scholar-megasearch
Health Uyari
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 5 GitHub stars
Code Basarisiz
- rm -rf — Recursive force deletion command in setup/install.sh
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
Massive multi-source academic literature search for Claude Code — one skill fans out subagents across 20+ scholarly databases (arXiv, Semantic Scholar, Crossref, OpenAlex, PubMed, …), merges into a deduplicated ranked corpus, and acquires the original PDFs.
scholar-megasearch
Massive multi-source academic literature search for Claude Code.
One skill that fans out subagents across 20+ scholarly databases, merges everything into a single deduplicated corpus, and acquires the original PDFs.
한국어 README · SKILL.md · Source catalog · Orchestration




One sentence: ask Claude Code for a topic, and get back a single ranked,
deduplicated, provenance-tracked corpus of papers — with the PDFs already on disk.
- 🔭 20+ databases in one pass — arXiv, Semantic Scholar, Crossref, OpenAlex, PubMed/PMC, bioRxiv/medRxiv, DOAJ, CORE, BASE, OpenAIRE, Zenodo, Unpaywall, HAL, DBLP, IACR, SSRN, CiteSeerX, Europe PMC, plus web/GitHub.
- 🧵 Subagent fan-out — one searcher per source bucket, running in parallel, so breadth doesn't cost you serial wall-clock.
- 🧹 Dedup with provenance — merged by DOI → arXiv-id → normalized title; every paper records which databases surfaced it.
- 📊 Corroboration ranking — papers found by more independent databases rank higher, not just the ones with good SEO.
- 📄 Original PDFs — top-K acquired automatically via open-access routes, with a manifest of what landed and what needs a paywall fallback.
- 🧭 Domain-aware routing — physics, life sciences, CS, crypto, economics, or math each pull the right subset of databases.
Why It Exists
Searching one database at a time is how good papers get missed. arXiv won't show
you the published version's citation count; Semantic Scholar won't surface the
bioRxiv preprint; Google Scholar won't tell you which of its hits also appear in
three other indexes. So you end up running the same query in five tabs, copy-pasting
into a doc, hand-deduplicating, and then hunting each PDF down separately.
scholar-megasearch collapses that into one request. It treats "search the
literature" as a fan-out problem: decompose the topic, send each source bucket to
its own subagent, and reconcile everything afterward. The output isn't a chat reply —
it's a corpus on disk where every entry is deduplicated, ranked by how many
independent databases corroborate it, and backed by a downloaded PDF wherever a free
route exists.
How It Works
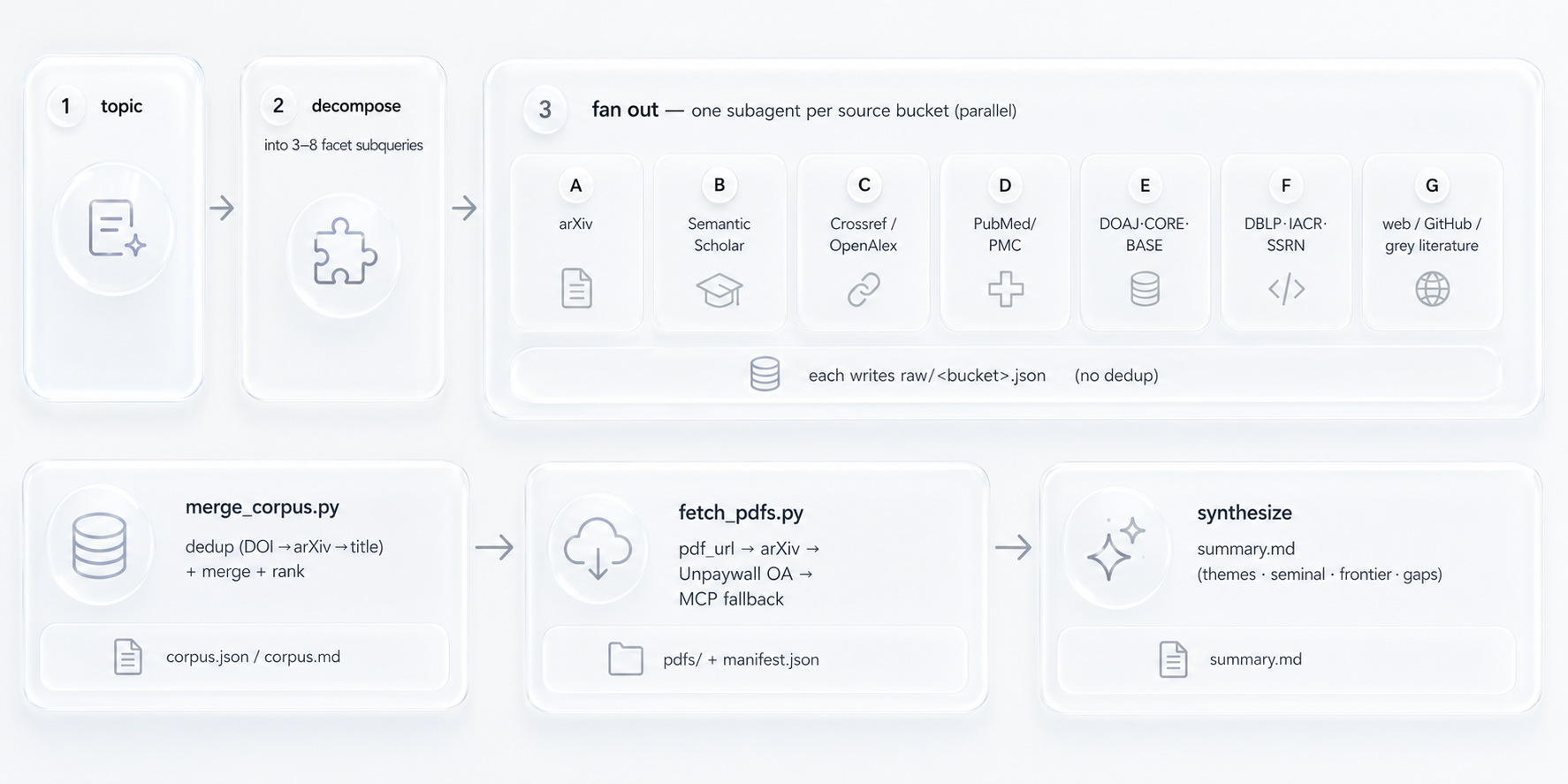
Orchestration runs as a deterministic Workflow when available, and falls back to
direct Agent fan-out otherwise. A domain → bucket routing table picks the right
4–7 buckets per topic.
Dedup & ranking
Records from different databases are merged when they share any of: a normalized
DOI, an arXiv id (version-stripped), or a normalized title. The merged record keeps
the richest value per field — the longest abstract, the most complete author list,
the maximum citation count — and accumulates the set of sources that found it.
Ranking is then (number of sources, citation count, year), descending. Pass--min-sources 2 to keep only papers corroborated by two or more databases — a
high-precision shortlist that filters out single-index noise.
A typical run
A mid-depth sweep (≈ L3 Deep) on a focused topic looks roughly like this (illustrative):
topic: "spin–orbit torque switching in ferrimagnets"
facets: 6 subqueries buckets: A B C E G (5 searchers)
raw hits: ~310 across buckets
unique: ~150 after dedup (≈60 corroborated by ≥2 databases)
PDFs: 22 / 25 acquired (3 flagged needs_mcp — paywalled)
output: ./literature_search/spin-orbit-torque-ferri_2026-05-29/
Install
git clone https://github.com/TaewoooPark/scholar-megasearch.git
cd scholar-megasearch
bash setup/install.sh [email protected] # email used for Unpaywall OA + arXiv politeness
The script installs the skills into ~/.claude/skills/, builds~/.claude/skill_venv and ~/.claude/paper_search_mcp_venv, installs the local MCP
servers (paper-search-mcp from git main — the PyPI build lacks Crossref/OpenAlex;arxiv-mcp-server via uvx), and writes setup/mcp.servers.resolved.json. Semantic
Scholar (Bucket B) is the remote Ai2 Asta MCP —
nothing to install, and it works without a key (rate-limited). For higher rate
limits, request a free key and add a header to the asta entry:"headers": { "x-api-key": "YOUR_ASTA_KEY" } — paste the literal key (a ${ENV}
placeholder is sent verbatim and rejected with HTTP 403). Asta use is subject to Ai2's
terms (see Attribution). Merge that file's mcpServers entries into~/.claude.json and restart Claude Code.
Requirements
| Python | 3.11+ |
uv |
for uvx arxiv-mcp-server |
git |
pip install of paper-search-mcp (git main) at install time |
| Claude Code | the skill is triggered from within a session |
Usage
Inside Claude Code, trigger the skill in natural language:
search every database for spin–orbit torque switching and grab the PDFs
MoE 관련 최근 1년 논문 방대하게 검색해줘, PDF까지
Or invoke it as a slash command, optionally pinning the depth level (see
Depth levels) — prepend depth=N, LN, or a bare 1–5, or use a
phrase like quick / 전수조사. Everything after the command is the topic:
/scholar-megasearch depth=4 spin–orbit torque switching in ferrimagnets
/scholar-megasearch L5 altermagnetism candidate materials # L5 = grab every source's PDFs
/scholar-megasearch quick first look at skyrmion racetrack memory
/scholar-megasearch 전수조사 위상 절연체 표면 상태 측정 # 전수조사 → L5
/scholar-megasearch MoE routing papers from the last year # no level → defaults to L2
Or run the scripts directly:
# merge per-source result files into one ranked corpus
python3 ~/.claude/skills/scholar-megasearch/scripts/merge_corpus.py \
./literature_search/<topic>_<date>/raw \
-o corpus.json --md corpus.md --min-sources 2
# acquire original PDFs for the top 25 ranked papers
python3 ~/.claude/skills/scholar-megasearch/scripts/fetch_pdfs.py \
corpus.json -o ./pdfs --email [email protected] --top 25
Depth levels
One knob scales breadth (facets × buckets × hits per query) and recursion
(extra waves) together. Pick a level per run — an explicit depth=N / LN / bare1–5 wins; otherwise it's inferred from phrasing (quick/빠르게 → L1 …every source/전수조사 → L5); otherwise it defaults to L2.
| Level | Facets | Buckets | Hits/query | Waves | PDFs | Output |
|---|---|---|---|---|---|---|
| L1 · Quick | 3 | 4 | 15 | wave 1 only | top 10 | corpus |
| L2 · Standard (default) | 5 | 5 | 25 | wave 1 only | top 30 | corpus |
| L3 · Deep | 6 | 6 | 30 | + citation snowball | top 50 | corpus |
| L4 · Exhaustive | 8 | 7 (all) | 40 | + snowball + completeness-critic pass | top 100 | corpus + ≥2 shortlist |
| L5 · Total (전수조사) | 8 | 7 (all) | 40 | + snowball + critic loop-until-dry | all sources | corpus + ≥2 shortlist |
Each wave is a fan-out followed by a merge into the same corpus: the citation
snowball (L3+) seeds the top DOIs/arXiv ids back through citation graphs; the
completeness-critic (L4+) names missing subtopics/authors that become the next
wave's facets, looped until dry at L5. L4/L5 also emit a --min-sources 2 shortlist.
Higher levels spawn more subagents and cost more tokens — L5 is bounded only by the
token budget. PDF acquisition scales with the level too — fetch_pdfs.py --top of
10 / 30 / 50 / 100, and all (the whole corpus) at L5.
Outputs
Everything lands under ./literature_search/<topic>_<date>/ in the working directory:
literature_search/<topic>_<date>/
├── raw/<bucket>.json # per-source hits (one file per subagent)
├── corpus.json # deduplicated, ranked, provenance-tracked corpus
├── corpus.md # human-readable digest
├── pdfs/ # acquired original PDFs + manifest.json
└── summary.md # synthesized review
PDFs are named NN_<slug>.pdf by their corpus.json rank, and summary.md numbers each
paper [#NN] with the same rank — so a summary entry maps directly to its pdfs/NN_*.pdf
file and its manifest.json row.
Source Buckets
| Bucket | Databases |
|---|---|
| A · Preprints | arXiv (search · semantic · citation graph) |
| B · Citations | Semantic Scholar via Ai2 Asta (official MCP) + paper-search-mcp |
| C · DOI / published | Crossref, OpenAlex |
| D · Life sciences | PubMed, PMC, bioRxiv, medRxiv, Europe PMC |
| E · Open access | DOAJ, CORE, BASE, OpenAIRE, Zenodo, Unpaywall, HAL |
| F · Domain | DBLP (CS), IACR (crypto), SSRN (econ/law), CiteSeerX |
| G · Web | DuckDuckGo, GitHub, crawl4ai / firecrawl |
Domain → bucket routing
| Topic domain | Always | Plus |
|---|---|---|
| Physics / materials / cond-mat | A · B · C | E · G |
| CS / ML / systems | A · B · F (DBLP) | C · G (GitHub) |
| Biology / medicine / neuro | D · B · C | E |
| Cryptography / security | A · F (IACR) · B | G (GitHub) |
| Economics / social science / law | F (SSRN) · B · C | G |
| Math | A · B · C | F |
| Interdisciplinary / unknown | A · B · C · D | E · G |
Full per-bucket tool lists are inskills/scholar-megasearch/references/sources.md;
the orchestration templates (Workflow + Agent fan-out) and the record schema are inreferences/orchestration.md.
Repository Layout
scholar-megasearch/
├── README.md · README.ko.md · LICENSE
├── setup/
│ ├── install.sh # skills + venvs + MCP servers + resolved config
│ ├── requirements.txt # pinned search/acquisition deps
│ └── mcp.servers.json # MCP registration template for ~/.claude.json
└── skills/
├── scholar-megasearch/ # the skill
│ ├── SKILL.md
│ ├── references/{sources.md, orchestration.md}
│ └── scripts/{merge_corpus.py, fetch_pdfs.py, search_local.py}
└── arxiv-search/ # supporting venv-search skill
This repository contains only original MIT-licensed work (the two skills and the
setup scripts). The third-party MCP servers are not vendored — setup/install.sh
fetches the local ones (arxiv-mcp-server, paper-search-mcp) from upstream at install
time, and Semantic Scholar is the remote Ai2 Asta service. See Attribution.
Notes & Limitations
- PDF acquisition is open-access-first.
fetch_pdfs.pyonly uses free/legal
routes (a known OApdf_url, arXiv, Unpaywall) and verifies every file is a real%PDF-. Closed-access papers are flaggedneeds_mcpin the manifest; fetching
those is left to the session's MCP download tools. - arXiv rate-limits heavy fan-out (HTTP 429). Searchers stagger and lean on
Semantic Scholar / OpenAlex when arXiv pushes back. paper-search-mcpmust be the git-main build — the PyPI release omits
Crossref and OpenAlex. The installer handles this.- The claude.ai Scholar Gateway is best-effort — it may be absent in
headless/cron runs, so it is never a bucket's only source. - Honest synthesis.
summary.mdreports what was actually searched and which
sources failed; nothing is invented to fill a gap.
Attribution
The MCP servers are third-party — installed from their upstream sources bysetup/install.sh, or (for Asta) used as a remote service. None of their code is
redistributed here:
- Ai2 Asta Scientific Corpus Tool — the official Semantic Scholar MCP by the
Allen Institute for AI, used as a remote
service under Ai2's Asta License Agreement
and Terms of Use (no code vendored). - paper-search-mcp — openags/paper-search-mcp (pip install from git main)
- arxiv-mcp-server — launched on demand via
uvx
Semantic Scholar data returned through Asta is licensed ODC-BY and governed by the
Semantic Scholar API license: when
you publish results built on it, attribute Semantic Scholar (link back to
semanticscholar.org) and do not redistribute, sell, or sublicense the raw data.
Individual papers/abstracts may carry their own licenses (e.g. CC BY-NC).
Original work in this repository (the scholar-megasearch and arxiv-search skills
and the setup scripts) is released under the MIT License — this covers our
code only, not the third-party services or the data they return.
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi