arai
Health Warn
- License — License: Apache-2.0
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 5 GitHub stars
Code Fail
- fs module — File system access in .github/workflows/ci.yml
- rm -rf — Recursive force deletion command in bench/hot_path.sh
- rm -rf — Recursive force deletion command in bench/nomatch_path.sh
- rm -rf — Recursive force deletion command in bench/skip_path.sh
- rm -rf — Recursive force deletion command in install.sh
- child_process — Shell command execution capability in npm/install.js
- execSync — Synchronous shell command execution in npm/install.js
- fs.rmSync — Destructive file system operation in npm/install.js
- process.env — Environment variable access in npm/install.js
- fs module — File system access in npm/install.js
Permissions Pass
- Permissions — No dangerous permissions requested
This tool acts as an enforcement layer for AI coding assistants. It analyzes your instruction files (like CLAUDE.md or .cursorrules) and uses hooks to block or advise the AI from taking forbidden actions in your codebase.
Security Assessment
Overall Risk: Medium. The tool carries notable execution risks, primarily stemming from its installation process. The installation script (`install.sh`) and benchmark scripts use `rm -rf`, and the Node.js package (`npm/install.js`) utilizes `execSync` to run shell commands alongside destructive file system operations. While the core tool is written in Rust, these surrounding scripts have the potential to cause unintended data modification or deletion if mishandled. There are no hardcoded secrets and the tool does not request explicitly dangerous permissions, but users should be aware of its extensive file system access and shell execution capabilities.
Quality Assessment
The project is actively maintained, with its most recent push occurring today. It operates under the permissive and standard Apache-2.0 license. However, community trust and visibility are currently very low; the repository has only 5 stars on GitHub, meaning it has not yet undergone widespread peer review or battle-testing by the developer community.
Verdict
Use with caution — while the core functionality is useful and actively maintained, the underlying shell execution risks and lack of community auditing warrant a careful review of the scripts before integrating.
AI coding rules that actually work. Enforce instruction files via hooks — CLAUDE.md, .cursorrules, copilot-instructions, and more.
Arai
CLAUDE.md that actually works. One command. Runs locally. Zero cost.
Arai makes your AI coding assistant instruction files structurally enforceable — not just suggestions that get forgotten as context grows.
Quick Start
curl -sSf https://arai.taniwha.ai/install | sh
cd your-project
arai init
That's it. Arai discovers your instruction files, extracts the rules, classifies their intent, scans your codebase for context, and sets up Claude Code hooks so guardrails fire at the right moment.
What It Does
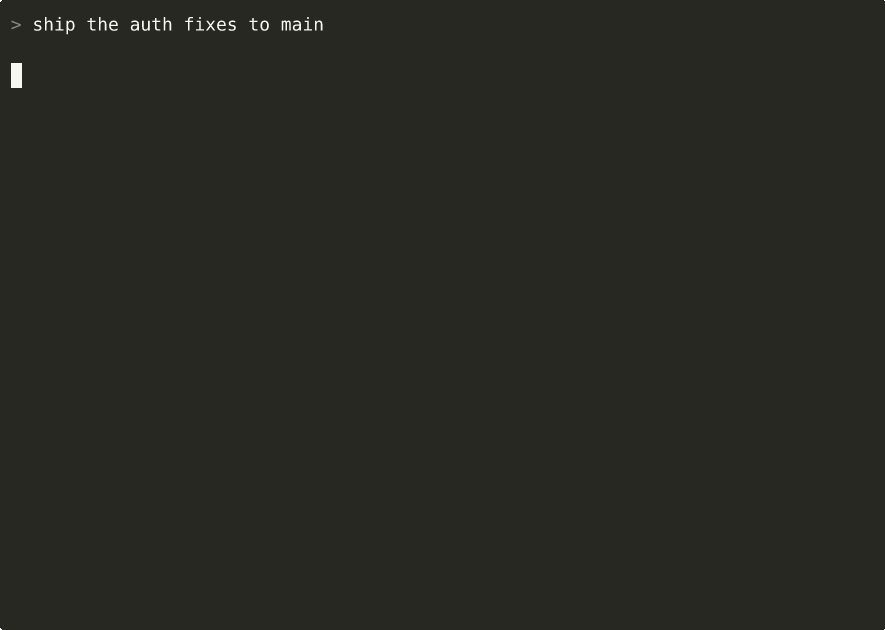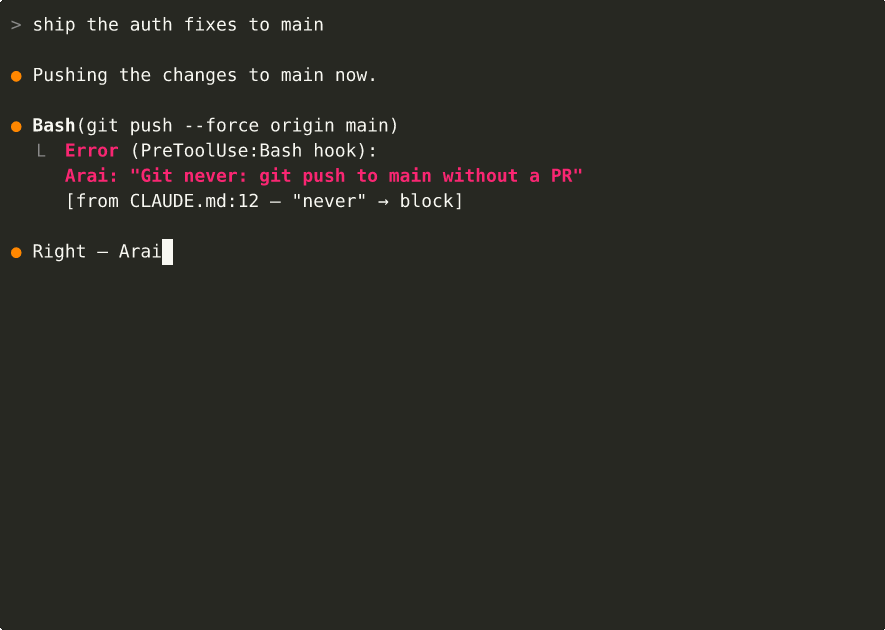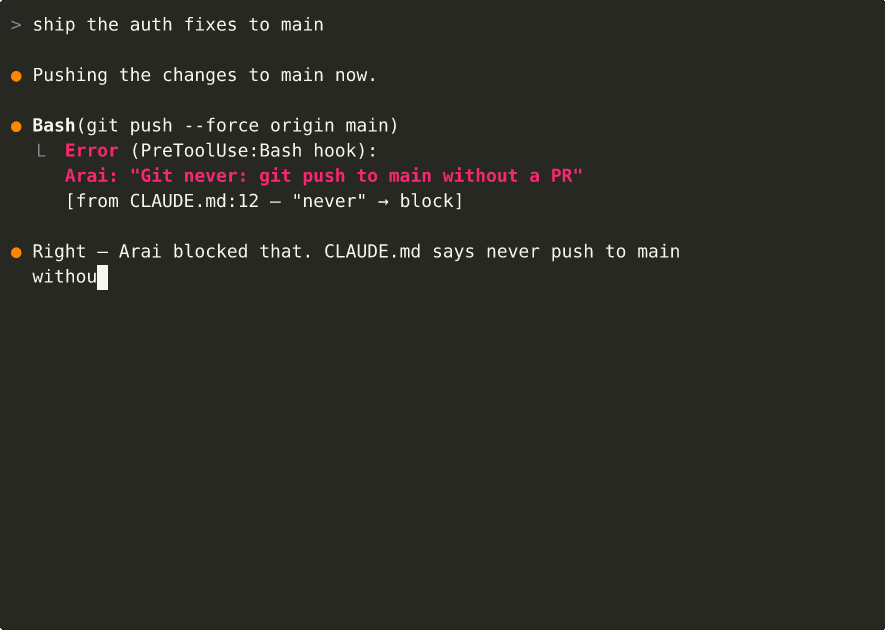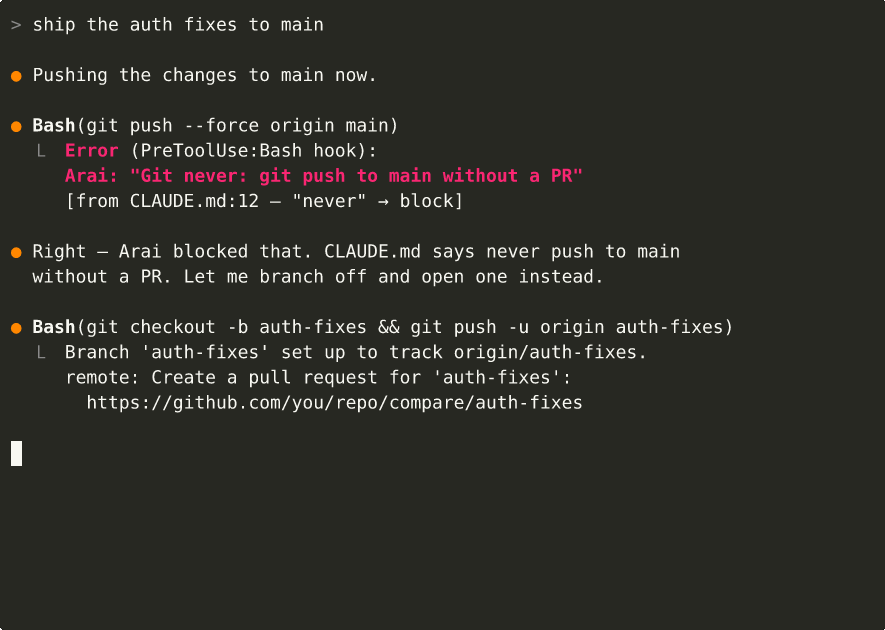
When Claude Code is about to do something your rules cover, Arai injects the relevant guardrail — right when it matters. Rules derived from prohibitive predicates (never, forbids, must_not) actually block the tool call instead of just advising.
You: "Create a new database migration"
PreToolUse: Write migrations/versions/001_add_users.py
→ Arai: deny
reason: "Alembic never: hand-write migration files"
[from CLAUDE.md:12, layer-1 imperative]
Claude: "I should use alembic revision --autogenerate instead..."
Rules only fire when relevant. No noise on ls. No repeating principles already in CLAUDE.md.
Every firing is written to a local audit log, and every PostToolUse is correlated with the matching PreToolUse to produce a compliance verdict — so you can measure whether the model actually honours the rules you wrote.
How It Works
- Discovers instruction files in your project and home directory
- Extracts rules by pattern-matching imperative language ("never", "always", "don't", "must")
- Classifies each rule's intent — what action it governs, which tools it applies to, when it should fire
- Scans your codebase with tree-sitter to understand which tools own which directories
- Tracks session state — knows if you've already run tests before pushing
- Fires only relevant rules at the right moment via Claude Code hooks
Supported Instruction Files
| File | Tool | Enforcement |
|---|---|---|
CLAUDE.md |
Claude Code | Hooks (block + advise) |
~/.claude/CLAUDE.md |
Claude Code (global) | Hooks (block + advise) |
~/.claude/projects/*/memory/*.md |
Claude Code memory | Hooks (block + advise) |
.cursorrules / .cursor/rules |
Cursor | MCP (advise) |
.windsurfrules |
Windsurf | MCP (advise) |
.github/copilot-instructions.md |
GitHub Copilot | Ingest only |
Rules from every file are parsed, classified, and stored the same way — but
enforcement strength depends on what surface the assistant exposes. Only
Claude Code has PreToolUse hooks, so only Claude Code can deny a tool
call. Cursor and Windsurf are MCP clients, so they get advisory enforcement
via arai mcp — the agent can list
guards, register new ones, and self-check recent decisions, but Arai cannot
block its tool calls. GitHub Copilot has no integration surface today; the
file is ingested so its rules show up in arai stats, arai diff, and
the audit log alongside the rest.
Smart Matching
Arai doesn't just do keyword matching. It understands your rules:
- Intent classification — "never hand-write migration files" only fires on Write, not Edit (editing existing migrations is fine)
- Code graph — writing to
migrations/versions/triggers alembic rules even if the file doesn't mention alembic, because sibling files import it - Content sniffing — detects
from alembic import opin file content being written - Session awareness — "never push without running tests" suppresses after tests have been run
- Timing routing — domain rules fire on tool calls, principles stay silent (already in CLAUDE.md)
- Broad imperative coverage — recognises
never/always/don't/must,should/shouldn't,cannot/refuse,make sure/be sure,consider/recommend, bareNo Xprohibitions, conditional shapes (When X, do Y/Before X: do Y/If X → do Y), and the section-awareUse Xstyle-guide pattern. Severity mapping mirrors grammatical weight:shouldisInform(soft),should notisBlock(the writer chose to call out a specific prohibition).
Compliance & audit
Beyond firing rules, Arai produces a tamper-evident local record of every
guardrail decision and correlates it with what the model actually did. This
is what tech leads and compliance reviewers want to see — the trail behind
the enforcement.
- Local JSONL audit log — one line per firing at
~/.arai/audit/<project>/<YYYYMMDD>.jsonl. Append-only, day-bucketed,
queryable witharai audit(filters:--since,--tool,--event,--outcome,--rule). - Derivation trace per firing — each rule entry records source file,
line number, and parser layer (from CLAUDE.md:42, layer-1 imperative).
Auditors can answer "why did this rule fire?" without code spelunking. - Compliance verdicts — every PostToolUse is correlated against recent
PreToolUse firings to produce Obeyed / Ignored / Unclear per rule.arai stats --by-rulerolls these up into per-rule ratios with a ⚠ flag
on rules the model is routing around. - Graduated enforcement — severity tiers (Block / Warn / Inform) derive
from rule predicate;arai severitypins individual rules so you can
ship a rule set in advise mode and escalate one at a time.ARAI_DENY_MODE=offis the project-wide rollback path. - Regression-tested policy —
arai testreplays scenarios through the
livematch_hookpipeline;arai recordcaptures real firings as
fixtures. Rule changes become CI assertions, not vibes. - No data egress — no network on the hook hot path. Anonymous opt-out
telemetry is architecturally separate from the audit log; they share no
code path. The audit data physically cannot leak via the telemetry
channel. - Supply-chain hardened — every install path verifies the binary
against publishedchecksums.txt(SHA-256).arai:extendsupstream
policy fetches refuse loopback / RFC1918 / link-local / cloud metadata
and disable redirects.
A complete enterprise / compliance-team feature inventory — mapped to the
controls a procurement reviewer or InfoSec team will ask about — is indocs/arai-compliance-features.pdf.
The Word source (.docx) is committed alongside it for editing.
Enrichment
Three tiers of rule understanding, each more accurate:
arai scan # Tier 1: Built-in verb taxonomy (free, instant)
arai scan --enrich # Tier 2: Sentence transformer model (local, ~80MB download)
arai scan --enrich-llm # Tier 3a: LLM classification via CLI
arai scan --enrich-api # Tier 3b: LLM classification via API (no CLI needed)
Configure your LLM:
# Via CLI tool (shell-out)
ARAI_LLM_CMD="claude -p" arai scan --enrich-llm
ARAI_LLM_CMD="ollama run llama3" arai scan --enrich-llm
# Via API (OpenAI-compatible endpoints)
ARAI_API_KEY=sk-... arai scan --enrich-api # OpenAI (default)
ARAI_API_URL=http://localhost:11434/v1 arai scan --enrich-api # Ollama (auto-detected)
ARAI_API_URL=https://api.groq.com/openai/v1 ARAI_API_KEY=gsk-... ARAI_API_MODEL=llama-3.3-70b-versatile arai scan --enrich-api
# Or in ~/.arai/config.toml
[enrich]
llm_command = "llm -m gpt-4o-mini" # for --enrich-llm
api_url = "https://api.openai.com/v1" # for --enrich-api
api_key_env = "OPENAI_API_KEY"
model = "gpt-4o-mini"
Commands
arai init # Discover, extract, classify, scan, set up hooks
arai status # Show what's being enforced
arai guardrails # List all active rules
arai why "git push --force" # Explain which rules would fire (dry-run, no audit write)
arai scan # Re-scan instruction files
arai scan --code # Also scan source code (tree-sitter AST)
arai scan --enrich-llm # Enhance rules via LLM CLI
arai scan --enrich-api # Enhance rules via API (OpenAI-compatible)
arai add "Never X" # Add a rule manually
arai audit # Inspect the local log of rule firings
arai audit --outcome=ignored # Compliance verdicts where the model ignored a rule
arai audit --rule alembic # Filter audit by rule subject/predicate/object substring
arai stats # Aggregate audit log — top rules, compliance, token economics
arai stats --by-rule # Just the per-rule compliance + token economics
arai severity alembic block # Pin a rule's severity (incremental deny rollout)
arai severity --reset alembic # Drop the override; severity reverts to predicate-derived
arai diff CLAUDE.md # Preview rule-set delta before saving an edit
arai test scenarios.json # Replay synthetic hook scenarios against rules
arai record --since=1h # Capture recent firings as a scenario skeleton
arai lint CLAUDE.md # Parse a file and preview extracted rules
arai trust # Manage URLs trusted for shared-policy extends
arai mcp # Run the MCP server (stdio) for agent-authored guards
arai upgrade --full # Switch to full binary (with ONNX enrichment)
Deny mode — actually block bad actions
Starting in v0.2.3, Arai no longer just advises: rules derived from
prohibitive predicates (never, forbids, must_not) emitpermissionDecision: "deny" so Claude Code refuses the tool call. Advisory
rules (always, requires, prefers) keep the previous behaviour.
Severity is inferred from the predicate at extract time:
| Predicate | Severity | Hook behaviour |
|---|---|---|
never, forbids, must_not |
block |
permissionDecision: "deny" + reason |
always, requires, enforces |
warn |
permissionDecision: "allow" + context |
prefers, learned_from |
inform |
permissionDecision: "allow" + context |
Rolling Arai out incrementally? Flip deny mode off at the env level:
ARAI_DENY_MODE=off # advisory-only — rules still fire in additionalContext
Useful pattern: ship Arai in advise mode for a week, watch arai audit --outcome=ignored, tune the rules the model keeps flouting, then enable
deny mode when the rule set is trustworthy.
Compliance tracking
After every PostToolUse, Arai correlates the call against recent
PreToolUse firings in the same session and emits a Compliance event to
the audit log per rule:
- obeyed — forbidden phrase absent from the executed command (for
prohibitive rules), or the required evidence present (for affirmative
rules). - ignored — forbidden phrase still in the executed command.
The model ran the thing anyway (either deny was off or Claude Code
chose to proceed). - unclear — not enough signal to decide (short object text, or
affirmative rule without evidence in this call).
arai audit --event=Compliance # all verdicts
arai audit --outcome=ignored # shortcut for the painful ones
arai audit --outcome=obeyed # show the rules doing their job
This closes the feedback loop the audit log was missing: not just which
rules fired, but which ones the model actually honoured.
arai why — explain before you commit
arai why <action> replays a hypothetical tool call through the live
matching pipeline and prints the rules that would fire, with severity,
derivation (source + line + parser layer), and match percentage. No audit
write; read-only against the rule set.
arai why "git push --force origin main"
arai why --tool Write /src/migrations/001_init.py
arai why --tool Bash --event PostToolUse "rm -rf /data"
arai why "git push --force" --json # machine-readable
Use it to: debug "why did that rule fire?", preview new rules before
committing them, or include the output in a PR description when you
change a CLAUDE.md.
Rule expiry — self-pruning rules
Annotate rules with (expires YYYY-MM-DD) or (until YYYY-MM-DD) at the
end of the line. The annotation is stripped from the rule body at parse
time and stored separately; load_guardrails filters out expired rows so
the rule stops firing on its own, without you having to remember to
clean it up.
- Never touch the old auth module (expires 2026-09-01)
- Always rebase against release-1.8 until 2026-12-31
- Prefer the new payment SDK over the legacy one (until 2027-06-30)
Perfect for learned_from incidents that have a shelf life, migration
windows, and "temporarily forbid X until we finish the refactor" rules.
Audit log
Every time a rule fires, Arai appends one line to a local JSONL log at~/.arai/audit/<project-slug>/<YYYYMMDD>.jsonl. The log captures the
hook event, the tool that was called, a truncated prompt preview, the
decision (inject, deny, review), and every rule that matched —
with source file, line number, parser layer, severity, and confidence.
Nothing leaves your machine — this is separate from the anonymous
usage telemetry below.
arai audit # Today's firings, table view
arai audit --since=7d # Last week
arai audit --tool=Bash # Only Bash tool calls
arai audit --event=PreToolUse # Only pre-tool-use firings
arai audit --event=Compliance # Compliance verdicts (Pre/Post correlation)
arai audit --outcome=ignored # Shortcut: Compliance events marked ignored
arai audit --rule alembic # Filter to firings/verdicts touching this rule
arai audit --json # JSONL stream (pipe-friendly)
--rule is a case-insensitive substring match against the rule's
subject, predicate, or object — the same shape arai severity uses.
Pairs naturally with --outcome=ignored to answer "every time the
alembic rule was ignored this week".
Useful for answering:
- "Why did Claude suddenly change approach halfway through?" —
look up the firing, see which rule matched. - "Which rules are actually load-bearing?" — sort firings by rule,
prune rules that never trigger. - "Did the guardrail fire before that regrettable git push?" —
grep by session id.
Status — health check your rule set
arai status shows how many rules are loaded, where they came from,
and when they were last scanned. As of v0.2.2 it also surfaces two
common rule-set health issues:
- Duplicate rules — the same (subject, predicate, object) ingested
from more than one source file. Usually safe to consolidate into
one source to reduce drift. - Opposing predicates — the same subject carries both a
prohibitive predicate (never,must_not,avoid) and a required
predicate (always,must,requires,ensure). Not always a
real conflict (the objects may differ), but worth a human look.
These are advisory only — the hook path ignores them. Fix them at the
source.
Stats — aggregate the audit log
arai stats rolls up the same JSONL arai audit tails and answers
the questions every maintainer asks after a few weeks of use:
arai stats # Top rules, compliance, token economics
arai stats --since=30d # Window to the last month
arai stats --top=5 # Show only top 5 per section
arai stats --by-rule # Compliance + token economics only
arai stats --json # Machine-readable for dashboards
Output includes: total firings, most-fired rules, tools attracting the
most guardrails, day-by-day activity, and a per-rule compliance
roll-up — for every rule that has fired, how many Pre/Post pairs
ended up obeyed vs ignored, plus a ratio:
Per-rule compliance
fires obeyed ignored unclear ratio rule
12 11 1 0 92% alembic must_not: hand-write migrations
7 4 3 0 57% git must_not: --no-verify ⚠
9 9 0 0 100% cargo always: test before commit
The ⚠ flag highlights rules with low ratios and enough volume to
mean it — these are the ones to either rewrite (rule subject too
narrow / object too vague) or escalate via arai severity (see
below) once you trust the wording.
The ratio is computed once per Pre firing using a first-
definitive-wins rule: the first non-unclear Compliance verdict
correlated against a Pre is the verdict for that Pre, regardless
of how many subsequent Posts also fall inside the 5-minute
correlation window. So a rule that fires once and is honored stays
at 1 obeyed / 1 fire, not 8 obeyed / 1 fire just because eight
unrelated commands followed.
Nothing leaves the machine — stats are a local view over your own
audit log.
Token economics — calibrated estimates
arai stats also surfaces a token economics section with
calibrated estimates of how Arai is affecting your model's token
burn. Two streams contribute:
Token economics (estimates)
12 repeat-injection suppressions (~600 tokens, 50 ea.)
4 denied-and-honored mistakes (~8000 tokens, 2000 ea.)
17 advised-and-honored events (~8500 tokens, 500 ea.)
total estimated tokens saved: ~17100
(calibrated estimates, not measurements)
- Repeat-injection suppressions — when a rule fires a second
time in the same session, Arai emits a compact "still: subject
predicate object" line instead of re-injecting the full source /
layer / severity payload. The model already has that context from
the first firing. The 50-token estimate is the rough delta
between the full and compact forms. - Denied-and-honored mistakes — a
block-severity rule fired,
the model would otherwise have run a destructive action, and the
PostToolUse correlation confirms it didn't. The 2000-token
estimate is a conservative bound on what "fix the mess" cycles
cost (revert files, undo migrations, rollback deploys). - Advised-and-honored events — a
warnorinformrule fired
and the model complied. Lower confidence saving (the model might
have done the right thing anyway), so a smaller 500-token
estimate.
These are estimates, not measurements. The constants live insrc/stats.rs and are documented there; treat the
total as an order-of-magnitude reading, not a precise number. If
you want to see the underlying counts, arai stats --json exposes
the token_economics object with all three streams broken out.
Severity — per-rule deny-mode rollout
arai severity pins a rule's enforcement strength so re-runningarai scan won't reset it to the predicate-derived classification.
Use it for incremental deny-mode rollout: ship the rule set in
advise mode (ARAI_DENY_MODE=off), watch arai stats --by-rule,
and flip individual rules into block once the model is honouring
them in the wild — without forcing the whole rule set into a strict
mode it isn't ready for yet.
arai severity # List active overrides
arai severity alembic block # Pin every rule whose subject/object
# contains "alembic" to block
arai severity git warn # Demote git rules to advise-only
arai severity --reset alembic # Drop the override; severity reverts
# to the predicate-derived value
arai severity alembic block --json # Machine-readable list of changes
Pattern matching is case-insensitive substring against the rule's
subject or object, so arai severity migrate covers bothalembic must_not: hand-write migrations and migrations require: backfill_plan.
Overrides survive arai scan and arai init — they live in their
own column and are never touched by re-classification. Drop one with--reset when you're ready to re-derive severity from the rule's
predicate.
Diff — preview rule-set changes
arai diff <file> shows what changes a candidate edit to an
instruction file would make to the live rule set — added, removed,
moved — before you save and run arai scan. Read-only against
the store; pairs with arai lint (preview a file in isolation)
and arai why (preview a single tool call).
arai diff CLAUDE.md # Plain table view
arai diff memory/feedback_testing.md --json # For pre-commit hooks
Output is grouped into three sections — Added (rules in the file
that aren't in the store yet), Removed (rules in the store whose
text isn't in the new file), Moved (same rule, different line
number — caught when you re-order a file without changing its rules).
JSON output keeps the same shape for CI.
Lint — preview what a file produces
arai lint <file> parses an instruction file and prints every rule it
would extract along with the intent classification, without touching
the DB. Use it to iterate on CLAUDE.md wording and see the effect
before you commit.
arai lint CLAUDE.md
arai lint memory/feedback_testing.md --json # machine-readable
Output for each rule: subject / predicate / object, the classified
action (Create / Modify / Execute / General), the hook timing it routes
to (ToolCall / Stop / Start / Principle), and which tools the rule
applies to.
Test — regression harness for rules
arai test replays synthetic hook payloads through the samematch_hook pipeline the live hook handler uses, so rule changes get
caught before they affect a real session.
The canonical alembic example is
checked in — run it after arai init on any repo with an alembic rule
in CLAUDE.md:
arai test scenarios/alembic-migration.json
Scenario files are JSON:
{
"scenarios": [
{
"name": "force-push triggers the git guardrail",
"hook": {
"hook_event_name": "PreToolUse",
"tool_name": "Bash",
"tool_input": { "command": "git push --force origin master" }
},
"expect": {
"matches_subject": ["git"],
"does_not_match_subject": ["alembic"],
"min_matches": 1
}
}
]
}
arai test scenarios/guards.json
arai test scenarios/guards.json --json # structured pass/fail for CI
Exit code is non-zero when any scenario fails. Matches are checked by
subject substring because full SPO triples tend to drift across
re-ingest.
Record — seed scenarios from real firings
arai record turns entries in the audit log into scenario skeletons
so you don't hand-write regression tests. Flow: run Claude Code, hit a
rule firing you want pinned, arai record --since=1h > tests.json,
tune the expectations, check in.
arai record --since=1h # last hour
arai record --since=7d --tool=Bash # only Bash firings from the last week
arai record --limit=50 # cap audit entries scanned
Deduplicates by (tool, prompt) so repeated identical firings collapse
to one scenario. Each scenario's expect seeds matches_subject with
whatever actually fired and min_matches: 1 — tune from there.
Runtime-capturing new rules (as opposed to testing existing ones) is
a different loop: that goes through the MCP arai_add_guard tool,
documented below.
Shared policies — arai:extends
Instruction files can inherit rules from a trusted upstream URL. This
is the "org-wide CLAUDE.md" pattern without a policy service — just
another markdown file hosted wherever you like.
Declare the upstream in your CLAUDE.md:
<!-- arai:extends https://example.com/standards/rust-backend.md -->
# My project rules
- Never publish artifacts before tag push
Then trust the URL:
arai trust --add https://example.com/standards/rust-backend.md
arai trust # List trusted URLs
arai trust --remove <url> # Revoke
Ārai never fetches a URL that isn't explicitly trusted. HTTPS only,
512 KB size cap, 24-hour cache with stale-while-error fallback, and
extends are not recursive — the fetched file can't pull in further
URLs. On arai init, trusted upstream content is inlined ahead of the
local rules before the parser runs, so the rest of the pipeline sees
one merged file.
MCP: agent-authored guardrails
arai mcp is also the integration path for assistants that don't have a
PreToolUse hook surface. Cursor and Windsurf are both MCP clients — point
them at arai mcp and the agent can read the same rule set Claude Code
sees, register new guards mid-session, and self-check recent decisions.
The blocking path is still Claude-Code-only (no other assistant exposes
a deny hook today), but everything else — rule lookup, agent-authored
guards, decision history — is shared.
arai mcp runs a Model Context Protocol
server on stdio. Three tools, exposed to any MCP-capable agent:
| Tool | What it does |
|---|---|
arai_add_guard(rule, reason?) |
Register a new guardrail mid-session. Takes effect on the next PreToolUse hook — same enforcement path as rules in your CLAUDE.md. |
arai_list_guards(pattern?) |
List active guardrails, optionally substring-filtered, so the agent can check what constraints are live before acting. |
arai_recent_decisions(session_id?, limit?, since?) |
Look up recent Ārai decisions (deny / inject / review) so the agent can self-check after a refusal — closes the model-side feedback loop. |
This closes two gaps instruction files don't cover. First, when an agent
discovers a rule mid-session ("from now on, never write to /etc",
"always run the full test suite before pushing"), it now has
somewhere to register it for deterministic enforcement rather than
hoping context retention holds. Second, after a deny, the agent can
call arai_recent_decisions to see what it was just refused for —
useful for avoiding "try the same thing twice" loops when a single
rule keeps getting hit.
Register it with Claude Code by adding to your MCP settings:
{
"mcpServers": {
"arai": {
"command": "arai",
"args": ["mcp"]
}
}
}
For Cline (in cline_mcp_settings.json, or via the MCP UI):
{
"mcpServers": {
"arai": {
"command": "arai",
"args": ["mcp"],
"disabled": false,
"autoApprove": []
}
}
}
For Cursor and Windsurf, follow each tool's MCP server registration UI
and point it at the same arai mcp command — the protocol is identical.
Prerequisite: arai must be on your PATH. The install script, cargo install arai, npm install -g @taniwhaai/arai, and the Homebrew tap all
put it there.
Installation
# Install script (recommended)
curl -sSf https://arai.taniwha.ai/install | sh
# Full binary (with local sentence transformer)
ARAI_FULL=1 curl -sSf https://arai.taniwha.ai/install | sh
# npm
npm install -g @taniwhaai/arai
# Cargo
cargo install arai
cargo install arai --features enrich # with ONNX model support
# Homebrew
brew install taniwhaai/tap/arai
# Docker (sandboxed install or CI-side enforcement)
docker build -t arai .
docker run --rm -i -v "$(pwd)/.arai:/home/arai/.arai" arai
# Or via compose with a persistent named volume:
docker compose run --rm arai
Performance
| Operation | Median | p95 |
|---|---|---|
| Hook check (skip-tool — Read/Glob/Agent) | ~22 ms | ~36 ms |
| Hook check (full match pipeline) | ~32 ms | ~55 ms |
| Full init | <200 ms | — |
End-to-end wall clock per Claude Code tool call, measured bybench/hot_path.sh. Cost is dominated by Rust binary fork+exec
(~20 ms floor on Linux/WSL); rule matching itself is sub-ms above 200
rules thanks to the LEFT-JOIN'd intent and Aho-Corasick content sniffing.
Rule count between 50 and 500 doesn't materially move the median —
matching is no longer the bottleneck.
Telemetry
Arai collects anonymous usage data to help us understand if guardrails are actually useful. We track:
- Whether a rule fired and on which tool
- Hook response latency
- Rule counts and enrichment tier on init
We never collect file paths, rule text, code content, API keys, or anything that could identify you or your codebase.
Opt out at any time:
export ARAI_TELEMETRY=off # or DO_NOT_TRACK=1
Built By
Taniwha.ai — extracted from the Kete code intelligence platform.
License
MIT / Apache-2.0
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found