brick-SR1
Health Gecti
- License — License: Apache-2.0
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 10 GitHub stars
Code Uyari
- process.env — Environment variable access in apps/cli/bin/dev.js
- process.env — Environment variable access in apps/cli/scripts/validate-onboarding.mjs
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
brick is a smart AI Models router, based on complexity & capabilities extraction from the query to the models via proprietary spatial embedding algorythm
One Query, One Endpoint, Every LLM on Earth.
Brick is a Mixture-of-Models (MoM) routing gateway. It reads each prompt's
capability and complexity, then routes it to the best backend in a pool of
open- and closed-weight LLMs, matching the strongest single model's quality at a
fraction of its cost. No cascades. No wasted calls. Drop-in model: "brick".




Quickstart · Why Brick · Claude Code · Usage · FAQ · Benchmarks · How it works · Paper
⚡ Quickstart
The fastest working path today is the CLI, which self-hosts the router and wires it into
Claude Code for you. Requires Node >= 18 and Docker.
git clone https://github.com/regolo-ai/brick-SR1.git
cd brick-SR1/apps/cli && npm install && npm run build && npm link
brick claude on # starts the router + wires ANTHROPIC_BASE_URL in ~/.claude/settings.json
Then open a new Claude Code session and pick brick-claude in the /model picker.
Every request now routes to haiku / sonnet / opus by capability and complexity. See
Brick + Claude Code for modes, the effort picker, and the livebrick claude status dashboard.
Once the Docker image is published (see Distribution channels), you'll
be able to run the gateway directly:
docker run --rm -p 18000:18000 \
-e REGOLO_API_KEY=$REGOLO_API_KEY \
ghcr.io/regolo-ai/brick:latest # published at the next v2.1.0 tag
Then call it like any OpenAI endpoint, just set "model": "brick":
curl http://localhost:18000/v1/chat/completions \
-H "Authorization: Bearer $REGOLO_API_KEY" \
-H "Content-Type: application/json" \
-d '{"model":"brick","messages":[{"role":"user","content":"Prove that sqrt(2) is irrational"}]}'
The x-selected-model response header tells you which backend Brick picked.
That math prompt routes to a reasoning model; "Hello" routes to the cheapest one.
Until then, brick serve (from the CLI above) runs the same router locally from source.
🤔 Why Brick
| Single model | RouteLLM | FrugalGPT / Cascade | Brick | |
|---|---|---|---|---|
| One call per query (no cascade waste) | ✅ | ✅ | ❌ | ✅ |
| Capability-aware (6 dimensions) | n/a | ❌ binary | ❌ | ✅ |
| Complexity-aware | n/a | partial | ✅ | ✅ |
| Pool of N open + closed models | n/a | 2 | few | ✅ |
| Continuous cost ↔ quality knob | ❌ | ❌ | threshold | ✅ r ∈ [-1, 1] |
| Native multimodal (image / audio) | varies | ❌ | ❌ | ✅ |
| Drop-in OpenAI-compatible | n/a | n/a | n/a | ✅ |
Cascade routers (FrugalGPT, Cascade Routing) call models one after another until a
confidence check passes, paying for every miss in tokens and latency. Brick makes a
single forward decision per query, so there is nothing to waste.
🚀 Two ways to use Brick
A. Run the gateway (Docker)
A raw OpenAI-compatible endpoint, no CLI. See the Quickstart and docs/quickstart/quick.md. (The published image ships at the next v2.1.0 tag; until then use brick serve from path B.)
B. CLI: self-host in one command
git clone https://github.com/regolo-ai/brick-SR1.git
cd brick-SR1/apps/cli && npm install && npm run build && npm link
brick init # guided wizard → ~/.brick/profiles/<name>/
brick serve # docker compose up
brick chat # TUI chat against http://localhost:18000
brick route "what is 2+2?" # show the routing decision for a prompt
Full walkthrough: docs/quickstart/serve.md · CLI reference: apps/cli/README.md.
🧠 Brick + Claude Code
https://github.com/user-attachments/assets/13c02f5b-191a-43cb-ad26-12ab6cb44f6a
Put one OpenAI/Anthropic-compatible endpoint in front of Claude Code, and Brick routes every request to haiku, sonnet, or opus based on capability and complexity. You keep the Claude Code UX; Brick picks the cheapest model that can do the job.
Setup
brick claude on # wires ANTHROPIC_BASE_URL in ~/.claude/settings.json, auto-starts the router
Then:
- Open a new Claude Code session (your current session is unaffected).
- In the
/modelpicker, select brick-claude (it sits alongside the built-in opus/sonnet/haiku aliases, which it does not replace).
To revert:
brick claude off # restores ANTHROPIC_BASE_URL, optionally stops the router
Use brick claude on --no-start to require an already-healthy router instead of auto-starting one, and brick claude off --stop / --keep to control the router without a prompt.
The 5 modes: pick your cost/quality trade-off
A mode is how you tell Brick how much to spend. Each one maps easy/medium/hard queries to a
model tier, from cheapest (eco, always haiku) to strongest (max, always opus). Pick one
and Brick handles the per-query routing inside it.
https://github.com/user-attachments/assets/396a41a2-822d-4916-a593-78e346ba5db9
| Mode | r | easy | medium | hard |
|---|---|---|---|---|
| eco | -1 | haiku | haiku | haiku |
| lite | -0.5 | haiku | haiku | sonnet |
| mid | 0 | haiku | sonnet | opus |
| pro | 0.5 | sonnet | sonnet | opus |
| max | 1 | opus | opus | opus |
Switch with brick claude mode or directly via brick claude <mode>. mid is the default.
On 1M-context requests the map shifts up since Haiku has no 1M variant: easy and medium
resolve to sonnet, hard to opus.
The effort picker just picks the mode
The effort slider in Claude Code's /model picker is a shortcut for choosing the Brick mode
(the model tier), not the thinking budget:
| Effort | Mode |
|---|---|
| low | eco |
| medium | lite |
| high | mid |
| xhigh | pro |
| max | max |
You pick the tier; how hard to think is then decided autonomously per request from the
router's own signals (query difficulty plus the chosen model's headroom).
Native models bypass the router
Selecting opus, sonnet, or haiku explicitly in the picker skips Brick entirely: the request is forwarded verbatim to that exact model, with no skill routing and no effort override. Only brick-claude runs the router.
Observability
brick claude status # live dashboard (default in an interactive terminal)
brick claude status --once # static one-shot view
The dashboard reports, since the last router restart:
- Routed by model: count and percent per model.
- Per-model effort distribution: how reasoning effort spread out within each model.
- Difficulty mix: the classifier's easy/medium/hard verdicts across routed requests.
- Economy: an estimated
saved ~X% vs all-opusover the routed request count (a relative estimate from request mix, excluding real token counts and caching).
It also shows connection/wiring state, classifier latency (avg, p50, p95), and fallback rate.
Works with workflows and subagents
Brick routing is per request. In Claude Code workflows and subagents, each agent's call is routed independently as long as that agent uses brick-claude, so a cheap subagent task can land on haiku while a hard one escalates to opus in the same run.
🗂️ What's in the repo
A monorepo to run, use, and reproduce every result in the Brick paper.
| Component | Path | Purpose |
|---|---|---|
| Router (Go + Rust) | apps/router/ |
OpenAI-format gateway: capability + complexity classifiers, dispatch to the best backend |
CLI (brick) |
apps/cli/ |
TypeScript/oclif companion to self-host in one command |
| Training | packages/training/ |
ModernBERT capability sweep + complexity LoRA recipes |
| Evaluation | packages/evals/ |
Dataset A pipeline + 3-judge majority-vote panel |
| Baselines | packages/evals/baselines/ |
Zero-shot RouteLLM, FrugalGPT, Cascade comparisons |
| Paper | docs/paper/ |
LaTeX source, figures, compiled PDF |
brick-SR1/
├── apps/
│ ├── router/ # Go + Rust gateway (was vLLM Spatial Router fork)
│ │ ├── src/spatial-router/ # Go (HTTP proxy, routing pipeline)
│ │ ├── candle-binding/ # Rust (ML embeddings via candle)
│ │ ├── ml-binding/ # Rust (Linfa classical ML)
│ │ ├── nlp-binding/ # Rust (BM25 + n-gram)
│ │ └── Dockerfile
│ └── cli/ # @regolo-ai/brick CLI (TypeScript + oclif + ink)
├── packages/
│ ├── training/ # Dataset B pipeline + ModernBERT/complexity training
│ ├── evals/ # Dataset A graders + 00..140 pipeline + baselines/
│ └── datasets/ # HF download recipes (no data in git)
├── docs/
│ ├── paper/ # paper.tex + figures + compiled PDF
│ └── quickstart/ # quick.md, serve.md, eval.md
├── deploy/ # docker-compose, addons, Windows installer
├── config.yaml # router runtime config
├── package.json / pyproject.toml # npm + uv workspace roots
└── Makefile # build / test / lint / docker-build / release
🛠️ Develop
make install # npm install (apps/cli) + uv sync (packages/*)
make build # CLI + router Docker image
make test # Go tests + Python pytest + CLI vitest
make lint # pre-commit run --all-files
Per-component docs: router · CLI · training · evals · datasets · baselines.
Distribution channels (work in progress)| Channel | Status |
|---|---|
Source clone + npm link |
available |
Docker GHCR (ghcr.io/regolo-ai/brick) |
pending first push (tag v2.1.0) |
npm (@regolo-ai/brick) |
pending NPM_TOKEN secret |
Docker Hub mirror (docker.io/regolo/brick) |
pending Docker Hub secrets |
❓ FAQ
How is Brick different from a cascade router like FrugalGPT?A cascade calls models in sequence (cheap first, escalate on low confidence) and pays for every miss in tokens and latency. Brick makes a single forward decision per query from a capability vector and a complexity score, so there is no wasted call. See Why Brick.
Which backend did Brick pick for my request?Read the x-selected-model response header. Every /v1/chat/completions and /v1/messages response carries it.
Slide the r knob in r ∈ [-1, 1]. At r = -1 Brick favors the cheapest capable model (max-saving), at r = 1 it favors the strongest (max-quality). For Claude Code the same idea is exposed as 5 named modes, see the 5 modes.
No. The router and both classifiers run on CPU. GPUs only matter if you self-host the backend LLMs; with a hosted pool (Regolo, Anthropic, etc.) a CPU box is enough.
Can I use my own model pool?Yes. The pool, per-model skill vectors, costs, and the model_map live in config.yaml (skill_router.models). Add or swap any OpenAI-compatible backend. See apps/router/README.md.
That error comes from the backend provider, not Brick. Check the credential you forward (REGOLO_API_KEY or your own key); Brick passes Authorization through unchanged.
🤝 Contributing
Contributions are welcome. The short loop:
make install # deps for CLI + Python workspaces
make test # Go + pytest + vitest, run before opening a PR
make lint # pre-commit run --all-files
- Open an issue to discuss non-trivial changes first.
- Branch from
main, keep commits focused, follow the existing style of the files you touch. - Make sure
make testandmake lintpass. - Open a PR with a clear description of the what and the why.
For architecture and per-component conventions, start from What's in the repo and the component READMEs linked under Develop.
🔬 Paper & experiments
Everything below reproduces the research behind Brick: the benchmark numbers, the
routing algorithm, the datasets and models, and the paper itself.
📊 Results (Dataset A, n=5,504)
Brick sits on the Pareto frontier of cost vs quality, dominating single-model
baselines and prior routers (RouteLLM, FrugalGPT, Cascade Routing) and approaching
the oracle ceiling.
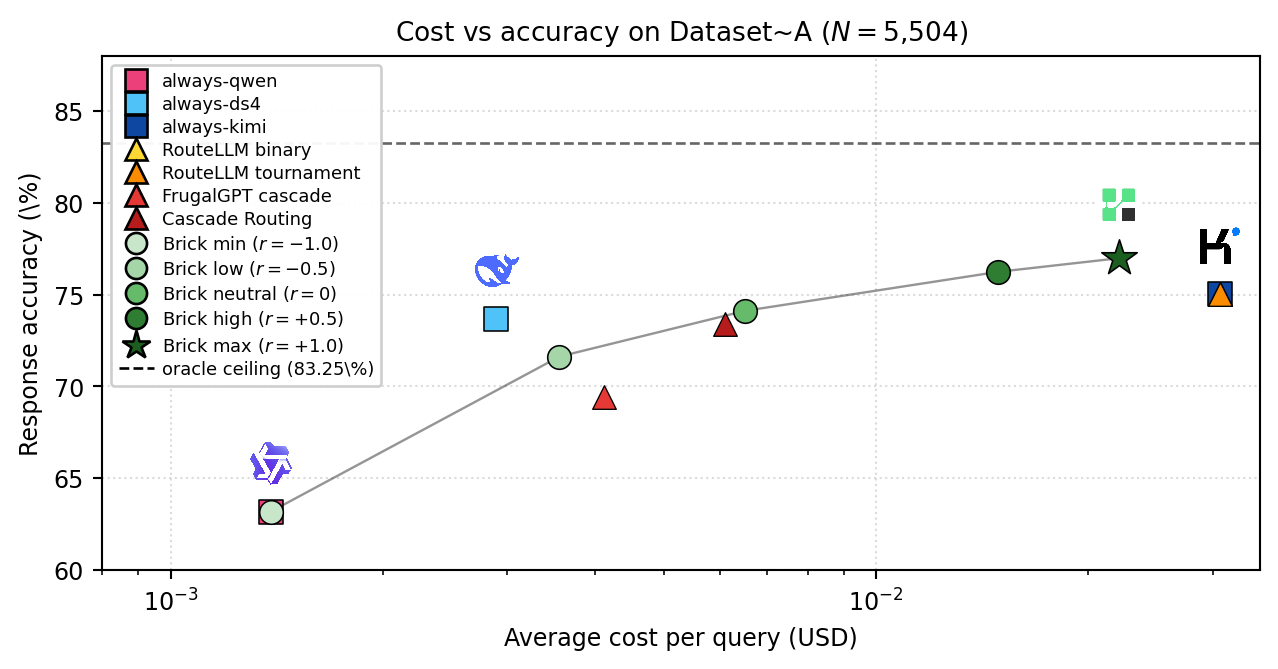
| Setting | Accuracy | Cost (× cheapest) | Latency (avg) |
|---|---|---|---|
| Always Qwen3.5-9b | 65.4% | 1.0× | 8.1 s |
| Always DeepSeek-v4-flash | 71.2% | 4.0× | 14.7 s |
| Always Kimi2.6 | 75.02% | 6.0× | 51.2 s |
| Brick (max-quality) | 76.98% | 1.5× | 22.8 s |
| Brick (max-saving) | 72.4% | 1.0× | 9.4 s |
| Oracle bound (3-model pool) | 83.25% | n/a | n/a |
Brick beats always-Kimi at ~4× lower cost and roughly half the latency.
Inter-rater agreement on the 3-judge eval panel: κ = 0.761. Full per-dimension
breakdown and baseline reproduction in packages/evals/baselines/RESULTS.md.
🧠 How it works
For every request the router computes a capability vector and a complexity
score, then picks the model whose skill profile is closest to what the query needs.
flowchart LR
Q([Query]) --> C[Capability classifier<br/>ModernBERT → p(x) ∈ Δ⁶]
Q --> X[Complexity classifier<br/>Qwen3.5-0.8B + LoRA → τ]
C --> R{{Skill-distance argmin<br/>Jₘ = Dₘ + β·aₘ}}
X --> R
R --> M1[qwen3.5-9b]
R --> M2[deepseek-v4-flash]
R --> M3[kimi2.6]
The query and each model live as vectors in the same capability space. The winner is
the model whose skill vector is nearest to the query's needs, biased by a cost term:
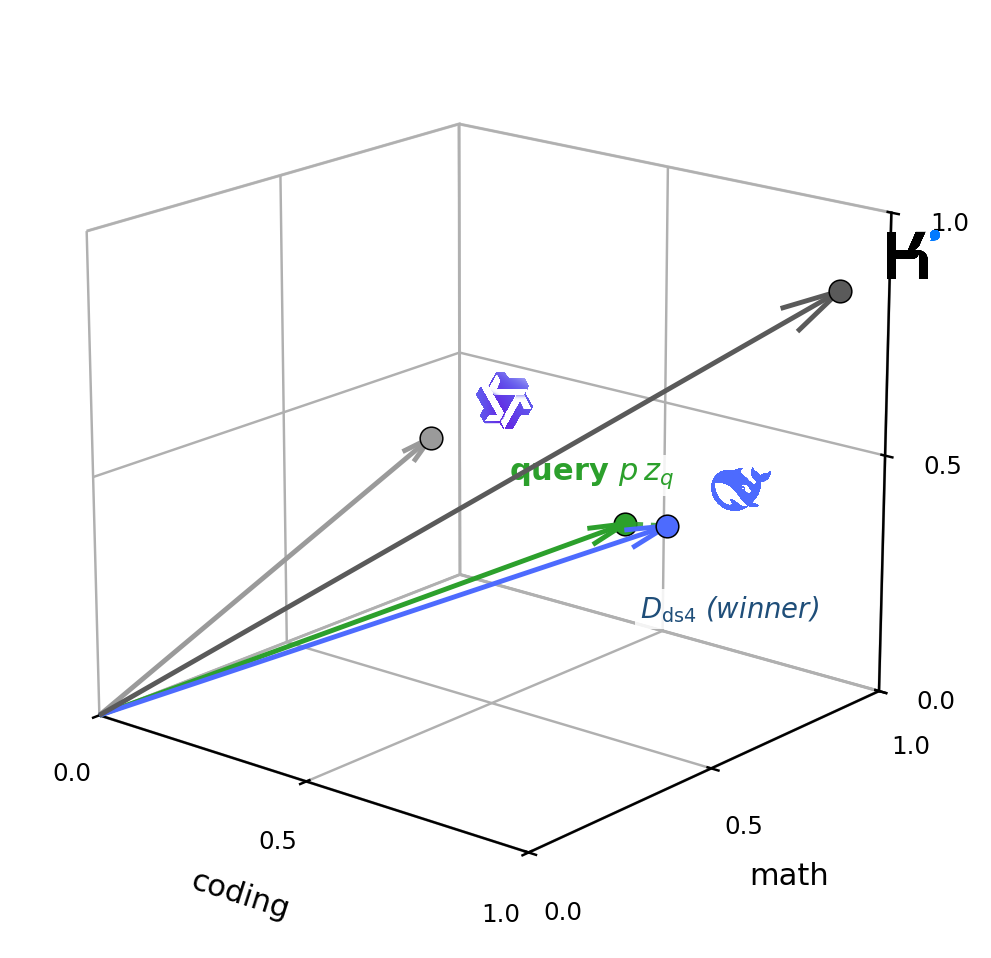
- Capability
p(x) ∈ Δ⁶: soft assignment overcoding,creative_synthesis,instruction_following,math_reasoning,planning_agentic,world_knowledge(brick-modernbert-capability-classifier). - Complexity
τ ∈ {easy, medium, hard}(brick-complexity-2-eco, Qwen3.5-0.8B + LoRA). - Objective per model:
Jₘ = Dₘ + β·aₘ, distanceDₘ = ‖p(x) − sₘ‖plus normalized costaₘ. - Argmin over the pool → selected backend. The
rknob slides the whole pool from max-saving to max-quality.
Multimodal inputs are preprocessed (OCR, Whisper-compatible STT) then routed as text, or
forwarded directly to a vision model. Details in apps/router/README.md and the paper §3.
🔁 Reproduce the paper
Full evaluation pipeline (Dataset A, 5,504 queries)git clone https://github.com/regolo-ai/brick-SR1 && cd brick-SR1
uv sync # Python workspaces
cd apps/cli && npm install && cd ../.. # CLI
# Download HF artifacts (datasets + models)
python packages/datasets/scripts/download_dataset_a.py --out ./data/dataset_a
python packages/datasets/scripts/download_models.py --out ./models
# Inference + grading
python packages/evals/scripts/100_run_inference.py --config packages/evals/configs/protocols.yaml
python packages/evals/scripts/110_grade_inference.py
python packages/evals/scripts/130_aggregate_results.py | tee results.txt
# Expected: Brick max-quality ≈ 76.98% accuracy, oracle bound ≈ 83.25%
Full pipeline (judges, baselines, cost/Pareto analysis): docs/quickstart/eval.md.
🤗 Datasets & models
| Artifact | HF Repo | Type | Notes |
|---|---|---|---|
| Dataset A (eval) | regolo/brick-dataset-A-routing-eval |
dataset | 5,504 queries, 6 dims, per-model verdicts |
| Dataset B (training) | massaindustries/dataset-B-modernbert-train |
dataset | ~50k labeled, multi-label |
| Capability classifier | regolo/brick-modernbert-capability-classifier |
model | ModernBERT-base, 6-label sigmoid |
| Complexity classifier | regolo/brick-complexity-2-eco |
model | Qwen3.5-0.8B + LoRA, 3-class |
Download recipes: packages/datasets/.
📄 Paper
Brick and the Mixture-of-Models (MoM) Paradigm: Bridging Open- and Closed-Weight LLM Pools
Francesco Massa, Marco Cristofanilli (2026) · Built at Regolo.ai (Seeweb)
Pre-built PDF: docs/paper/paper.pdf · compile with cd docs/paper && latexmk -pdf paper.tex.
@misc{massa2026brick,
title = {Brick and the Mixture-of-Models ({MoM}) Paradigm:
Bridging Open- and Closed-Weight {LLM} Pools},
author = {Massa, Francesco and Cristofanilli, Marco},
year = {2026},
url = {https://github.com/regolo-ai/brick-SR1}
}
📈 Star history
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi