skillfoundry
Health Uyari
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 6 GitHub stars
Code Basarisiz
- rm -rf — Recursive force deletion command in .claude/hooks/validate-bash.sh
- rm -rf — Recursive force deletion command in .claude/settings.json
Permissions Gecti
- Permissions — No dangerous permissions requested
This tool is an AI engineering framework and centralized MCP server designed to turn requirements into production-ready code. It provides automated quality gates, persistent memory, and multi-platform support for IDEs like Cursor, Claude Code, and Copilot.
Security Assessment
The framework is designed to execute shell commands, run automated tests, and interact with AI providers, inherently requiring network requests to function. The automated audit found no hardcoded secrets or dangerously broad permissions. However, it failed security checks due to the presence of `rm -rf` (recursive force deletion) commands inside `.claude/hooks/validate-bash.sh` and `.claude/settings.json`. While potentially a standard cleanup mechanism, automated recursive deletions can be destructive if triggered improperly. Overall risk is rated as Medium.
Quality Assessment
The project is licensed under the permissive MIT license and was actively updated recently (last push was today). However, it currently has extremely low community visibility, with only 6 GitHub stars. Despite the highly professional README and impressive claimed feature set, the low community adoption means the code has not been widely vetted by external developers.
Verdict
Use with caution — the framework offers a sophisticated feature set, but the presence of recursive deletion commands and a lack of widespread community vetting mean you should review its bash scripts before integrating it into your workflow.
AI engineering framework with quality gates, persistent memory, and multi-platform support. Works inside Claude Code, Cursor, Copilot, Codex, and Gemini.
SkillFoundry
Turn requirements into tested, production-ready code — with quality gates your AI can't skip.
![]()

SkillFoundry is an AI engineering framework with a centralized MCP server, 22 real tool agents, and a skill factory. v5 adds learning-driven intelligence: secret guard, deviation enforcement (161 rules), import validation, correction feedback loops, and per-project health scores — all derived from analysis of 2,792 artifacts across 49 projects. One server serves 124+ skills to any IDE via MCP with Playwright, Semgrep, a knowledge base that learns from every failure, and an iznir-powered skill factory.
Why SkillFoundry?
- Works where you already code — Claude Code, Cursor, GitHub Copilot, OpenAI Codex, Google Gemini. No new IDE to learn.
- Quality gates your AI can't bypass — The Anvil runs 8 tiers of checks (correctness contracts, banned patterns, type checking, tests, security, build, scope, deploy pre-flight) between every agent handoff. Code that fails doesn't ship.
- Persistent memory across sessions — Decisions, errors, and patterns are stored in
memory_bank/and recalled automatically. Your AI doesn't repeat the same mistakes. - PRD-first, not vibe-coding — Every feature starts with a Product Requirements Document. The framework validates it before writing a single line of code.
- 6 AI providers, one workflow — Anthropic, OpenAI, xAI, Google, Ollama, LM Studio. Switch providers without changing how you work.
What's New in v5.1.0
Karpathy-Inspired Agent Intelligence — Goal Reframing, Assumption Surfacing, Traceability Gate
Inspired by andrej-karpathy-skills (16.2k stars). Three improvements that close gaps in LLM self-discipline.
- Pre-Execution Verification Protocol — Agents must reframe imperative requests into verifiable success criteria before implementation. Surfaces assumptions explicitly, presents multiple interpretations when ambiguous. Mandatory for moderate/complex tasks.
- Anvil T4b: Traceability Test — Line-level validation that every changed line traces to the user's request. Categorizes lines as Direct/Supporting/Orthogonal/Suspicious. Orthogonal changes in security files auto-block. Prevents drive-by refactoring.
- 3 New LLM Deviation Patterns — LLM-019 (silent assumption-making), LLM-020 (orthogonal changes), LLM-021 (not pushing back on complexity). Total deviation patterns: 164.
Major: Learning-Driven Intelligence — Secret Guard, Deviation Enforcer, Import Validator, Correction Feedback Loop, Health Scores
Built from analysis of 2,792 harvested artifacts, 115 AI session transcripts, and 267 extracted insights across 49 projects. Every feature addresses a real, recurring problem measured from production data.
- Secret Guard Agent (
sf_secret_guard) — Pre-commit secret detection: 11 rules for API keys, passwords, tokens, DB URLs, JWT secrets, AWS keys, Stripe keys. False-positive filtering (validation messages, localhost, test fixtures, comments). Cross-referencesprocess.env.*against.env.examplefor completeness. - Import Resolution Validator (
sf_import_validator) — Validates everyimport/requireresolves to an actual package or local file. Detects missing npm packages, broken local imports, native module dependencies (better-sqlite3, sharp, bcrypt). Supports JS/TS/Python. - Deviation Enforcement Engine (
sf_deviation_enforcer) — Programmatic enforcement of 164 known LLM failure patterns across 16 categories (Frontend, Backend, Database, TypeScript, Security, Auth, Error Handling, LLM-Specific). Regex-based detection stored in SQLite, queryable, extensible. - Enhanced Contract Resolution (
sf_contract_check) — NestJS@Controllerprefix +@Get/@Postroute resolution. FastAPIAPIRouter(prefix=...)support. Centralized API clientbaseURLtracing (axios.create({ baseURL })→ path joining). Match rate improved from 17.5% to 70.8%. - Correction Feedback Loop — Analyzes user corrections from AI sessions, groups by semantic similarity, auto-generates deviation rules when a pattern appears 3+ times across 2+ projects. Closes the loop between human feedback and agent behavior.
- Project Health Scores — Per-project A-F grades with 0-100 scoring based on security findings, contract mismatches, import errors, and secret detections. Fleet-wide health summary in nightly reports. Trend tracking via
project_health_scorestable. - Nightly Report Trends — Enhanced nightly harvest pipeline with all new agents integrated. Reports now include secret guard findings, import errors, deviation violations, correction patterns, and fleet health scores.
- Path Validation — All MCP tool endpoints validate
projectPathagainst an allowlist, resolve the path, and verify it's a real directory. Prevents path traversal attacks. - 22 Total Tool Agents — 12 Tier 1-3 (Build, Test, Deps, Port, Git, TypeCheck, Lint, Migration, Env, Lighthouse, Docker, Nginx) + 5 Tier 4 (Contract Check, Project Context, Security Scan Lite, Version Check, Session Recorder) + 5 new v5 agents (Secret Guard, Import Validator, Deviation Enforcer, Contract Check Enhanced, Query Corrections).
Connect from any IDE:
"mcpServers": { "skillfoundry": { "url": "http://localhost:9877/mcp/sse" } }
Quick Install
# npm (recommended)
npm install -g skillfoundry
# Homebrew (macOS)
brew install samibs/tap/skillfoundry
# One-liner (Linux/macOS)
curl -fsSL https://raw.githubusercontent.com/samibs/skillfoundry/main/scripts/install-global.sh | bash
# npx (no install needed)
npx skillfoundry init
Quick Start (5 Minutes)
Five ways to install — pick what fits your workflow:
# Option A: npx (quickest — no clone needed)
cd ~/my-project
npx skillfoundry init
# Option B: npm global install (persistent CLI)
npm install -g skillfoundry
cd ~/my-project && skillfoundry init
# Option C: Homebrew (macOS)
brew install samibs/tap/skillfoundry
cd ~/my-project && skillfoundry init
# Option D: curl one-liner (Linux/macOS — installs via npm)
curl -fsSL https://raw.githubusercontent.com/samibs/skillfoundry/main/scripts/install-global.sh | bash
cd ~/my-project && skillfoundry init
# Option E: git clone (full source — for contributors and power users)
git clone https://github.com/samibs/skillfoundry.git ~/dev-tools/skillfoundry
cd ~/my-project && ~/dev-tools/skillfoundry/install.sh
Then use it in your AI IDE:
/prd "add user authentication" # write requirements
/forge # build everything with quality gates
That's it. The installer copies agents and skills into your project, builds the CLI, and adds sf to your PATH.
# Option A: npx
cd C:\MyProject
npx skillfoundry init
# Option B: npm global
npm install -g skillfoundry
cd C:\MyProject; skillfoundry init
# Option C: git clone
git clone https://github.com/samibs/skillfoundry.git C:\DevTools\skillfoundry
cd C:\MyProject
C:\DevTools\skillfoundry\install.ps1
Requires Node.js v20+ for the standalone CLI. IDE skills work without Node.js.
Cross-platform: Works on Linux, macOS, Windows (native, Git Bash, and WSL). Quality gates and anvil scripts auto-detect the environment.New to SkillFoundry? See the Todo API example — a complete project built from a single PRD in two commands. For model recommendations, see Model Compatibility.
How It Works
/prd "feature" Write requirements (saved to genesis/)
│
/forge The full pipeline:
│
├── Validate PRD Are requirements complete?
├── Generate stories Break into implementable units
├── Implement Architect → Coder → Tester pipeline
├── Quality gates The Anvil (T0-T7) + Micro-Gates (MG0-MG3)
├── Circuit breaker Halt on repeated systemic errors
├── Security audit OWASP scan + dependency CVEs + credential check
├── Harvest knowledge Save lessons to memory_bank/
└── Quality metrics Track gate pass rates, trends, and industry baselines
Or use autonomous mode — just type what you want in plain English:
/autonomous on
> "add dark mode to the dashboard" → auto-classified as FEATURE → full pipeline runs
> "the login is broken" → auto-classified as BUG → debugger + fixer dispatched
Two Ways to Use SkillFoundry
SkillFoundry has two independent systems. They share the same agents and philosophy, but work differently:
| IDE Skills (64 skills) | Standalone CLI (sf) |
|
|---|---|---|
| What it is | Markdown instruction files your AI reads | Terminal app with its own AI connection |
| Runs inside | Claude Code, Copilot, Cursor, Codex, Gemini | Your terminal (any OS) |
| Full pipeline | /forge, /go, /goma (all 64 skills) |
/forge, /plan, /gates (23 commands) |
| Autonomous mode | /goma — full autonomous with safety gates |
Not available |
| Provider switching | Uses your IDE's provider | Built-in: 6 providers, switch at runtime |
| Budget controls | Not available | Per-run and monthly cost caps |
| Persistent memory | /memory, /gohm |
/memory, /lessons |
| Requires | An AI coding tool | Node.js v20+ |
Most users should start with IDE skills. The CLI is for standalone use or when you want provider switching and budget controls.
1. Inside Your IDE (Recommended)
64 skills install directly into your AI coding tool. This is the full SkillFoundry experience — all agents, all orchestration, autonomous mode, everything.
| Platform | Invocation | Example |
|---|---|---|
| Claude Code | /command |
/forge, /go, /goma, /review |
| GitHub Copilot | @agent in chat |
@forge, @coder, @tester |
| Cursor | Auto-loaded rules | Rules activate on context |
| OpenAI Codex | $command |
$forge, $go, $review |
| Google Gemini | Skill invocation | forge, go, review |
# Full pipeline — works in Claude Code, Copilot, Cursor, Codex, Gemini
/prd "add user authentication" # create requirements
/forge # validate → implement → gate → audit → harvest
/goma # autonomous mode: just describe what you want
# Individual agents
/coder # code implementation
/review # code review
/security audit # security scan
/memory recall "auth" # recall lessons from previous sessions
2. The Standalone CLI (sf)
A separate terminal app with its own AI connection. Useful for provider switching, budget controls, and working outside an IDE. Has 23 native commands (not all 64 skills).
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
│ ◆ SkillFoundry CLI anthropic:claude-sonnet ● team:dev ● $0.00 ● 14.2k tok │
└──────────────────────────────────────────────────────────────────────────────────┘
│ ▸ sf:coder> I'll help you add dark mode. Let me look at the existing
│ dashboard code...
│
│ ▸ bash npm test ✓ 0.8s
│ ◉ read src/styles/theme.ts ✓ 0.1s
│ ◈ write src/styles/dark.ts ✓ 0.1s
│
│ ● routed:high ● 142 in / 387 out ● $0.0045
╭──────────────────────────────────────────────────────────────────────────────────╮
│ ⟫ looks good, now review for accessibility issues │
╰──────────────────────────────────────────────────────────────────────────────────╯
│ ▸ sf:review> I'll review the dark mode implementation for accessibility...
Features
Multi-Agent Teams
Summon a team once, and messages auto-route to the best agent for the job. No manual switching.
/team dev → coder, tester, fixer, review, debugger
/team security → security, review, tester
/team fullstack → architect, coder, tester, review, debugger, docs
/team ops → devops, sre, performance, security
/team ship → coder, tester, review, release, docs
/team custom coder review tester → build your own roster
Routing is keyword-based with weighted patterns — no extra LLM calls, deterministic and fast.
Quality Gates (The Anvil + Micro-Gates)
Every handoff passes through a 7-tier quality pipeline plus AI-powered micro-gates:
◆ The Anvil
┣━ T0 ◉ Correctness Contract 0.1s
┣━ T1 ◉ Banned Patterns & Syntax 0.2s
┣━ T2 ◉ Type Check 1.1s
┣━ T3 ◉ Tests 3.4s
┣━ T4 ◉ Security Scan 0.8s
┣━ T5 ◉ Build 2.1s
┗━ T6 ◉ Scope Validation 0.3s
┌──────────────────────────────────────────┐
│ ✓ VERDICT: PASS 6P 0F 0W 1S (8.0s) │
└──────────────────────────────────────────┘
◆ Micro-Gates (per story)
┣━ MG0 ◉ AC Validation (static) PASS
┣━ MG1 ◉ Security Review (AI) PASS
┣━ MG1.5 ◉ Test Documentation (AI) PASS
┣━ MG2 ◉ Standards Review (AI) PASS
┗━ MG3 ◉ Cross-Story Review (AI) PASS (advisory)
Micro-gates are lightweight reviews at pipeline handoff points. MG0 validates acceptance criteria are objectively testable (static, no AI). MG1 (security) and MG2 (standards) run after each story — if they fail, the fixer is triggered automatically. MG1.5 checks test documentation quality (re-triggers tester on failure). MG3 reviews cross-story consistency before the TEMPER phase (advisory only).
PRD-First Development
Every non-trivial feature starts with a Product Requirements Document. No PRD = no implementation.
/prd "user authentication with OAuth2" → Creates genesis/2026-02-23-auth.md
/go → Validates PRDs → generates stories → implements
/forge → Real AI pipeline: PRDs → stories → implement → gates → report
/forge --dry-run → Read-only scan (no AI execution)
Multi-Provider Support
Switch between 6 AI providers without changing your workflow:
| Provider | Env Variable | Default Model |
|---|---|---|
| Anthropic Claude | ANTHROPIC_API_KEY |
claude-sonnet-4 |
| OpenAI | OPENAI_API_KEY |
gpt-4o |
| xAI Grok | XAI_API_KEY |
grok-3 |
| Google Gemini | GOOGLE_API_KEY |
gemini-2.5-flash |
| Ollama (local) | OLLAMA_BASE_URL |
llama3.1 |
| LM Studio (local) | LMSTUDIO_BASE_URL |
qwen2.5-coder-7b |
sf setup --provider anthropic --key sk-ant-... # persistent storage
/provider set openai # switch at runtime
/provider set lmstudio # use LM Studio locally
Budget Controls
Per-run and monthly cost caps with real-time tracking:
# .skillfoundry/config.toml
[budget]
monthly_limit_usd = 50.00
per_run_limit_usd = 2.00
Token usage and cost are shown live in the header during streaming.
Structured Logging
Every pipeline run and interactive session produces structured JSONL logs for troubleshooting. One JSON object per line — parseable, grep-friendly, and timestamped.
.skillfoundry/logs/
├── session.log # Rolling log for interactive mode (last 1000 lines)
├── forge-20260305-abc123.log # Per-pipeline-run log
└── ... # Auto-cleanup keeps last 20
{"ts":"2026-03-05T12:07:14.123Z","level":"INFO","category":"pipeline","event":"phase_start","data":{"phase":"FORGE"}}
{"ts":"2026-03-05T12:07:15.456Z","level":"ERROR","category":"provider","event":"connection_error","data":{"provider":"openai","error":"ECONNREFUSED"}}
{"ts":"2026-03-05T12:07:16.789Z","level":"WARN","category":"provider","event":"retry_attempt","data":{"attempt":2,"delayMs":1000}}
Configure the log level in .skillfoundry/config.toml:
log_level = "info" # debug | info | warn | error
Set to debug for per-turn token counts and tool call tracing. Default info captures phase transitions, gate results, and errors.
Pipeline Resume
/forge tracks story completion and resumes where it left off. If a run is interrupted or partially fails, re-running /forge skips already-completed stories and implements only the remaining ones.
Implementing 2 stories (3 already done, skipped)
Stories are marked status: DONE in their .md files after successful completion, including passing micro-gates and fixer loops.
Local-First Development
Use local models (Ollama, LM Studio) for free, offline AI — with automatic fallback to cloud when needed.
# .skillfoundry/config.toml
[routing]
route_local_first = true # Enable local-first routing
local_provider = "ollama" # or "lmstudio"
local_model = "llama3.1" # your preferred local model
context_window = 0 # 0 = auto-detect from model
What happens when enabled:
- Simple tasks (docs, formatting, boilerplate) route to your local model (free)
- Complex tasks (architecture, security, refactoring) route to cloud (paid)
- Context compaction automatically fits prompts within local model limits (4K-32K)
- If the local model is offline, cloud fallback activates with a warning
/cost → Shows local vs cloud token breakdown + estimated savings
/config route_local_first true → Enable routing
/provider set lmstudio → Switch to LM Studio
Smart Output Compression
Tool outputs are automatically compressed before reaching the AI context — saving 60-90% of tokens on common operations. No configuration needed.
| Command | Before | After | Savings |
|---|---|---|---|
git status |
~2,000 tokens | ~400 tokens | -80% |
git push/commit |
~1,600 tokens | ~120 tokens | -92% |
npm test (all pass) |
~25,000 tokens | ~2,500 tokens | -90% |
tsc --noEmit |
~8,000 tokens | ~1,600 tokens | -80% |
npm install |
~3,000 tokens | ~450 tokens | -85% |
The compressor detects command type via regex (<1ms), applies type-specific filtering (strip noise, group errors, deduplicate, show failures only), and falls back to standard truncation for unrecognized commands. Full output is preserved on errors for debugging context.
Tool System
The AI executes tools with permission controls and dangerous command blocking:
| Tool | Icon | Purpose |
|---|---|---|
bash |
▸ |
Run shell commands |
read |
◉ |
Read files with line numbers |
write |
◈ |
Create or overwrite files |
glob |
✶ |
Find files by pattern |
grep |
≣ |
Search file contents |
debug_start |
Start a debug session (Node.js) | |
debug_breakpoint |
Set/remove/list breakpoints | |
debug_inspect |
Inspect scope, callstack, variables | |
debug_evaluate |
Evaluate expressions in paused frame | |
debug_step |
Step over/into/out/continue/pause | |
debug_stop |
Terminate debug session |
Permission modes: auto (read auto-approved, write asks), ask (prompt every time), trusted (allow all), deny (block all).
Interactive Debugger
AI agents can debug your code with real breakpoints, variable inspection, and expression evaluation — using the Chrome DevTools Protocol (CDP) over WebSocket.
/debug src/server.ts # Start a debug session, paused at entry
/debug src/server.ts:42 # Start and set breakpoint at line 42
/debug test src/auth.test.ts # Debug a test file via test runner
The debugger:
- Spawns
node --inspect-brk=0with source map support - Connects via a custom MinimalWebSocket (Node 20 compatible, no polyfills)
- Enforces singleton sessions (one at a time) with configurable timeout (default 60s, max 5min)
- Localhost-only WebSocket connections (security hardened)
- SIGTERM → SIGKILL escalation for process cleanup
Persistent Memory (Lessons Learned)
SkillFoundry remembers across sessions. Every decision, error, and pattern is stored in memory_bank/ using append-only JSONL with weighted relevance ranking. Agents query this memory automatically — so they don't repeat mistakes or forget conventions.
memory_bank/
├── knowledge/
│ ├── bootstrap.jsonl Pre-seeded framework knowledge
│ ├── facts.jsonl Verified technical facts
│ ├── decisions.jsonl Design decisions with rationale
│ ├── errors.jsonl Error patterns and their solutions
│ └── preferences.jsonl User preferences and conventions
├── relationships/
│ ├── knowledge-graph.json Node/edge relationship graph
│ └── lineage.json Correction chains and lineage
└── retrieval/
├── query-cache.json Recent query cache
└── weights.json Weight adjustment history
Automatic pipeline harvesting: Every /forge run automatically writes knowledge entries to memory_bank/knowledge/*.jsonl — run summaries, failed story errors, micro-gate findings, and gate verdicts. No manual invocation needed.
In the CLI:
/memory stats Show memory bank statistics
/memory recall "authentication" Find relevant lessons
In any platform (Claude Code, Cursor, etc.):
/gohm Harvest lessons from current session
/memory recall "JWT" Recall what you learned about JWT
Via shell scripts:
scripts/memory.sh remember "Use RS256 for JWT, never HS256" decision
scripts/memory.sh recall "database migration"
scripts/memory.sh status
Weight system: Entries start at 0.5 weight. Validated-by-test entries gain +0.2. Retrieved-and-used entries gain +0.1. Corrected entries drop to 0.3 while the correction starts at 0.7. Higher weight = higher retrieval priority.
Knowledge Sync (Cross-Project Learning)
Knowledge doesn't stay locked in one project. The sync daemon pushes lessons to a central GitHub repository and pulls global lessons back — so patterns learned in project A are available in project B.
# One-time setup: connect a global knowledge repo
scripts/knowledge-sync.sh init https://github.com/you/dev-memory.git
# Start the background sync daemon (syncs every 5 minutes)
scripts/knowledge-sync.sh start
# Manual sync
scripts/knowledge-sync.sh sync
# Promote recurring error patterns to global lessons
scripts/knowledge-sync.sh promote
# Register a new project for cross-project sync
scripts/knowledge-sync.sh register /path/to/project
Harvest engine: After a session, scripts/harvest.sh extracts decisions, errors, and patterns from one or all registered projects into the central memory_bank/knowledge/ universal files. Entries that repeat 3+ times across projects get auto-promoted to global lessons.
Autonomous Mode
Toggle autonomous mode and stop typing commands — just describe what you want in plain English. SkillFoundry classifies your intent and routes to the correct pipeline automatically.
/autonomous on Enable autonomous mode
Once active, every message is classified and routed:
| You Type | Classified As | Pipeline |
|---|---|---|
| "add dark mode to the dashboard" | FEATURE | Architect → Coder → Tester → Gate-Keeper |
| "the login is broken" | BUG | Debugger → Fixer → Tester |
| "clean up the auth module" | REFACTOR | Architect → Coder → Tester |
| "how does the payment flow work?" | QUESTION | Explain (read-only, no file changes) |
| "deploy to staging" | OPS | Ship / DevOps pipeline |
| "remember: we use RS256 for JWT" | MEMORY | Write to memory_bank/ |
Complex features automatically get a PRD generated in genesis/, stories broken out, and the full agent pipeline executed — with quality gates between every handoff.
/autonomous off Back to manual command mode
/autonomous status Check if autonomous mode is active
VS Code Extension
SkillFoundry ships a native VS Code extension that brings quality gates, telemetry, and forge runs directly into your editor — no terminal switching required.
┌──────────┬──────────────────────────────┬───────────────┐
│ Explorer │ Editor │ SF Sidebar │
│ │ │ │
│ │ src/auth.ts │ ◆ Dashboard │
│ │ ───────────────── │ Pass Rate 94%│
│ │ 1 │ import { hash } │ Last Forge ✓ │
│ │ 2 │ // TODO: add rate ⚠ │ CVEs: 2 high │
│ │ │ ▸ Run T1 (Patterns) │ │
│ │ │ ▸ Run T4 (Security) │ ◆ Gate Status │
│ │ │ T0-T7 results│
│ │ │ │
│ │ │ ◆ Forge │
│ │ │ Phase: TEMPER│
│ │ │ Story: 5/8 │
├──────────┴──────────────────────────────┴───────────────┤
│ SF: 94% gates │ sf:coder │ $0.12 Output │
└─────────────────────────────────────────────────────────┘
Features:
- Sidebar dashboard — gate pass rate, security findings, telemetry trends, dependency CVEs
- Inline diagnostics — gate findings appear as squiggly underlines (like ESLint)
- CodeLens — "Run T3 (Tests)" above test files, "Run T1/T4" above source files
- Command palette — 12 commands: gate, forge, metrics, report, memory recall, PRD, hooks, benchmark
- Forge monitor — real-time phase progress in sidebar, runs in integrated terminal
- Status bar — gate pass rate with color coding, click to open metrics
- File watcher — auto-refreshes dashboard when telemetry updates
# From VS Code Marketplace (recommended)
# Search "SkillFoundry" in the Extensions panel, or:
code --install-extension skillfoundry.skillfoundry
# Or build from source
cd skillfoundry-vscode && npm install && npm run build
code --install-extension skillfoundry-0.1.0.vsix
Agent Evolution
Agents improve over time through a debate-implement-iterate loop:
scripts/evolve.sh debate Agents debate improvements
scripts/evolve.sh implement --auto-fix Apply winning proposals
scripts/evolve.sh iterate Refine through multiple rounds
scripts/evolve.sh run Full evolution cycle
Command Reference
sf CLI Commands (23 native)
These work inside the sf terminal app:
| Command | Purpose |
|---|---|
/help |
List available commands |
/setup |
Configure API keys |
/status |
Session info, provider, budget |
/team <name> |
Summon a team (dev, security, ops, fullstack, ship) |
/agent <name> |
Activate a single agent (coder, review, tester, etc.) |
/plan <task> |
Generate an implementation plan |
/apply [plan-id] |
Execute a plan with quality gates |
/gates [target] |
Run The Anvil quality gates (T1-T7) |
/gate <t0-t7|all> |
Run a single quality gate or all gates |
/forge |
Pipeline: validate PRDs → implement → gate → report |
/forge --dry-run |
Read-only scan without execution |
/provider [set <name>] |
Switch AI provider |
/model [model-name] |
List or switch the AI model |
/cost |
Token usage and cost report |
/memory [stats|recall] |
Query or record knowledge |
/config [key] [value] |
View or edit configuration |
/metrics [--window N] |
Quality metrics dashboard with trends |
/report [--format md|json] |
Generate exportable quality report |
/benchmark |
Compare quality against industry baselines |
/hook install|uninstall|status |
Manage git hook integration for quality gates |
/runtime |
Runtime intelligence status (message bus, agent pool, vector store) |
/prd review <path> |
Score a PRD on 4 dimensions with actionable feedback |
/lessons |
Query and manage knowledge bank entries |
IDE Skills (63 — Claude Code, Copilot, Cursor, Codex, Gemini)
These work inside your AI coding tool, not in the sf CLI:
| Skill | Purpose |
|---|---|
/forge |
Full 6-phase pipeline (Ignite → Forge → Temper → Inspect → Remember → Debrief) |
/go |
PRD-first orchestrator: validate → stories → implement |
/goma |
Autonomous mode: classify intent, route to pipeline, execute |
/prd "idea" |
Create a Product Requirements Document |
/coder |
Code implementation agent |
/tester |
Test generation and validation |
/review |
Code review |
/security |
Security audit (OWASP, credentials, banned patterns) |
/architect |
System design and architecture |
/debug |
Interactive debugger (breakpoints, scope, evaluate) |
/layer-check |
Three-layer validation (DB → Backend → Frontend) |
/memory |
Knowledge management |
/gohm |
Harvest lessons from current session |
/autonomous |
Toggle autonomous developer loop |
| ...and 50 more | See /help in your IDE for the full list |
Note:
/forgeexists in both systems but they are different implementations. The IDE skill orchestrates sub-agents; the CLI command runs a self-contained pipeline.
Supported Platforms
The framework generates platform-specific configurations during install. Each platform gets the same 64 skills adapted to its native format:
| Platform | What Gets Installed | How to Invoke | Notes |
|---|---|---|---|
| Claude Code | .claude/commands/ (64 skills) |
/command |
Slash commands in Claude Code CLI |
| GitHub Copilot | .copilot/custom-agents/ (60 agents) |
@agent in chat |
Custom agents in Copilot Chat |
| Cursor | .cursor/rules/ (60 rules) |
Auto-loaded | Rules activate based on context |
| OpenAI Codex | .agents/skills/ (64 skills) |
$command |
Dollar-prefix commands in Codex CLI |
| Google Gemini | .gemini/skills/ (64 skills) |
Skill invocation | Available in Gemini sessions |
Install multiple platforms at once:
./install.sh --platform="claude,cursor,copilot" # Linux/macOS
./install.ps1 -Platform "claude,cursor,copilot" # Windows
All 64 skills work identically across platforms. The installer translates agent contracts from agents/ into each platform's native format. When you update the framework, update.sh / update.ps1 regenerates all platform files.
Architecture
skillfoundry/
├── sf_cli/ Interactive CLI (Node.js + React/Ink)
│ ├── src/core/ Provider adapters, tools, permissions, gates, micro-gates, budget, compaction, output compression, debugger (CDP), message bus, agent pool, embedding service, vector store, weight learner, dependency scanner, report generator, gitleaks scanner, checkov scanner, semantic search, PRD scorer
│ ├── src/components/ Terminal UI: Header, Input, Message, GateTimeline, ...
│ ├── src/commands/ Slash command handlers (/team, /agent, /plan, ...)
│ └── src/hooks/ Session state and streaming hooks
├── skillfoundry-vscode/ VS Code Extension (bridge to sf_cli)
│ ├── src/extension.ts Activation, lifecycle, file watcher
│ ├── src/bridge.ts Thin adapter calling sf_cli core modules
│ ├── src/providers/ Dashboard, gate timeline, dependency CVE tree, forge monitor, diagnostics, CodeLens, status bar
│ └── src/commands/ Gate, forge, memory, PRD, metrics, report commands
├── agents/ 56 agent contracts and orchestration protocols
├── genesis/ PRD templates and your feature documents
├── memory_bank/ Persistent knowledge across sessions
│ ├── knowledge/ facts, decisions, errors, preferences (JSONL)
│ └── relationships/ Knowledge graph and lineage tracking
├── scripts/ Shell tooling (works without the CLI)
│ ├── env-preflight.sh Environment audit → JSON (interpreters, deps, .env safety)
│ ├── auto-harvest-cron.sh Cron sweep: harvest all registered projects on schedule
│ ├── setup-auto-harvest.sh One-command installer for cron + Claude Code hooks
│ ├── session-monitor.sh Real-time agent behavior monitor (PostToolUse hook)
│ ├── memory.sh Remember, recall, correct knowledge
│ ├── harvest.sh Extract lessons from projects
│ ├── knowledge-sync.sh Sync daemon for cross-project learning
│ ├── anvil.sh Quality gate runner
│ ├── evolve.sh Agent evolution (debate → implement → iterate)
│ ├── session-init.sh Session startup (pull knowledge, start daemon)
│ └── session-close.sh Session teardown (harvest, sync, stop daemon)
├── compliance/ GDPR, HIPAA, SOC2 profiles and automated checks
├── observability/ Audit logging, metrics collection, trace viewer
│
│ Platform skill files (generated by installer):
├── .claude/commands/ Claude Code (64 skills)
├── .copilot/custom-agents/ GitHub Copilot (60 agents)
├── .cursor/rules/ Cursor (60 rules)
├── .agents/skills/ OpenAI Codex (64 skills)
└── .gemini/skills/ Google Gemini (64 skills)
Pipeline Details
┌─────────────┐
│ /prd │ Write requirements
└──────┬──────┘
│
┌──────▼──────┐
│ /go │ Validate → generate stories → implement
└──────┬──────┘
│
┌────────────┼────────────┐
│ │ │
┌─────▼─────┐ ┌───▼───┐ ┌─────▼─────┐
│ Architect │ │ Coder │ │ Tester │ Agent pipeline
└─────┬─────┘ └───┬───┘ └─────┬─────┘
│ │ │
└────────────┼────────────┘
│
┌──────▼──────┐
│ Micro-Gates │ MG1 security + MG2 standards
└──────┬──────┘
│
┌──────▼──────┐
│ The Anvil │ T1-T6 quality gates
└──────┬──────┘
│
┌──────▼──────┐
│ /security │ OWASP scan + credential check
└──────┬──────┘
│
┌──────▼──────┐
│ /gohm │ Harvest lessons → memory_bank/
└──────┬──────┘
│
┌──────▼──────┐
│ knowledge │ Sync to global repo (optional)
│ sync │ Lessons available in all projects
└─────────────┘
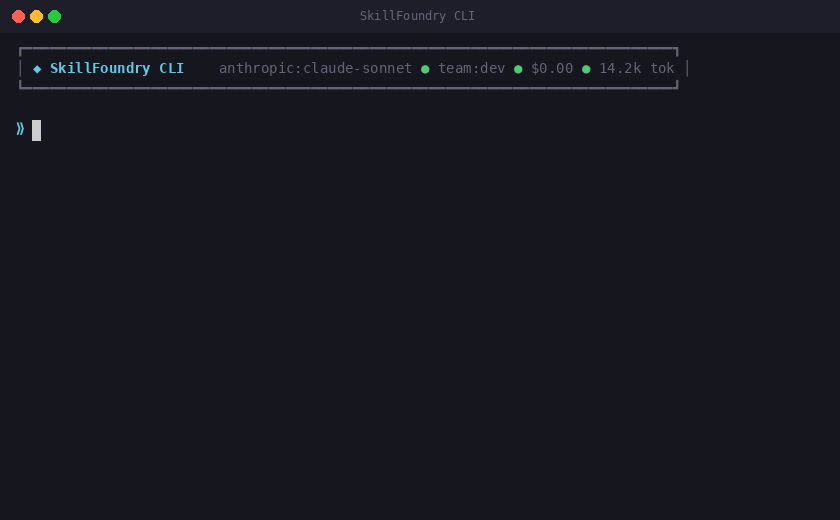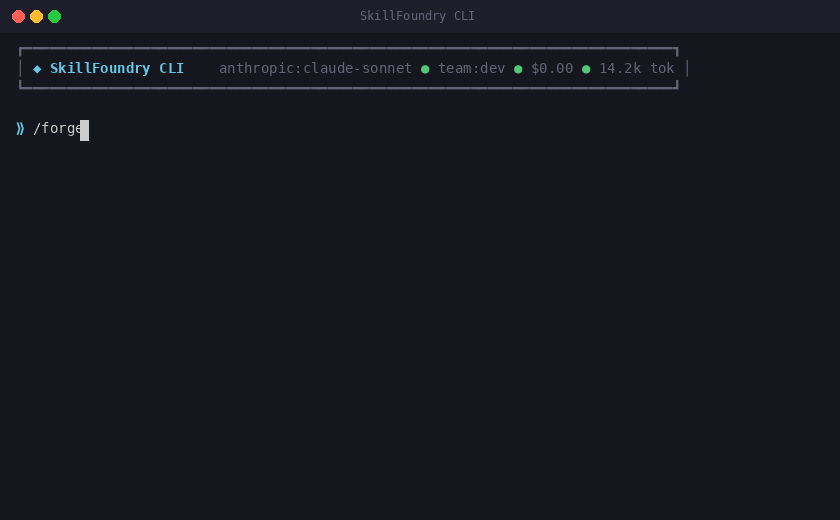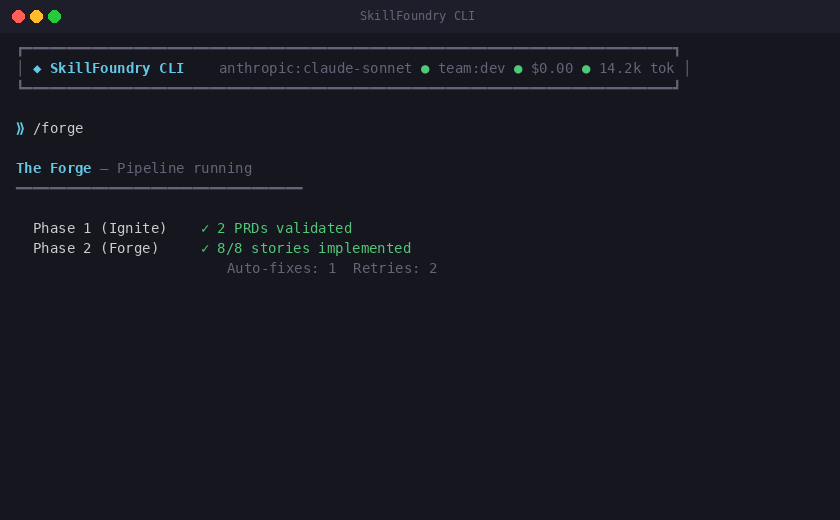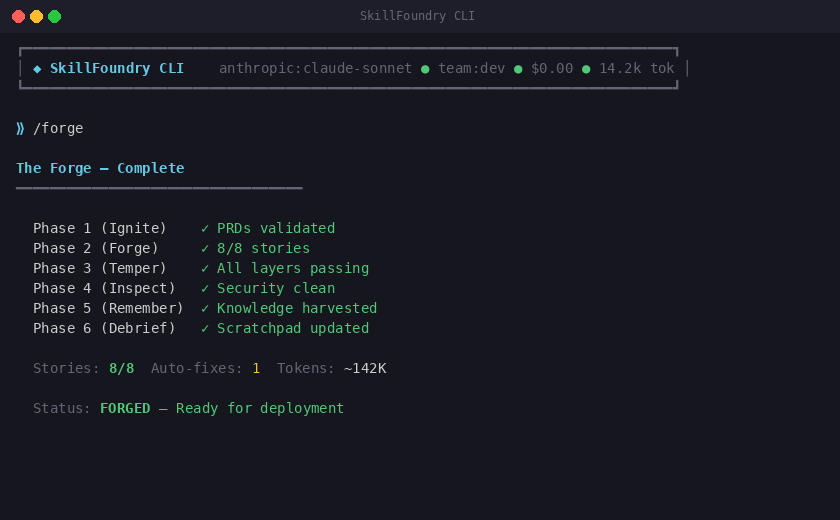
/forge runs this entire pipeline in one command. It discovers PRDs, generates stories, implements each story with the agentic tool-use loop, runs micro-gates (MG1 security + MG2 standards per story, MG3 cross-story review), runs T1-T6 quality gates (with auto-fixer retries), persists run metadata, and automatically harvests knowledge entries (run summaries, errors, gate verdicts) to memory_bank/knowledge/*.jsonl. Use /forge --dry-run for a read-only scan.
Updating
After pulling the latest framework:
# Linux/macOS
cd ~/dev-tools/skillfoundry && git pull
./update.sh ~/my-project # Updates skills + rebuilds CLI
# Windows
cd C:\DevTools\skillfoundry; git pull
.\update.ps1 -Project C:\MyProject # Updates skills + rebuilds CLI
Update all registered projects at once:
./update.sh --all # Linux/macOS
.\update.ps1 -All # Windows
Documentation
| Document | Description |
|---|---|
| User Guide | Full CLI usage guide |
| Quick Reference | Command cheat sheet |
| Agent Evolution | How agents evolve and improve |
| API Reference | CLI internals and extension points |
| Persistent Memory | Memory bank schema and usage |
| Autonomous Mode | Autonomous developer loop details |
| Knowledge Sync | Cross-project knowledge sync |
| Anti-Patterns | Security anti-patterns to avoid |
| Model Compatibility | Which AI models work, tier recommendations |
| Troubleshooting | Common issues and fixes |
| Changelog | Version history |
| Todo API Example | Complete example project built from a single PRD |
Contributing
Contributions welcome. See CONTRIBUTING.md for setup, workflow, and code standards.
Short version: fork, branch, write tests, open a PR against main.
License
MIT License. See LICENSE.
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi