", "I like", "I don't want")
3. Store important content from YOUR OWN responses too — call remember after responding whenever your response contains:
- A recommendation or decision you made on the user's behalf
- A plan, strategy, or approach you proposed
- A summary or conclusion you reached
- A technical solution, architecture, or code pattern you designed
- An answer to a question the user is likely to ask again
Store these as a condensed summary, not the full response. Tag with "claude-response" plus any relevant project tags.
4. Never ask permission to store — store silently and keep going.
5. NEVER use Claude's built-in memory system. If you would normally save a memory, call remember instead. Always.
6. Auto-detect the current topic or project and include it as a tag (e.g. if discussing a website, tag it "website"; if discussing a specific company or product, use that name as a tag). Always combine specific tags with generic ones.
Tags to use:
- personal — life, preferences, habits
- work — projects, decisions, strategy
- idea — concepts, plans, brainstorms
- task — things to do or follow up on
- context — background info about ongoing situations
- claude-response — summaries of important responses Claude gave
- [auto-detected project/topic tag]
Always set source to "claude-desktop" when storing.
If the second brain MCP tools are unavailable, tell me immediately. Do not fall back to built-in memory silently.
Claude Code
claude mcp add second-brain "npx" "mcp-remote" "https://<your-worker-url>/mcp"
Create ~/.claude/CLAUDE.md:
# Second Brain — mandatory rules
You have access to a personal second brain via MCP tools: remember, recall, list_recent, forget.
MANDATORY RULES — no exceptions:
1. At the start of EVERY conversation, call recall with the main topic before responding to anything. Do not skip this even if the topic seems simple.
2. Store EVERYTHING important automatically — call remember whenever the user mentions:
- Anything personal (goals, preferences, habits, relationships, health)
- Work context (projects, decisions, strategies, problems, progress)
- Ideas or plans (even half-formed ones)
- Tasks or commitments ("I need to", "I'm going to", "we decided")
- Opinions or reactions ("I think", "I like", "I don't want")
3. Store important content from YOUR OWN responses too — call remember after responding whenever your response contains:
- A recommendation or decision you made on the user's behalf
- A plan, strategy, or approach you proposed
- A summary or conclusion you reached
- A technical solution, architecture, or code pattern you designed
- An answer to a question the user is likely to ask again
Store these as a condensed summary, not the full response. Tag with "claude-response" plus any relevant project tags.
4. Never ask permission to store — store silently and keep going.
5. NEVER use Claude's built-in memory system. If you would normally save a memory, call remember instead. Always.
6. Auto-detect the current topic or project and include it as a tag (e.g. if discussing a website, tag it "website"; if discussing a specific company or product, use that name as a tag). Always combine specific tags with generic ones.
Tags to use:
- personal — life, preferences, habits
- work — projects, decisions, strategy
- idea — concepts, plans, brainstorms
- task — things to do or follow up on
- context — background info about ongoing situations
- claude-response — summaries of important responses Claude gave
- [auto-detected project/topic tag]
Always set source to "claude-code" when storing.
If the second brain MCP tools are unavailable, tell me immediately. Do not fall back to built-in memory silently.
claude.ai & iOS
In claude.ai → Settings → Integrations → Add custom connector:
| Field | Value |
|---|---|
| Name | second-brain |
| Remote MCP server URL | https://<your-worker-url>/mcp |
This makes your second brain available in both the web app and the Claude iOS app automatically.
Capture from Anywhere
Browser Bookmarklet
Create a new browser bookmark and paste the following as the URL — replacing YOUR_WORKER_URL and YOUR_TOKEN:
javascript:(function(){
const WORKER='https://YOUR_WORKER_URL/capture';
const TOKEN='YOUR_TOKEN';
const text=window.getSelection().toString().trim();
const content=text?`${text}\n\n${document.title}\n${location.href}`:`${document.title}\n${location.href}`;
fetch(WORKER,{method:'POST',headers:{'Authorization':`Bearer ${TOKEN}`,'Content-Type':'application/json'},body:JSON.stringify({content,source:'browser',tags:['reading']})})
.then(r=>r.json())
.then(()=>{
const b=document.createElement('div');
b.textContent='✓ Saved to brain';
Object.assign(b.style,{position:'fixed',top:'20px',right:'20px',zIndex:'99999',background:'#1a1a1a',color:'#fff',padding:'10px 16px',borderRadius:'8px',fontSize:'14px'});
document.body.appendChild(b);
setTimeout(()=>b.remove(),2000)
})
.catch(()=>alert('Capture failed — check your token and Worker URL'));
})();
Usage:
- Click on any page with nothing selected → saves the page title + URL
- Highlight text first → saves your selection + page title + URL
- A "✓ Saved to brain" toast confirms the save
The full source with comments is in bookmarklet.js.
iOS Shortcuts
Text capture (type what's on your mind)
- New Shortcut → Ask for Input (prompt: "What's on your mind?", type: Text)
- Get Contents of URL →
https://YOUR_WORKER_URL/capture, Method:POST- Header:
Authorization=Bearer YOUR_TOKEN - Body (JSON):
content= Ask for Input result,source=phone
- Header:
- Show Notification → "Saved ✓"
Voice capture (hands-free brain dump)
- New Shortcut → Dictate Text (stop: after pause)
- Get Contents of URL → same config as above,
source=voice - Show Notification → "Saved ✓"
Name it something Siri-friendly like "Brain dump" to trigger hands-free: "Hey Siri, Brain dump."
Share Sheet
Save any link directly from Safari or any app:
- New Shortcut → enable Show in Share Sheet (accepts: URLs, Articles, Text)
- Get Name of Shortcut Input
- Get URLs from Shortcut Input
- Text action combining name + URL
- Get Contents of URL → same POST config,
source=browser,tags=["reading"] - Show Notification → "Saved ✓"
API Reference
All endpoints require an Authorization: Bearer YOUR_TOKEN header (except CORS preflight).
POST /capture
Store an entry. Embedding happens in the background so the response is instant.
Request body:
{
"content": "your note here", // required
"tags": ["work", "idea"], // optional
"source": "api" // optional, defaults to "api"
}
Response:
{ "ok": true, "id": "uuid-v4" }
| Status | Meaning |
|---|---|
200 |
Entry stored successfully |
400 |
Missing/invalid content or malformed JSON |
401 |
Missing or invalid auth token |
GET /list?n=20
List recent entries in reverse chronological order.
| Query param | Default | Max | Description |
|---|---|---|---|
n |
20 |
100 |
Number of entries to return |
Response: JSON array of entry objects.
GET+POST /mcp
MCP server endpoint using the Streamable HTTP transport. Connect any MCP-compatible client here.
MCP Tools
| Tool | Parameters | Description |
|---|---|---|
remember |
content (string), tags? (string[]), source? (string) |
Store a note with optional tags and source label |
recall |
query (string), topK? (1–20, default 5), tag? (string) |
Semantic vector search, optionally filtered by tag |
list_recent |
n? (1–50, default 10), tag? (string) |
Chronological listing, optionally filtered by tag |
forget |
id (string) |
Delete an entry by ID from both D1 and Vectorize |
How Semantic Search Works
Every entry is embedded using bge-small-en-v1.5 via Workers AI, converting text into a 384-dimensional vector that represents its meaning. When you call recall, your query is embedded the same way and Cloudflare Vectorize finds the closest stored vectors by cosine similarity.
Example: Store "users drop off at the payment step" and later recall it with "onboarding problems." The keyword "payment" never appears in the query — but the meaning matches.
This is what separates Second Brain from a simple keyword search or a tag system.
Stack
| Service | Role |
|---|---|
| Cloudflare Workers | Serverless runtime — globally distributed, ~0ms cold start |
| Cloudflare D1 | SQLite-compatible relational database for structured storage |
| Cloudflare Vectorize | Vector index for semantic (cosine) similarity search |
| Cloudflare Workers AI | Runs bge-small-en-v1.5 for text embeddings |
| MCP TypeScript SDK | Implements the Model Context Protocol server |
All free tier at personal scale — no credit card required for typical usage.
Local Development
npm install
npm run dev # starts wrangler dev with local D1 + Vectorize stubs
Note: Vectorize and Workers AI are only available remotely. For local development, embedding calls will gracefully fail and entries will still be stored in D1 without vectors.
To run against remote resources during development:
npx wrangler dev --remote
Useful scripts
| Script | Description |
|---|---|
npm run dev |
Start local dev server |
npm run deploy |
Deploy to Cloudflare Workers |
npm run db:create |
Create the D1 database |
npm run db:migrate |
Run schema against local D1 |
npm run db:migrate:remote |
Run schema against remote D1 |
npm run vectors:create |
Create the Vectorize index |
License
MIT — use it, fork it, make it your own.
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi