mimirs
Health Gecti
- License — License: Apache-2.0
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 10 GitHub stars
Code Gecti
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
Local MCP server that gives AI coding agents persistent, searchable memory of your codebase
MIMIRS
Named after Mímir, the Norse god of wisdom and knowledge.
Persistent project memory for AI coding agents. One command to set up, nothing to maintain.


Your agent starts every session blind — guessing filenames, grepping for keywords, burning context on irrelevant files, and forgetting everything you discussed yesterday.
On a real project, that costs 380K tokens per prompt and 12-second response times.
After indexing with mimirs: 91K tokens, 3 seconds. A 76% reduction — depending on your model and usage, that's hundreds to thousands in monthly API savings.
No API keys. No cloud. No Docker. Just bun and SQLite.
Works with: Claude Code · Cursor · Windsurf · JetBrains (Junie) · GitHub Copilot · any MCP client
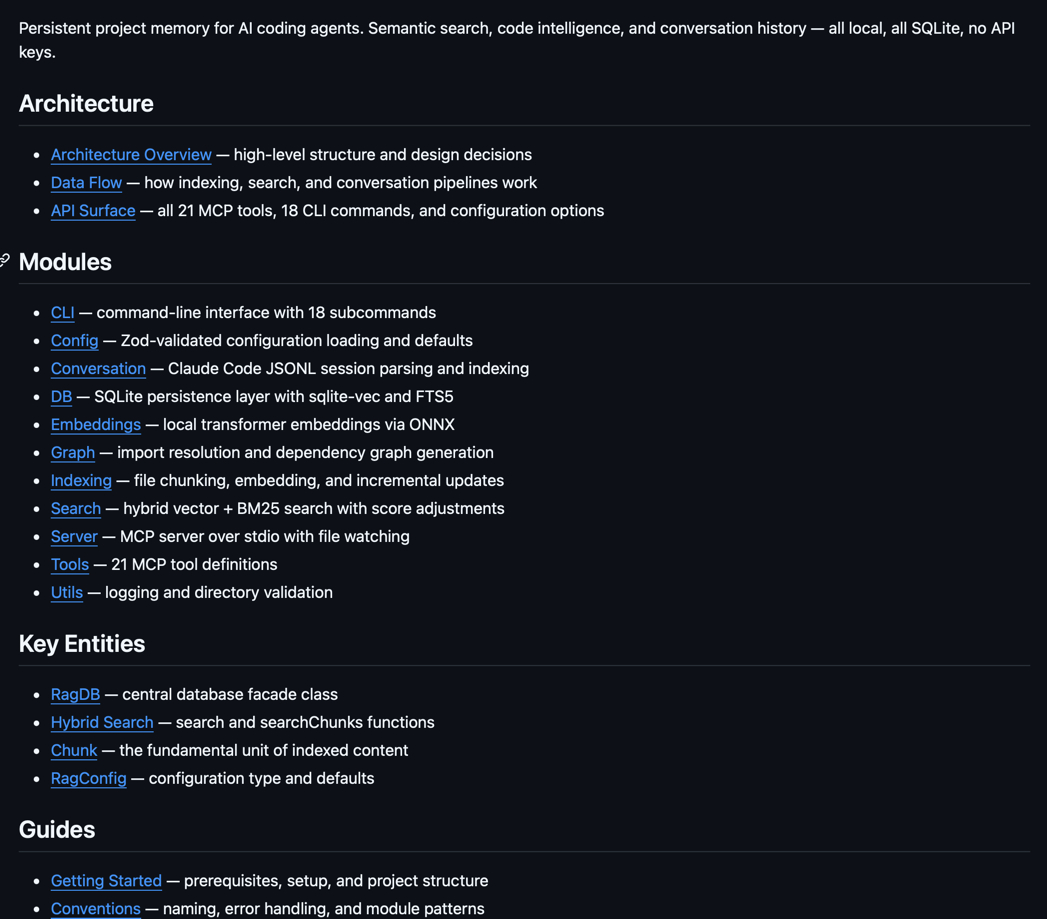
Auto-generated project wiki
One command turns your codebase into a structured, cross-linked markdown wiki — architecture docs, module pages, entity pages, guides, and Mermaid diagrams — all built from the semantic index. See the wiki generated for this project →
Search quality
93–98% recall. Benchmarked on four real codebases across three languages (120 queries total) — from 97 files to 8,553 — with known expected results per query. Full methodology in BENCHMARKS.md.
| Codebase | Language | Files | Queries | Recall@10 | MRR | Zero-miss |
|---|---|---|---|---|---|---|
| mimirs | TypeScript | 97 | 30 | 98.3% | 0.683 | 0.0% |
| Excalidraw | TypeScript | 693 | 30 | 96.7% | 0.442 | 3.3% |
| Django | Python | 3,090 | 30 | 93.3% | 0.688 | 6.7% |
| Kubernetes | Go | 8,553 | 30 | 90.0% | 0.589 | 10.0% |
Kubernetes excludes test files and demotes generated files. With searchTopK: 15, recall reaches 100%. See Kubernetes benchmarks for details.
How it compares
| mimirs | No tool (grep + Read) | Context stuffing | Cloud RAG services | |
|---|---|---|---|---|
| Setup | One command | Nothing | Nothing | API keys, accounts |
| Token cost | ~91K/prompt | ~380K/prompt | Entire codebase | Varies |
| Search quality | 93–98% Recall@10 | Depends on keywords | N/A (everything loaded) | Varies |
| Code understanding | AST-aware (24 langs) | Line-level | None | Usually line-level |
| Cross-session memory | Conversations + checkpoints | None | None | Some |
| Privacy | Fully local | Local | Local | Data leaves your machine |
| Price | Free | Free | High token bills | $10-50/mo + tokens |
What it gives your agent
Find code by meaning, not filename.
"Where do we handle authentication errors?" → mimirs finds middleware/session-guard.ts. Hybrid vector + BM25 search, boosted by dependency graph centrality.
Remember past sessions.
Conversation transcripts are indexed in real time. Three days later, your agent can search for "why did we switch to JWT?" and get the exact discussion.
Know what changed since last time.git_context shows uncommitted changes and recent commits in one call, so agents don't propose edits that conflict with in-progress work.
Leave notes for future sessions.annotate attaches persistent caveats to files or symbols — "known race condition", "blocked on auth rewrite" — that surface automatically in search results.
Mark decisions, not just code.
Checkpoints capture milestones, direction changes, and blockers. Searchable across sessions so context doesn't evaporate.
Understand codebase structure.
Dependency graphs, reverse-dependency lookups, and find_usages show the blast radius before any refactor.
Generate a project wiki.generate_wiki produces a structured, cross-linked markdown wiki — architecture docs, module pages, entity pages, guides, and Mermaid diagrams — all built from the semantic index.
Expose documentation gaps.
Analytics log every query locally — nothing leaves your machine. Zero-result and low-relevance queries reveal what's missing from your docs.
Quick start
1. Install SQLite (macOS)
Apple's bundled SQLite doesn't support extensions:
brew install sqlite
2. Set up your editor
bunx mimirs init --ide claude # or: cursor, windsurf, copilot, jetbrains, all
This creates the MCP server config, editor rules, .mimirs/config.json, and .gitignore entry. Run with --ide all to set up every supported editor at once.
3. Try the demo (optional)
bunx mimirs demo
Claude Code plugin
For deeper integration, mimirs is also available as a Claude Code plugin. In a Claude Code session:
/plugin marketplace add https://github.com/TheWinci/mimirs.git
/plugin install mimirs
The plugin adds SessionStart (context summary), PostToolUse (auto-reindex on edit), and SessionEnd (auto-checkpoint) hooks. No CLAUDE.md instructions needed — the plugin's built-in skill handles tool usage.
How it works
Parse & chunk — Splits content using type-matched strategies: function/class boundaries for code (via tree-sitter across 24 languages), headings for markdown, top-level keys for YAML/JSON. Chunks that exceed the embedding model's token limit are windowed and merged.
Embed — Each chunk becomes a 384-dimensional vector using all-MiniLM-L6-v2 (in-process via Transformers.js + ONNX, no API calls). Vectors are stored in sqlite-vec.
Build dependency graph — Import specifiers and exported symbols are captured during AST chunking, then resolved to build a file-level dependency graph.
Hybrid search — Queries run vector similarity and BM25 in parallel, blended by configurable weight. Results are boosted by dependency graph centrality and path heuristics.
read_relevantreturns individual chunks with entity names and exact line ranges (path:start-end).Watch & re-index — File changes are detected with a 2-second debounce. Changed files are re-indexed; deleted files are pruned.
Conversation & checkpoints — Tails Claude Code's JSONL transcripts in real time. Agents can create checkpoints at important moments for future sessions to search.
Annotations — Notes attached to files or symbols surface as
[NOTE]blocks inline inread_relevantresults.Analytics — Every query is logged. Analytics surface zero-result queries, low-relevance queries, and period-over-period trends.
Supported languages
AST-aware chunking via bun-chunk with tree-sitter grammars:
TypeScript/JavaScript, Python, Go, Rust, Java, C, C++, C#, Ruby, PHP, Scala, Kotlin, Lua, Zig, Elixir, Haskell, OCaml, Dart, Bash/Zsh, TOML, YAML, HTML, CSS/SCSS/LESS
Also indexes: Markdown, JSON, XML, SQL, GraphQL, Protobuf, Terraform, Dockerfiles, Makefiles, and more. Files without a known extension fall back to paragraph splitting.
Documentation
Stack
| Layer | Choice |
|---|---|
| Runtime | Bun (built-in SQLite, fast TS) |
| AST chunking | bun-chunk — tree-sitter grammars for 24 languages |
| Embeddings | Transformers.js + ONNX (in-process, no daemon) |
| Embedding model | all-MiniLM-L6-v2 (~23MB, 384 dimensions) — configurable |
| Vector store | sqlite-vec (single .db file) |
| MCP | @modelcontextprotocol/sdk (stdio transport) |
| Plugin | Claude Code plugin with skills + hooks |
All data lives in .mimirs/ inside your project — add it to .gitignore.
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi