cashew
Health Warn
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 9 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
This tool provides a persistent, local memory system for AI agents. It uses a local SQLite database and vector search to store, recall, and autonomously connect knowledge across different sessions.
Security Assessment
The automated code scan found no dangerous patterns, hardcoded secrets, or requests for risky permissions. Because it ingests user data (like Obsidian vaults) to build its memory graph, it accesses personal files locally, but there are no signs of unauthorized network requests or hidden shell command executions. Overall risk: Low.
Quality Assessment
The project is very new and has low community visibility, currently sitting at only 9 GitHub stars. However, it is actively maintained (with recent pushes) and is protected by a standard MIT license. The documentation is thorough and includes a clear architectural breakdown, suggesting a well-intentioned and structured project by the developer.
Verdict
Safe to use, though its very low community adoption means you bear the responsibility for ongoing maintenance and deep security reviews.
Persistent memory for AI agents. Extract once, recall forever.
Cashew 🥜
Persistent thought-graph memory for AI agents.
The name comes from asking "do cats eat cashews?" — a question I asked my aunt as a 10-year-old kid in India, because the cashews were left open in the kitchen and I knew stray cats sneak into homes to eat food. My family still brings it up every time I visit. I never stopped asking questions. This system doesn't either — autonomous think cycles find connections you didn't know existed.
📝 Blog post: I Built My AI a Brain and It Started Thinking for Itself
Architecture
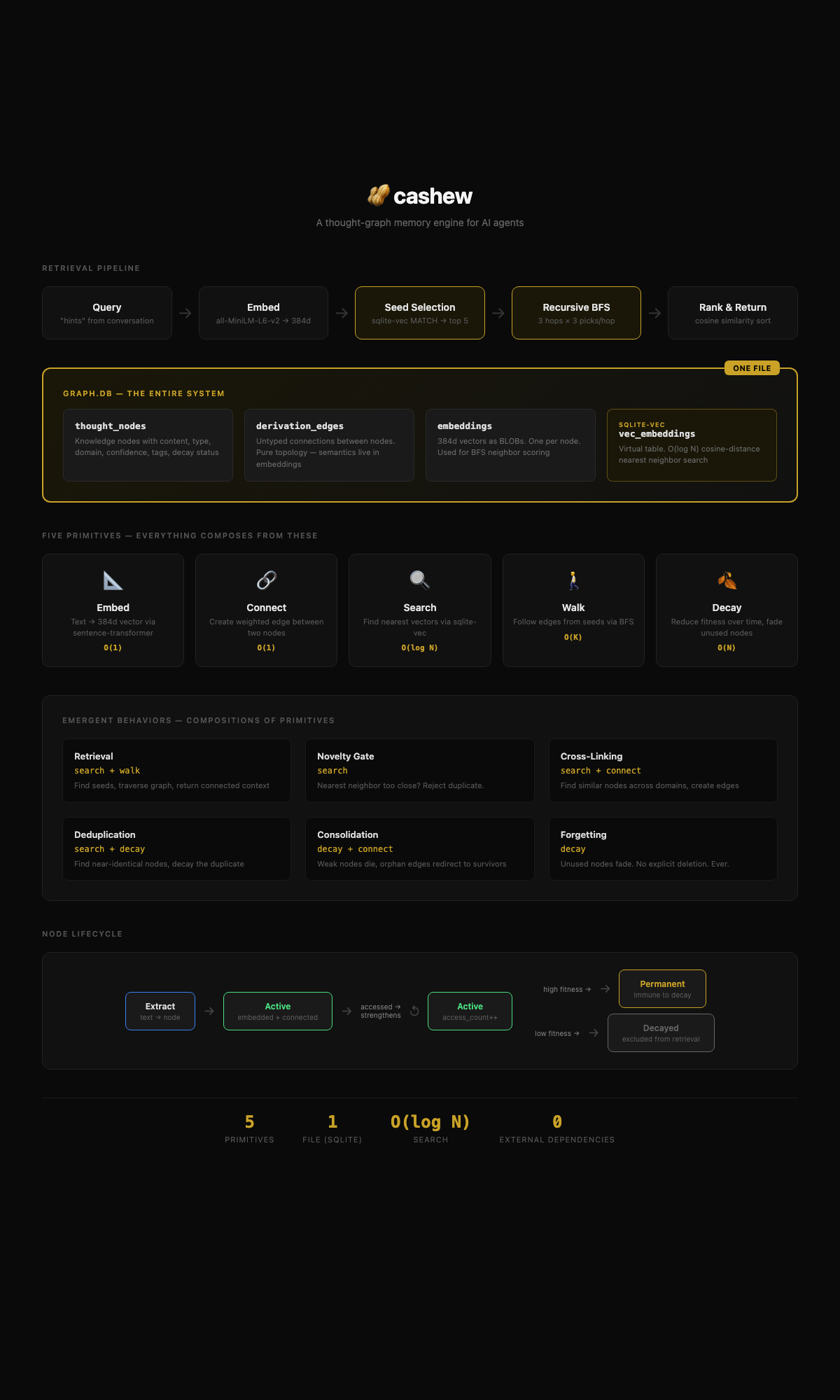
What It Does
- Remembers across sessions. Decisions, patterns, relationships, and project context survive compaction and restart. Your agent picks up where it left off.
- Learns autonomously. Think cycles find cross-domain connections without prompting. A pattern in your work habits connects to a pattern in your communication style — the brain surfaces it.
- Stays fast at scale. sqlite-vec for O(log N) retrieval, recursive BFS graph walk, constant context cost regardless of graph size. 3,000 nodes costs the same as 300.
What If Forgetting Is the Intelligence?
Cashew doesn't hoard everything. Organic decay means low-value knowledge fades naturally while important patterns strengthen through use. No manual curation needed — the graph self-organizes through cross-linking and natural selection. See PHILOSOPHY.md for the full manifesto.
Quick Start
pip install cashew-brain
cashew init
cashew context --hints "test"
That's it. Your brain is empty but ready. Start extracting knowledge:
echo "I prefer TypeScript over JavaScript for complex projects" | cashew extract --input -
Query it back:
cashew context --hints "programming language preferences"
Integration
Claude Code
Copy the skill into your personal skills directory:
# From the cashew repo
cp -r skills/claude-code/ ~/.claude/skills/cashew/
This gives you the /cashew slash command and automatic context loading. Claude Code will query your brain before answering substantive questions and extract knowledge during conversations.
Or if you cloned the repo, just open it in Claude Code — the .claude/skills/cashew/ directory auto-discovers.
OpenClaw
Install as an OpenClaw skill for full automation — cron jobs handle extraction, think cycles, and dashboard deployment without manual intervention. See skills/openclaw/SKILL.md for setup instructions.
Ingest Sources
Cashew ships with built-in extractors for common knowledge sources. Each one handles checkpointing, incremental updates, and deduplication automatically.
Obsidian vault:
cashew ingest obsidian /path/to/vault
Parses YAML frontmatter (tags, aliases, dates), follows [[wikilinks]] to create edges between related notes, respects .obsidianignore, and auto-detects domains from your folder structure. Your second brain becomes your AI's brain.
OpenClaw session logs:
cashew ingest sessions /path/to/sessions/
Extracts knowledge from conversation history. Tracks how far into each session file it's read, so growing sessions get incrementally processed. Filters out tool calls and system messages.
Markdown directory:
cashew ingest markdown /path/to/notes/
General purpose extractor for any directory of .md files. Respects .cashewignore for excluding files.
Options:
cashew ingest --list # Show available extractors
cashew ingest obsidian /path --no-llm # Skip LLM, use paragraph splitting fallback
All extractors use LLM-based extraction by default for richer, typed knowledge (decisions, insights, facts). Use --no-llm for offline or token-free ingestion.
Python API
from core.context import ContextRetriever
from core.embeddings import load_embeddings
# Query context
embeddings = load_embeddings("path/to/graph.db")
retriever = ContextRetriever("path/to/graph.db", embeddings)
context = retriever.generate_context(hints=["work", "projects"])
Architecture
- Single SQLite file. No external servers, no separate indexes. Your entire brain is one portable file.
- Local embeddings. all-MiniLM-L6-v2 (384 dims). Downloads ~500MB on first run, then runs locally forever. No API calls for retrieval.
- LLM for intelligence. Extraction and think cycles need an LLM (Claude, GPT, etc). Retrieval and storage don't. Bring your own via
model_fnparameter or API key. - Retrieval. sqlite-vec seeds (O(log N) nearest neighbor) → recursive BFS graph walk (seeds=5, picks_per_hop=3, max_depth=3). The graph's organic connectivity provides implicit hierarchy — no synthetic summary nodes needed.
- Organic decay. Nodes that aren't accessed lose fitness over time. Low-fitness nodes get marked decayed and excluded from retrieval. The graph forgets what doesn't matter.
CLI Reference
| Command | Purpose |
|---|---|
cashew init |
Initialize a new brain |
cashew context --hints "..." |
Retrieve relevant context |
cashew extract --input file.md |
Extract knowledge from text |
cashew ingest obsidian /path |
Ingest an Obsidian vault |
cashew ingest sessions /path |
Ingest OpenClaw session logs |
cashew ingest markdown /path |
Ingest a directory of markdown files |
cashew think |
Run a think cycle |
cashew sleep |
Full sleep cycle (consolidation) |
cashew stats |
Graph statistics |
cashew dashboard |
Launch the live dashboard (graph + BFS search visualization) |
Dashboard
cashew dashboard --db data/graph.db --port 8765
# then open http://127.0.0.1:8765
A minimalist browser UI over the brain. The full graph renders as a canvas force layout colored by node type. The search box traces a live recursive-BFS walk: seeds arrive first, then each hop lights up in order with hop-colored edges and rings. Works on mobile (bottom sheet, drag-to-resize). Pass --host 0.0.0.0 to expose on the LAN. Auto-trigger a search via ?q=... in the URL.
Warm Daemon
Every CLI invocation normally loads the sentence-transformer model from scratch (~2s cold start). For a responsive query loop, run the warm daemon once and every call routes through it automatically — no code changes in consumers.
# Foreground (development)
cashew serve
# Persistent (macOS)
cp packaging/com.cashew.daemon.plist ~/Library/LaunchAgents/
# edit CASHEW_PATH in the plist to match your clone, then:
launchctl load ~/Library/LaunchAgents/com.cashew.daemon.plist
The daemon listens on ~/.cashew/daemon.sock. A content-hash embedding cache at ~/.cashew/embedding_cache.db makes repeat embeds free, keyed by (model_version, sha256(text)) — deterministic, so no invalidation logic is needed beyond model swaps.
Every entry point (context, extract, think, sleep cycles) checks the cache first, then the daemon, then falls back to in-process embedding if the daemon is down. Clients never need to know which path served them.
Requirements
- Python 3.10+
- ~2GB RAM (for embedding model)
- ~500MB disk (embedding model, downloaded on first use)
- An LLM API key for extraction and think cycles (optional for retrieval-only use)
Philosophy
Cashew ships with a philosophy document that defines how a brain-equipped agent should operate. It covers brain sovereignty, evidence over defaults, the sponge principle, cross-domain vision, and why divergence between instances is the whole point.
Read it: PHILOSOPHY.md
Development
git clone https://github.com/rajkripal/cashew.git
cd cashew
pip install -e ".[dev]"
pytest
See CLAUDE.md for the developer guide — architecture, schema, conventions, and engineering philosophy.
License
MIT — see LICENSE.
Built by rajkripal.
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found