verdict-dfir
Health Uyari
- License — License: Apache-2.0
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 6 GitHub stars
Code Gecti
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
VERDICT — a DFIR agent (Claude Code as the engine) that produces a signed, offline-verifiable verdict. SANS Find Evil! 2026.
![]()
![]()
![]()
![]()
![]()
Digital forensics & incident response with a verdict you can prove.
VERDICT automates the repeatable mechanics of a Windows-host DFIR investigation — memory images,
EVTX logs, disk artifacts, and network captures — and produces an evidence-bound verdict
(SUSPICIOUS / INDETERMINATE / NO_EVIL) backed by a cryptographic chain of custody any third
party can verify offline. It runs as a Claude Code agent over a
narrow, typed, read-only tool surface, so every Finding cites the exact tool call that produced it.
There is no separate application server — Claude Code is the engine. Running scripts/verdict <evidence> (or claude) in this repo turns that session into the analyst: it opens the Case, drives
the 43 typed read-only tools, runs the verifier, and signs the verdict. VERDICT reduces the friction
of repeatable DFIR mechanics; it is not an autonomous responder — the analyst approves the plan, and
the verifier re-runs every cited tool before any Finding reaches the report.
Install and run
| Need | Start here |
|---|---|
| Cold-clone install | INSTALL.md |
| Three-command quickstart | QUICKSTART.md |
| Every run mode, flag, and output file | docs/using/running-verdict.md |
| Failure-mode fixes | docs/troubleshooting.md |
git clone --depth 1 https://github.com/TimothyVang/verdict-dfir.git verdict
cd verdict
bash scripts/setup # toolchain + DFIR binaries + both MCP servers + preflight doctor
scripts/verdict <path-to-evidence>
Point it at supported evidence — a memory image, EVTX log, disk image (.E01 / .dd), packet
capture, Velociraptor collection, or a whole multi-host case folder. Output lands intmp/auto-runs/<case-id>/. Unsupported formats degrade to custody/limitation records rather than a
broad clearance claim.
Prefer Claude Code interactively? Run claude in the repo and type /verdict <evidence> orinvestigate <evidence>.
What you get
Every run writes a self-contained case directory:
| Artifact | What it is |
|---|---|
audit.jsonl |
Append-only, hash-chained log of every tool call and Finding (prev_hash per record) |
verdict.json |
The evidence-bound verdict and Findings, each citing a tool_call_id and a confidence tier |
coverage_manifest.json |
Per-artifact-class scope ledger: available / attempted / parsed / failed / unsupported / not-supplied — the explicit anti-overclaim boundary |
run.manifest.json |
Merkle root over canonical tool outputs plus signature metadata — verifiable offline |
REPORT.md / REPORT.html / REPORT.pdf |
Analyst report: Findings, ATT&CK coverage, normalized timeline, next actions. REPORT.md is always written; REPORT.html (needs pandoc) and REPORT.pdf (needs headless Chrome) are produced when those tools are present |
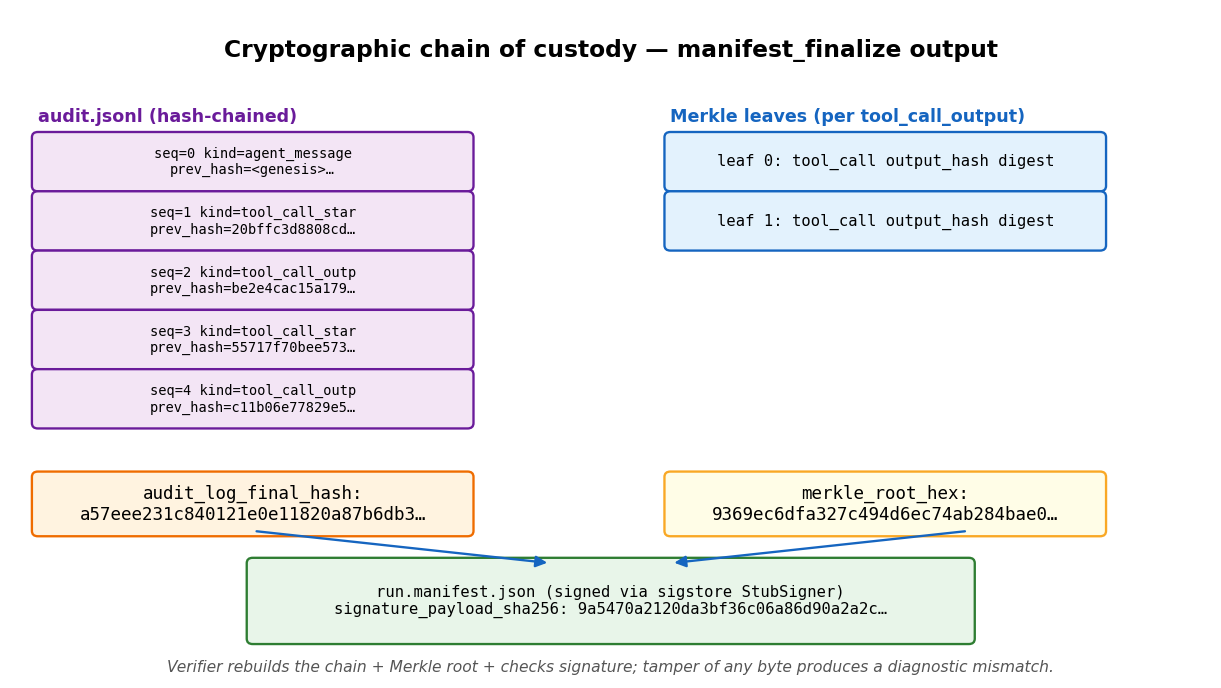
Each run seals into a hash-chained audit log, a Merkle root over canonical tool outputs, and a signed manifest — verifiable offline with manifest_verify.
See it run
Every capture below is a real run, not a mockup. Full gallery: docs/showcase/.
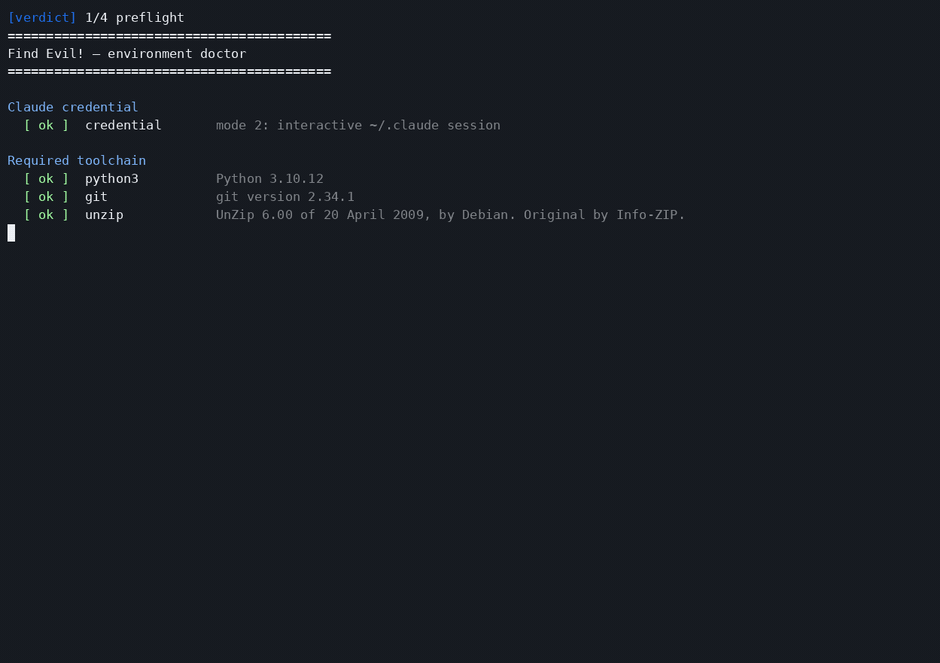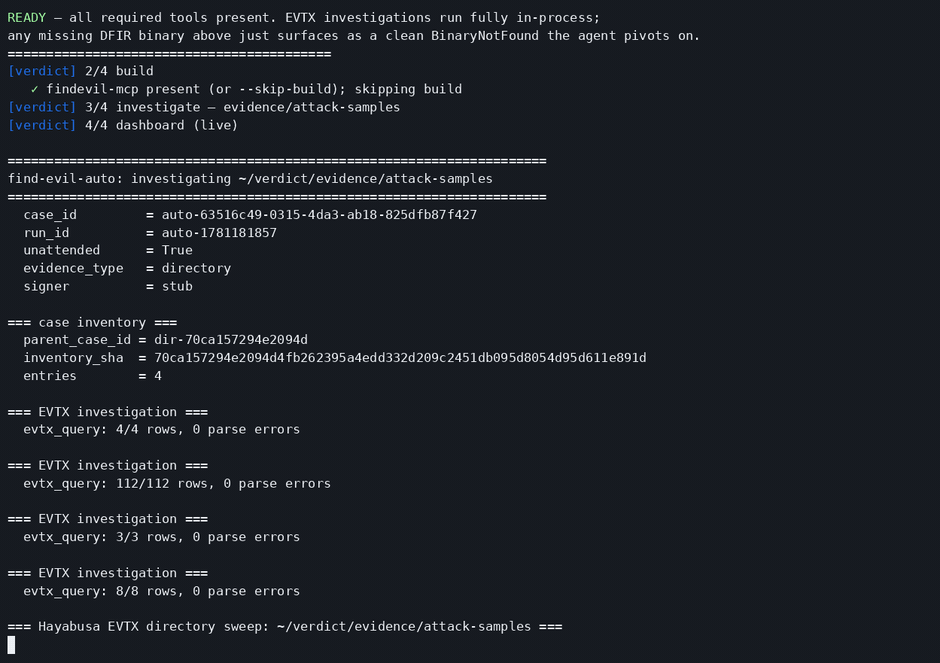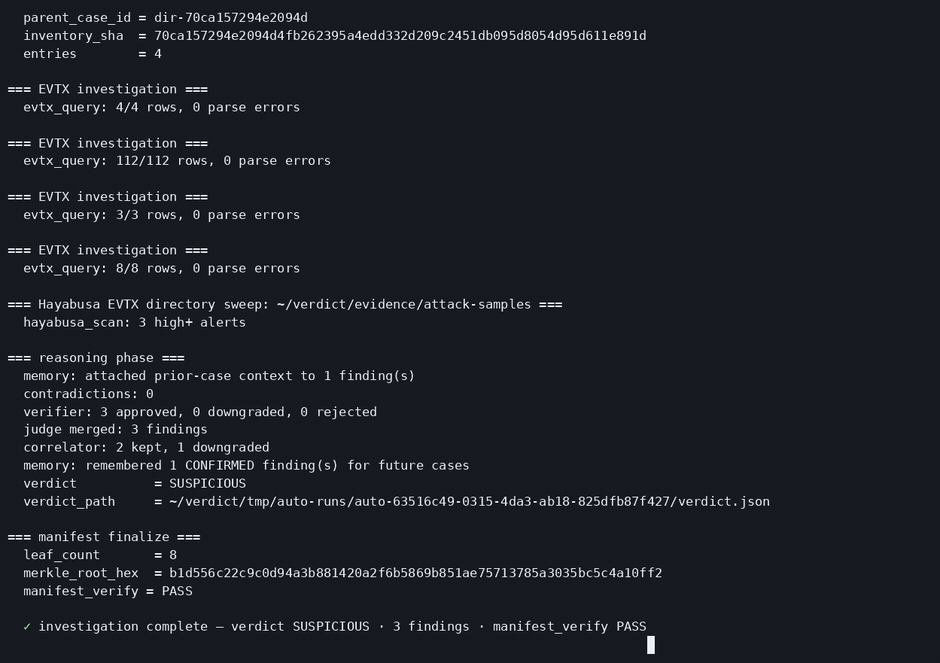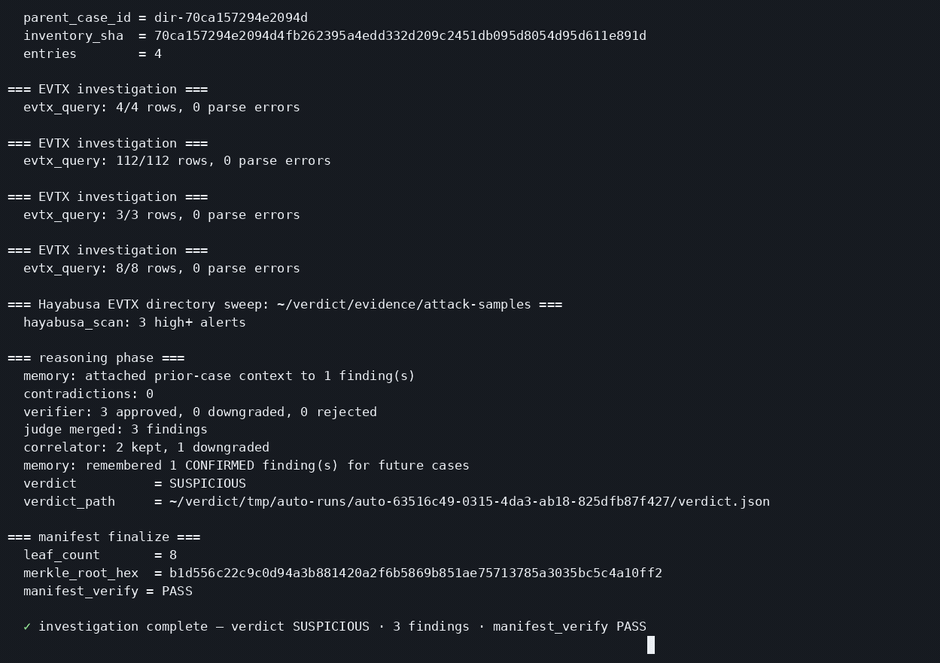
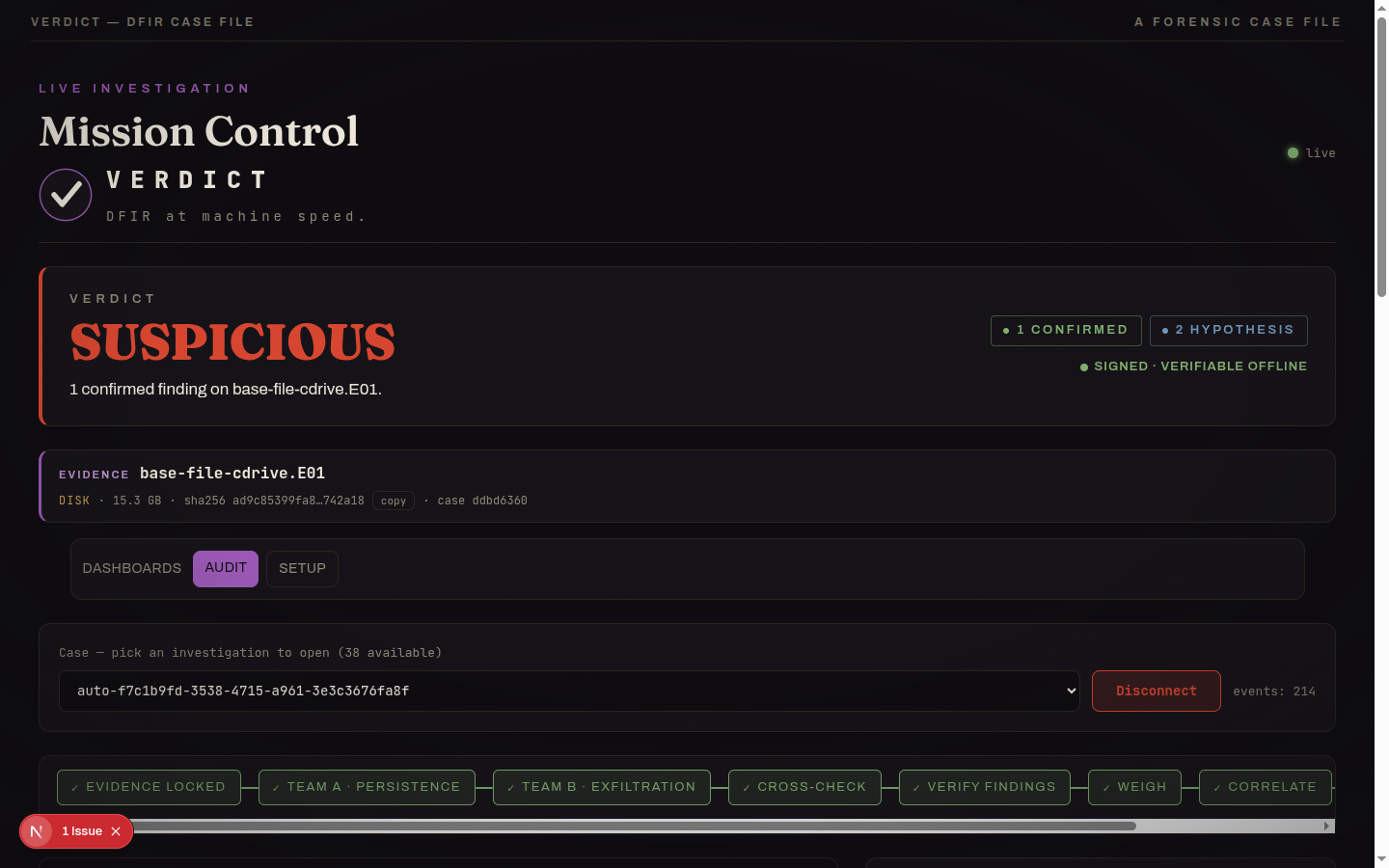
One command, the typed DFIR pipeline, a signed SUSPICIOUS verdict with manifest_verify = PASS.
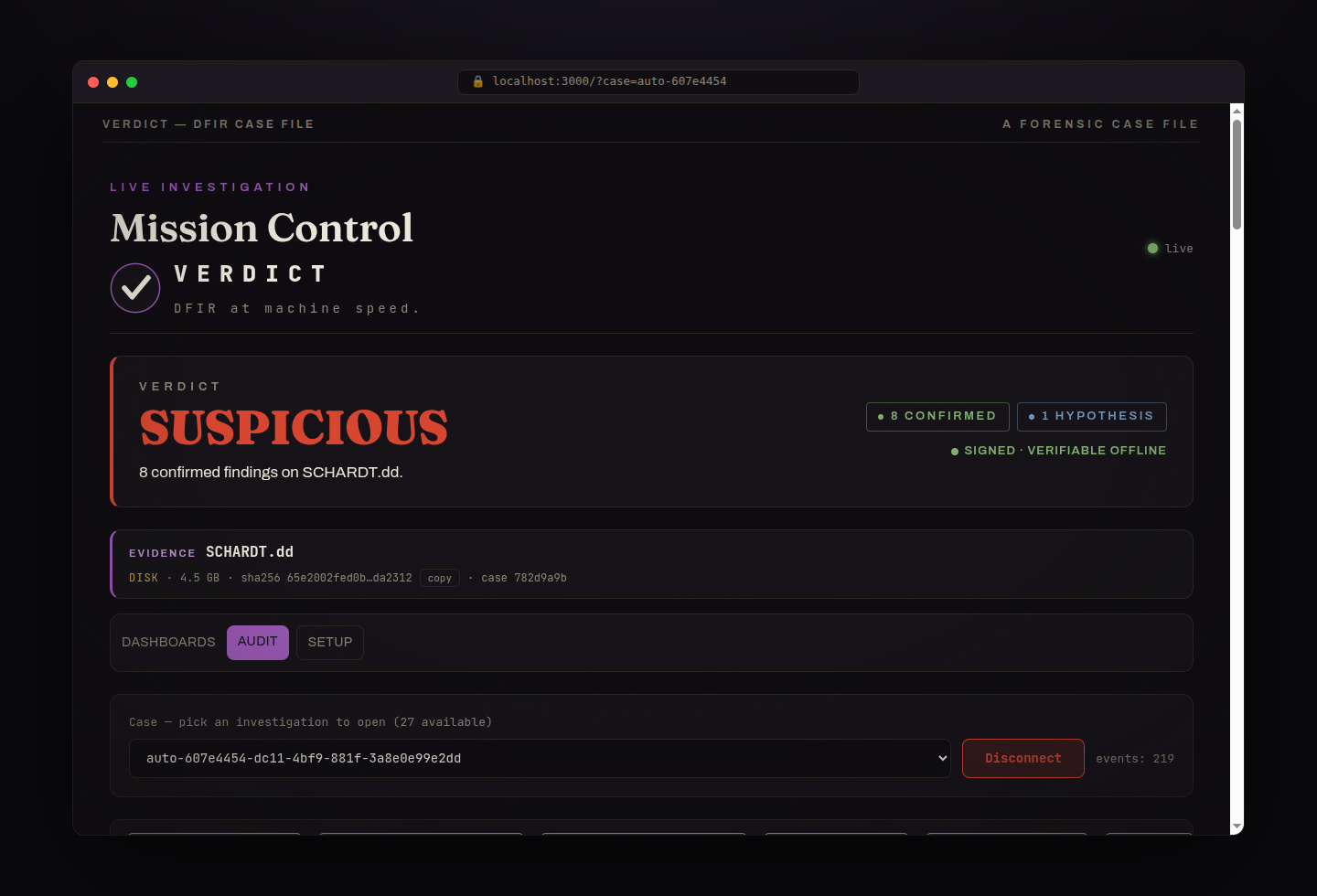
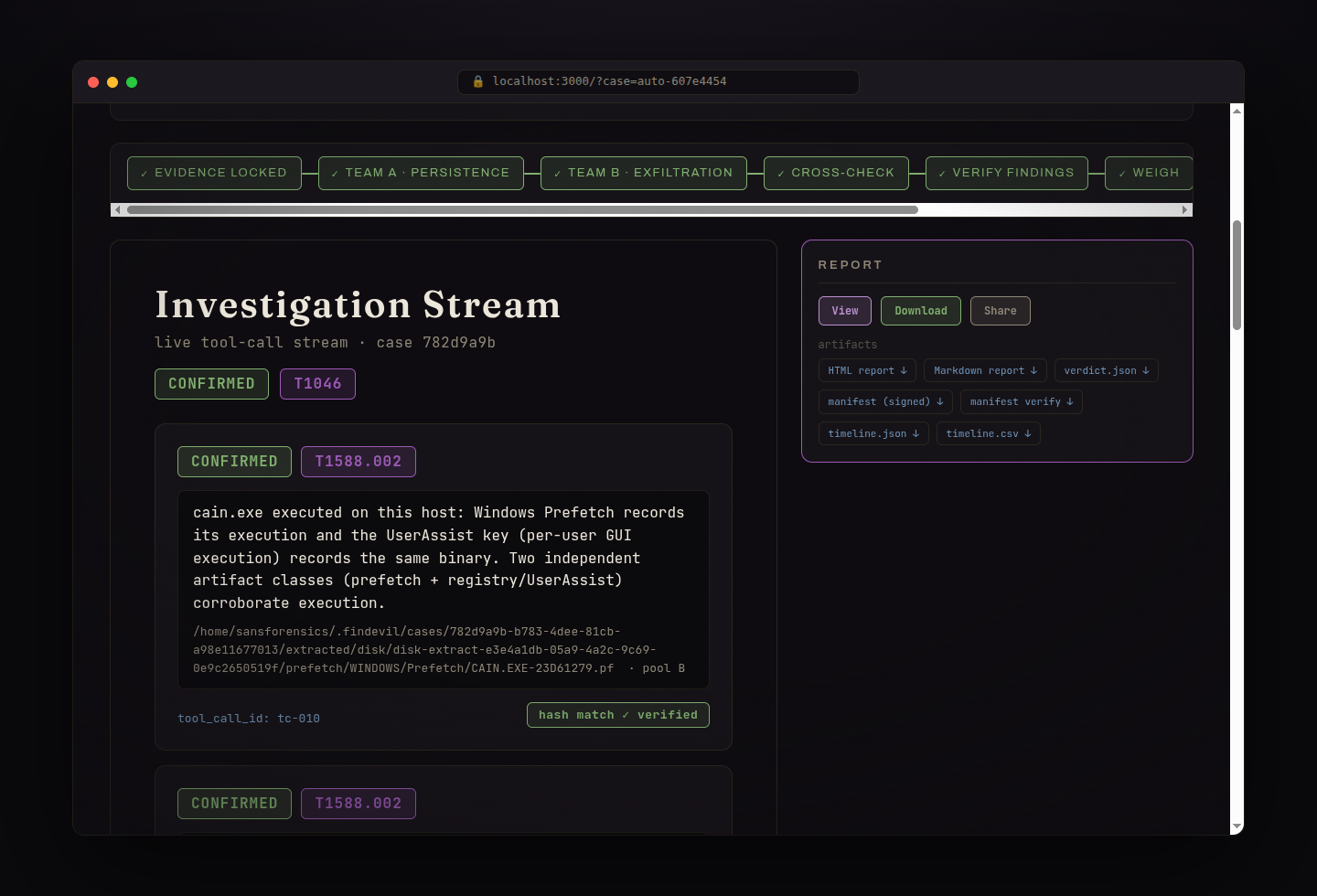
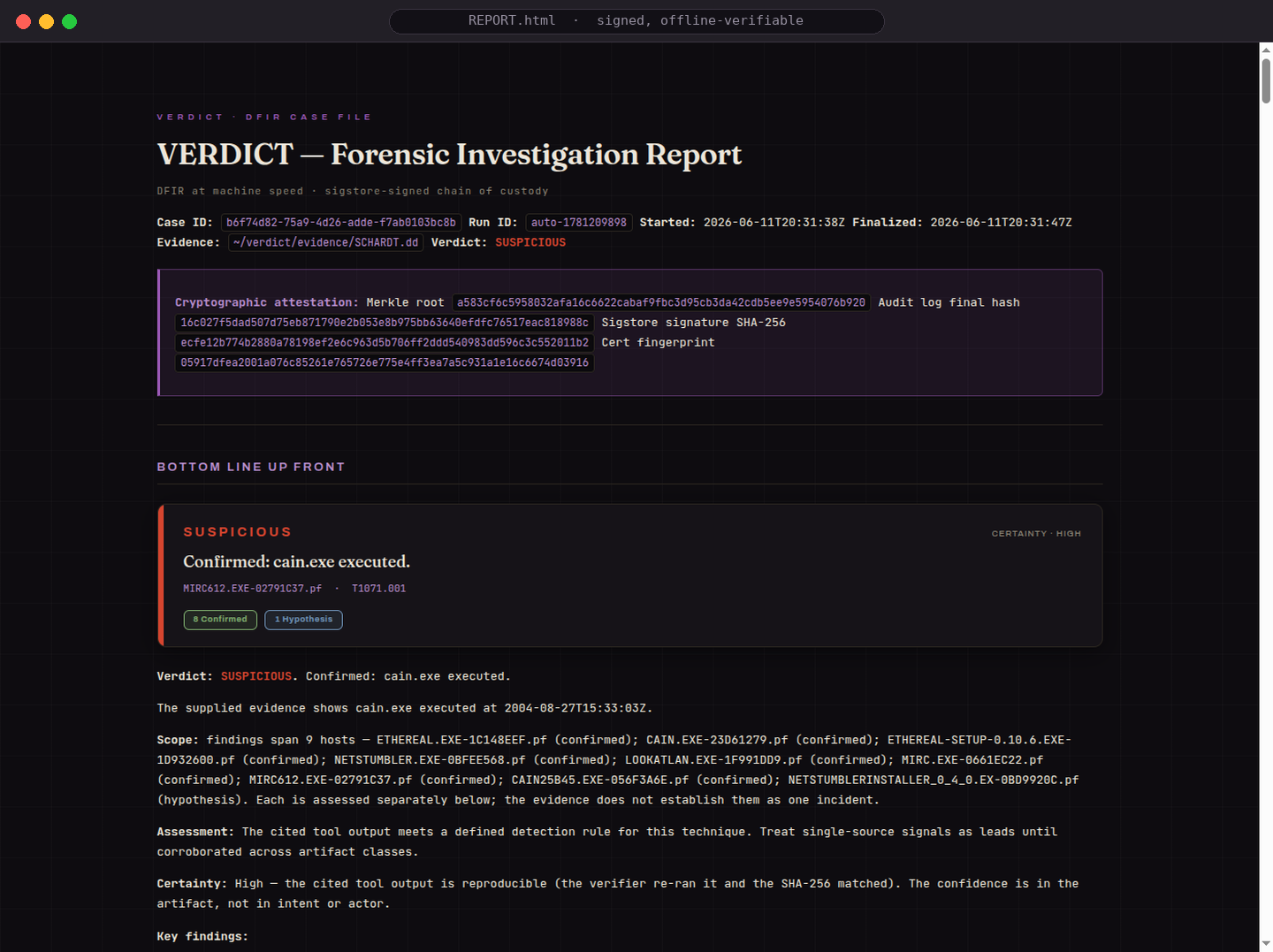
The NIST SCHARDT.dd case through SIFT: SUSPICIOUS with 8 confirmed tool executions (cain.exe, mIRC, Ethereal, NetStumbler), each tool-cited, in a signed report.
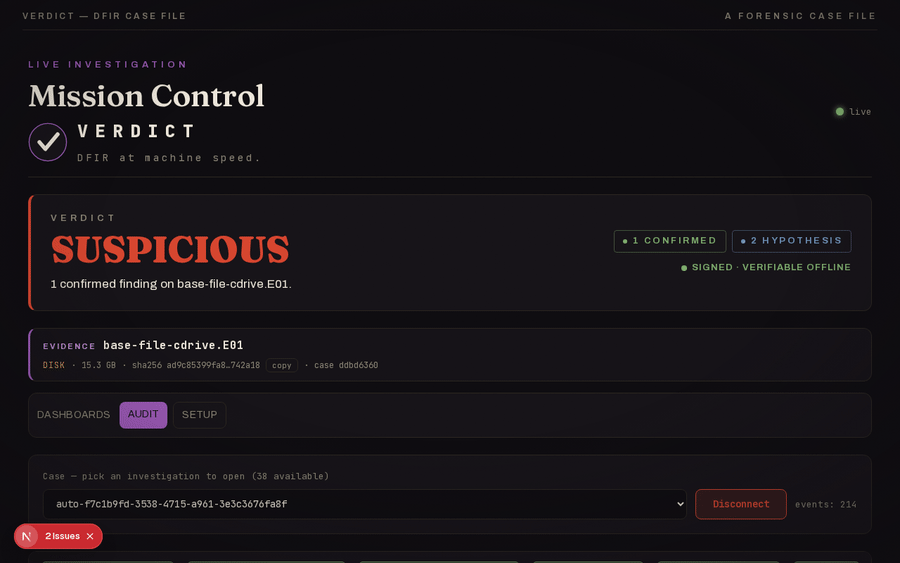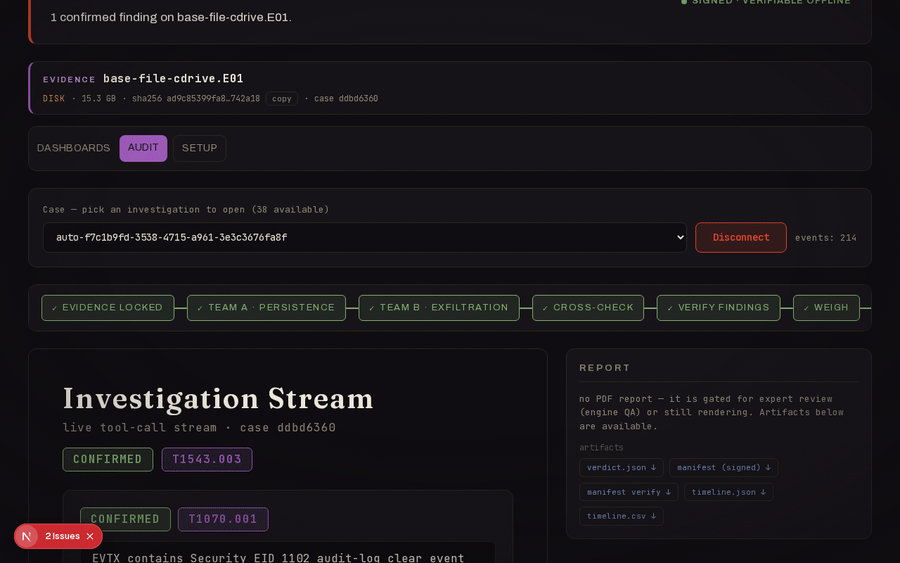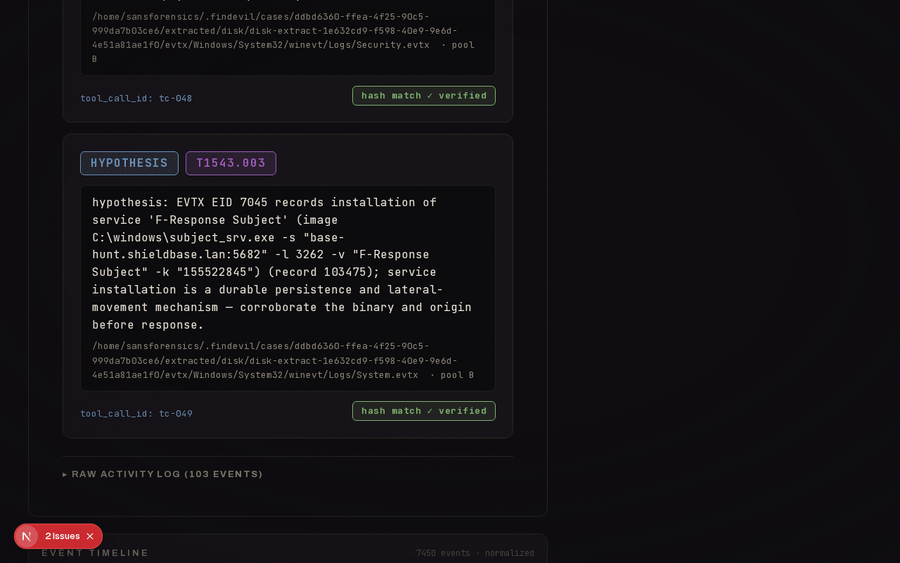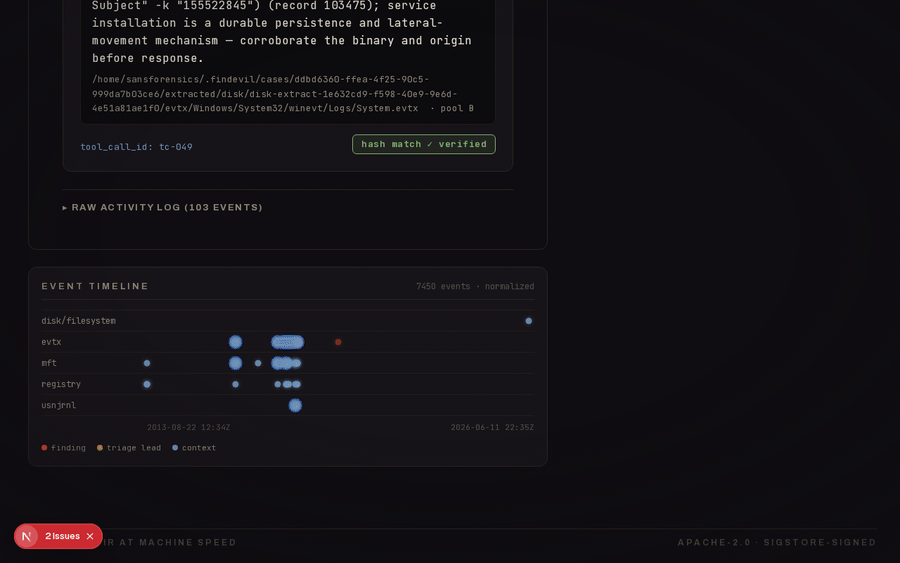
A 22-host compromised-enterprise case (SRL-2018, 198 GB) run host-by-host with the toolchain executing inside the SANS SIFT VM over SSH. Showcase walkthrough (4:35).
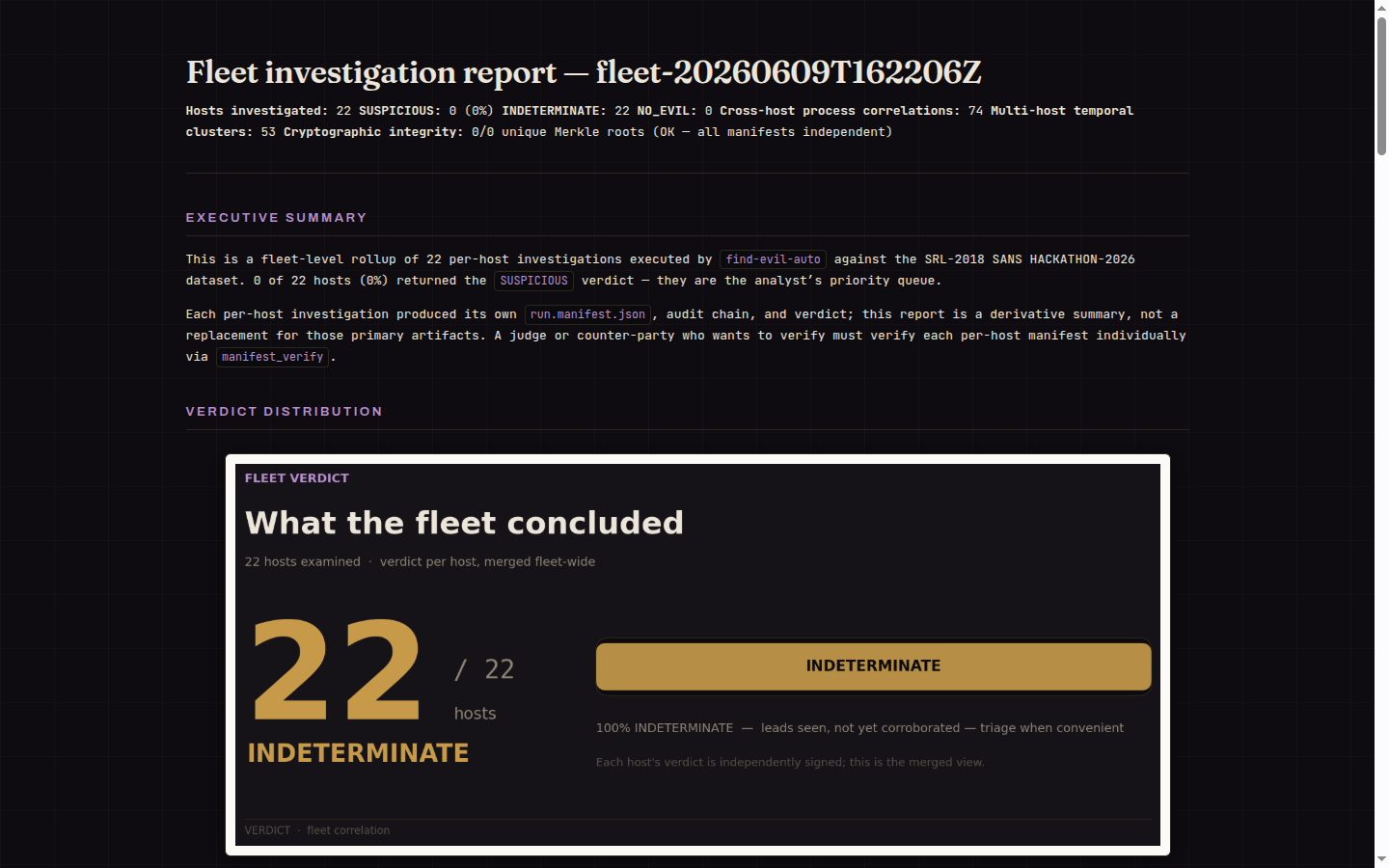
Cross-host fleet rollup, and the base-file server flagged SUSPICIOUS on a confirmed Security-log wipe (EID 1102), with PowerShell-LOLBin and service-install leads held at HYPOTHESIS.
How it works
Every Case runs the same nine-stage pipeline, each stage landing live on the dashboard as it completes:

- Evidence locked —
case_openSHA-256s the evidence and opens a read-only Case. - Persistence pool — the first analysis pool forks as a subagent and hunts persistence; every Finding cites the
tool_call_idthat produced it. - Exfiltration pool — a second pool works the same evidence in parallel with an exfil-biased prior, so competing hypotheses surface instead of hiding in consensus.
- Cross-check —
detect_contradictionsflags disagreeing Findings before anything merges. - Verify — the verifier re-runs each cited tool and compares output hashes; a Finding whose output drifted is rejected.
- Weigh —
judge_findingsmerges by claim with credibility weighting; execution claims need ≥2 artifact classes or stayHYPOTHESIS. - Correlate —
correlate_findingsstitches the survivors into one attack story. - Sign —
manifest_finalizeseals the run into a hash-chained, Merkle-rooted, signed manifest. - Report — the analyst report and the verdict.
Three design choices carry the weight:
- A typed MCP tool surface — no
execute_shell. 43 narrow, schema-validated product tools: 31
Rust DFIR tools (case_open,vol_pslist/psscan/psxview,mft_timeline,evtx_query,hayabusa_scan,yara_scan,registry_query,prefetch_parse,pcap_triage, and allow-listed
long-tail wrappers) plus 12 Python crypto/analysis tools. Copyleft and source-available engines
(Hayabusa, pandoc, tshark, Volatility 3, Velociraptor) are invoked as subprocesses only, keeping
the Apache-2.0 tree license-clean. - A cryptographic chain of custody. Hash-chained audit log → Merkle root over canonical-JSON
tool outputs (computed by the Python manifest builder, mirroringrs_merklesemantics) → a signed
manifest. The default signer is a local Ed25519 key that verifies offline; Sigstore/Rekor is the
identity and transparency-log tier.manifest_verifychecks the chain and root offline, and
customer-release candidates carry an expert-signoff packet. The custody model is framed for
FRE 902(14) self-authenticating evidence — seedocs/cryptographic-attestation.md. - Analysis of Competing Hypotheses as agent topology. Two pools investigate the same evidence
with opposing priors. Their disagreements are emitted as first-classkind=contradictionrecords
before a credibility-weighted judge merges them — surfaced, not hidden. Two pools do not prove
truth; the replayable tool-output chain does.
Findings follow a strict epistemic hierarchy — CONFIRMED (≥2 corroborating artifact classes,
verifier-passed) > INFERRED (derived from confirmed facts) > HYPOTHESIS — and execution
claims require at least two artifact classes.
Maturity note. The long-tail verbs (
vol_run,ez_parse,plaso_parse,mac_triage,cloud_audit,journalctl_query,login_accounting,ausearch,nfdump_query,suricata_eve,indx_parse) are typed, allow-listed, and unit-tested against fixtures, but not yet exercised on
real evidence in a committed run. Committed sample runs prove the core
disk/registry/EVTX/MFT/Prefetch/YARA/USN/Hayabusa/Sysmon/Zeek/PCAP,vol_*,vel_collect, andbrowser_historypaths.
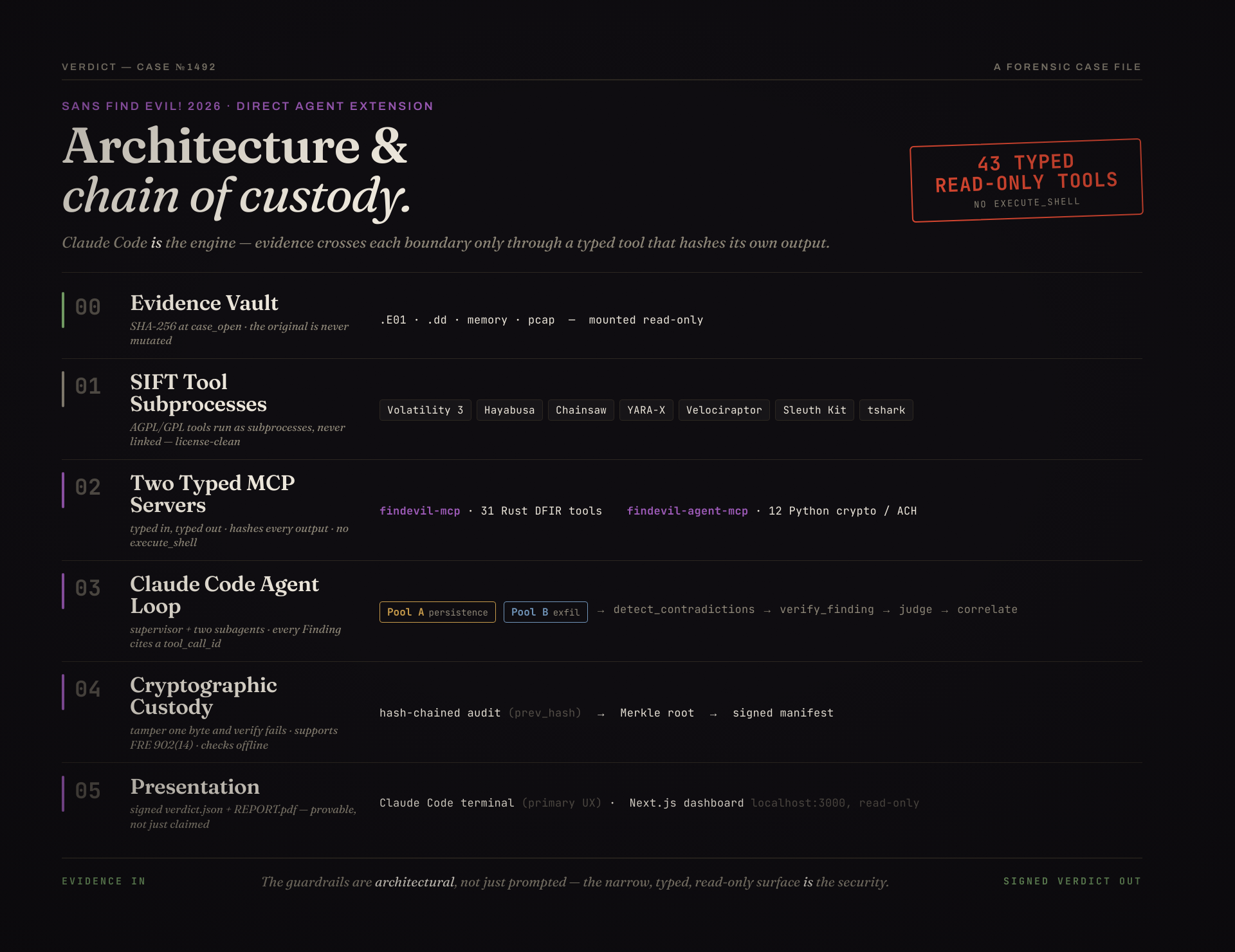
Architecture
The whole workflow as one picture — every boundary is crossed only through a typed, read-only tool
whose output is hash-chained into custody: the read-only evidence vault → SIFT tool
subprocesses → two typed MCP servers → the Claude Code agent loop → cryptographic
custody → the presentation layer, with trust boundaries marked.
The same pipeline mapped to the repository — entrypoints (scripts/), the agent loop governed byagent-config/, the .mcp.json surface (product servers findevil-mcp + findevil-agent-mcp =
43 audit-chained tools, plus the n8n / playwright / puppeteer / qmd convenience servers that never
emit findings), the SIFT DFIR tools, the read-only evidence vault, the custody chain
(audit.jsonl → manifest_finalize → manifest_verify), and the outputs:
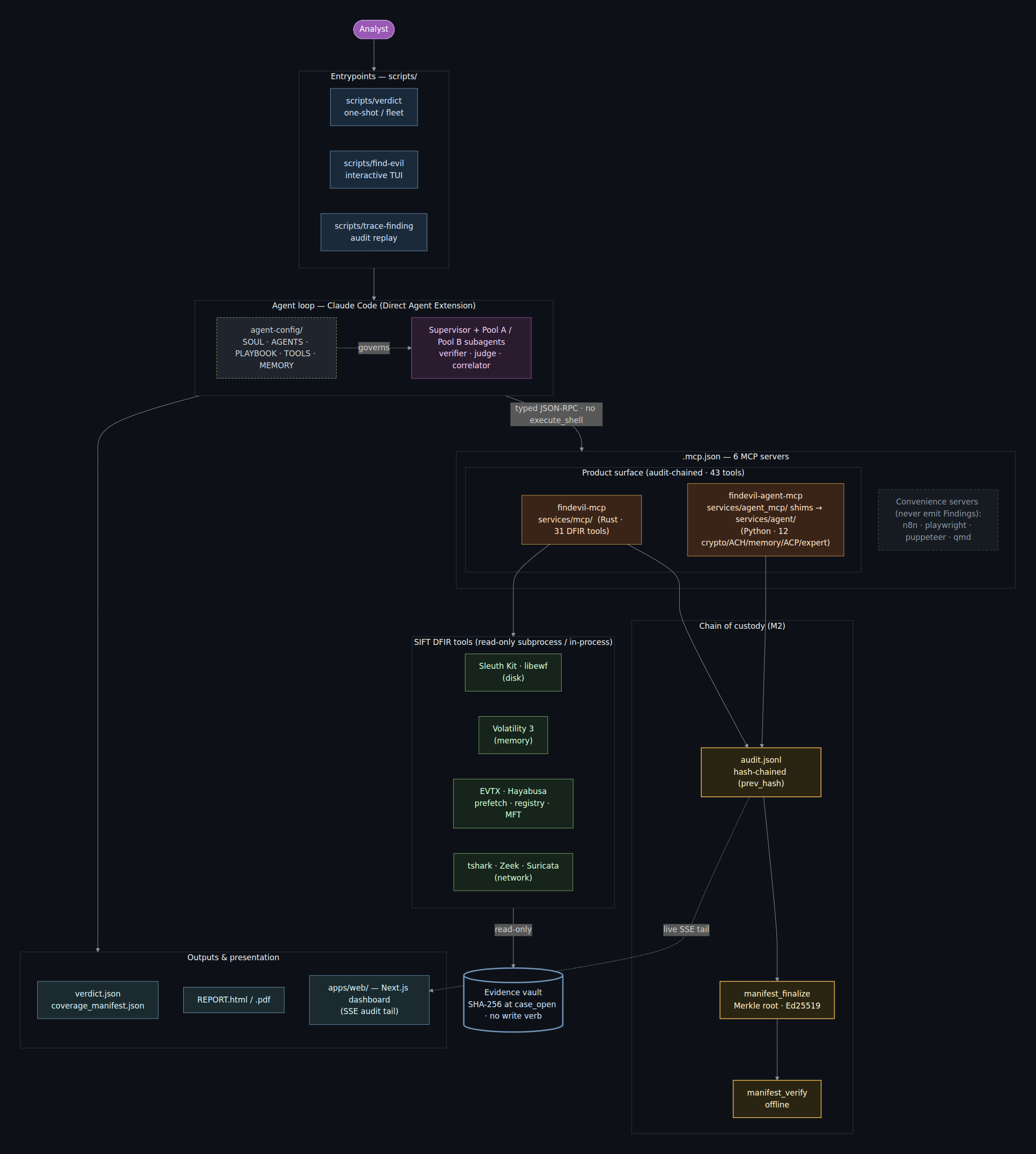
Trust-boundary detail and the agent topology are in docs/architecture.md.
Capabilities
- Disk and memory in one Case. With local Sleuth Kit/libewf support or in SIFT mode, it opens
raw/E01 images read-only and extracts$MFT, registry hives, EVTX, and Prefetch
(disk_mount/disk_extract_artifacts/disk_unmount), then analyzes memory in the same Case.
Raw disk with no supported mounted/extracted content stays custody-only and honestlyINDETERMINATE.
Supported disk images can be parsed locally through Sleuth Kit direct-read when prerequisites are present;case_openalone remains custody-only, and unsupported artifact classes stay as named limitations.
(tool inventory) - Self-verifying Findings.
verify_findingre-runs each cited tool call and confirms the output
SHA-256 still matches;detect_contradictionsraises pool conflicts as first-class records before
the judge merges — so a third party can independently replay the chain. (tools) - Fleet scale. Run a whole estate, not one box: the investigate → correlate → render pipeline
produces a single cross-hostFLEET_REPORTsurfacing signals that only appear across machines —
the same uncommon process on many hosts, near-simultaneous process-creation waves, MITRE-technique
spread. Runs in the SANS SIFT VM (fleet analysis) or per-host
locally with no VM (whole-case local run). - Optional post-verdict action. When the operator deploys an n8n workflow, a verdict can drive a
notification, ticket, or containment step. Out of the box no workflow is deployed, so the step
records as skipped. Either way it sits outside the audit chain — never evidence, never a Finding.
Accuracy and scope
If no parser or tool extracts an artifact class, VERDICT cannot reason over it — that is the trust
boundary, not a footnote. Every run writes a coverage_manifest.json sidecar (and embeds the same
object in verdict.json) with one row per artifact class. The strongest claim is not "the AI
reviewed the whole image"; it is that the cited artifacts were examined through replayable tools.
Disputed or unsupported leads stay visible as contradictions, HYPOTHESIS, oranalysis_limitations.
Accuracy is measured against published answer keys, not asserted. The repo ships small answer keys
under goldens/; large fixtures are staged with scripts/fetch-fixtures.sh, then scored withscripts/score-recall.py tmp/auto-runs/<case-id> --golden goldens/<case-id>. Method, corpus shape,
false-positive controls, and honest limits are in docs/accuracy-report.md;
the adversarial challenge is in docs/red-team-challenge.md.
Getting started
A single command installs the product prerequisites and verifies the environment:
bash scripts/setup
It installs the toolchain (Rust, uv, Node, pnpm) and the supported local DFIR binaries it can manage
(Volatility 3, Hayabusa, Chainsaw, Velociraptor, Sleuth Kit, tshark, pandoc — YARA is built into the
Rust binary), builds and verifies both MCP servers, runs the preflight doctor, and prints an honest
green/amber summary. Common variants:
bash scripts/setup --run # install, then watch evidence/ and investigate on drop
bash scripts/setup --with-sift # install local prerequisites and provision the SANS SIFT VM
bash scripts/setup --json # machine-readable status for scripts/CI

scripts/doctor.sh: one preflight, an honest green/amber summary, then you are ready to run.
The SANS SIFT VM is the reference forensic environment and provides the full workstation baseline
for disk-image parity; --with-sift fetches the gated 9.3 GB OVA headlessly and builds the VM,
falling back cleanly to local mode (memory, EVTX, PCAP, Velociraptor, and supported disk artifacts)
on any failure. Full prerequisites are in INSTALL.md; per-environment detail (local vs.
SIFT VM) is in QUICKSTART.md.
To run a Case, point verdict at a single image or a mixed case directory (memory + EVTX + disk +
network + Velociraptor):
scripts/verdict <path-to-evidence>
# --sift run the DFIR tools inside the SANS SIFT VM (default: local host)
# --watch watch evidence/ and investigate on the next drop
# --no-dashboard do not auto-open the browser
The dashboard at http://localhost:3000 streams the run live. Evidence files are never committed
(they are gitignored), so a fresh clone ships with none — stage public datasets withbash scripts/fetch-fixtures.sh (sources and SHA-256 in docs/DATASET.md) or drop
your own image into evidence/. Every run is a live test: confirm tmp/auto-runs/<case-id>/verdict.json
carries a real verdict and manifest_verify.json reports overall: true.
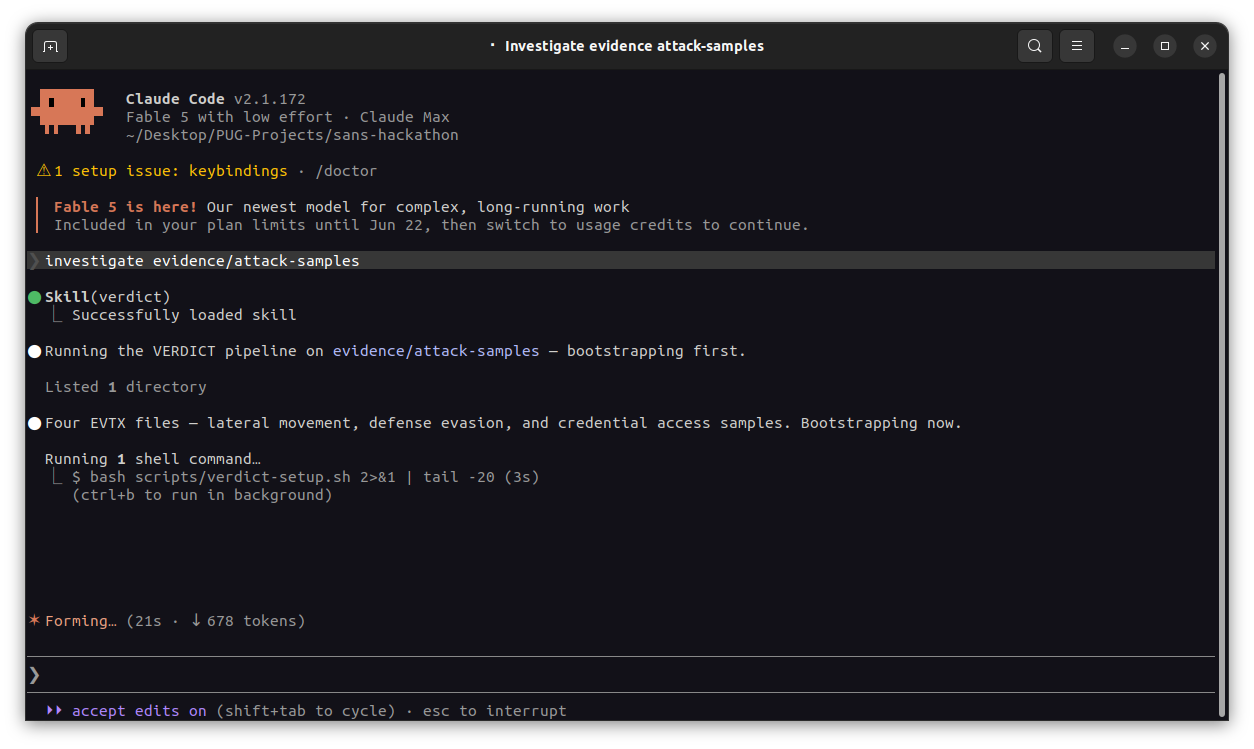
Agent mode: one prompt scopes the evidence (four EVTX samples — lateral movement, defense evasion, credential access) and bootstraps the pipeline.
Repository layout
.
├── agent-config/ — runtime agent identity (SOUL / AGENTS / PLAYBOOK / TOOLS / MEMORY)
├── services/mcp/ — Rust MCP server (31 typed DFIR tools)
├── services/agent_mcp/ — Python MCP server (12 crypto / ACH / memory tools)
├── services/agent/ — findevil_agent package (crypto chain + ACH primitives)
├── apps/web/ — Next.js dashboard (live audit-stream viewer + design system)
├── scripts/ — verdict launcher, report renderer, CI smoke runners
├── docs/ — reference/ (tools + deps + env), using/ (how to run), architecture, crypto attestation
└── .mcp.json — Claude Code auto-spawn registry: 6 MCP servers (2 product + 4 non-product helpers)
Documentation
- Published docs — GitHub Pages site
- docs/README.md — canonical documentation index
- docs/using/running-verdict.md — every flag, run mode, and output file
- docs/reference/mcp-and-tools.md — full MCP-server and tool inventory (dependencies)
- docs/architecture.md — trust boundaries and the agent topology
- docs/cryptographic-attestation.md — chain of custody and FRE 902(14)
- docs/verdict-semantics.md — what
SUSPICIOUS/INDETERMINATE/NO_EVILmean - docs/false-positives.md — how VERDICT avoids over-claiming
- docs/release-surface.md — release channel and public-source boundaries
For coding agents: read CLAUDE.md first — it encodes the document hierarchy, the
non-negotiable invariants, and the coding principles for this repo.
License
Apache-2.0. See LICENSE.
VERDICT was originally developed for the SANS Find Evil! 2026 challenge and is maintained as a
standalone DFIR tool. Internal identifiers (findevil-mcp, @findevil/web,scripts/find-evil) retain that name; the canonical operator command isscripts/verdict.
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi