id-agent
Health Pass
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 71 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
Token efficient IDs for AI agents. UUID alternative for the agentic era




id-agent
Token efficient IDs for AI agents.
AI agents pass IDs through prompts, tool calls, logs, traces, and memory. UUIDs are great for databases, but they are expensive in context windows and hard for humans or LLMs to copy reliably. id-agent gives you word-based IDs that are compact in modern tokenizers, readable in logs, and configurable by collision budget.
Where UUIDs cost about 23 tokens and get hallucinated by LLMs, id-agent produces memorable word-based IDs at about 14 tokens with strong collision resistance. It is built for the context window, not just the database.
- Human-readable -- word-based IDs that humans and LLMs can remember.
- Token-efficient -- every word in the wordlist is exactly 1 BPE token on o200k_base.
- Collision-safe -- configurable entropy from about 12 to 192 bits.
- Validated inputs -- descriptive validation on all public APIs.
The Math
Token Cost Comparison
| Format | Example | Tokens (o200k_base) | Collision Resistance |
|---|---|---|---|
| UUID v4 | 89b842d9-6df9-4cf4-8db0-9dc3aed3cfd7 |
about 23 | 122 bits |
| id-agent (default, 8 words) | urd-antes-sorry-pac-dire-total-expire-going |
about 14 | about 96 bits |
| id-agent (5 words) | frame-beer-bell-tog-hoot |
about 8 | about 60 bits |
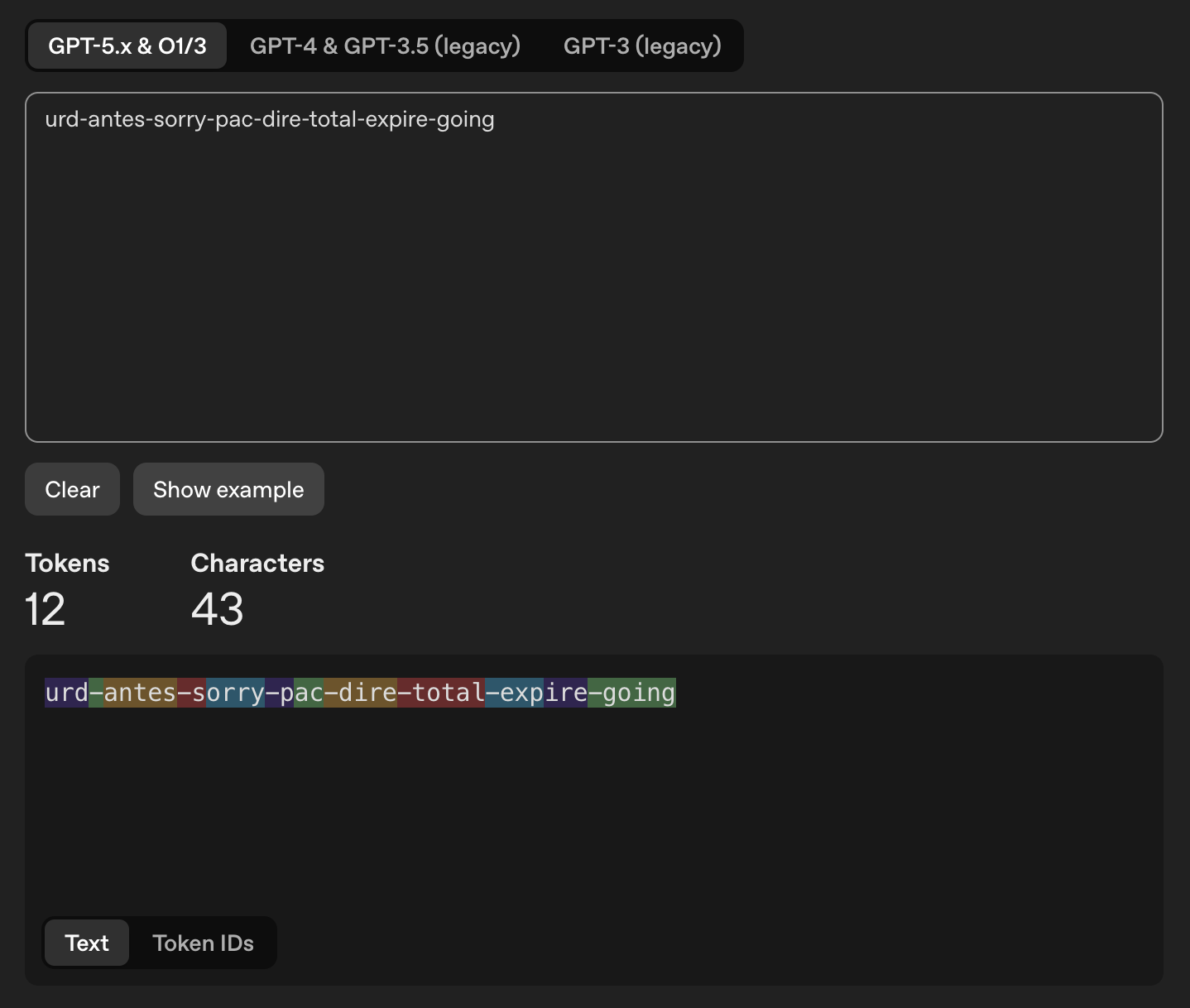 id-agent - 8 words, 43 chars, 12 tokens |
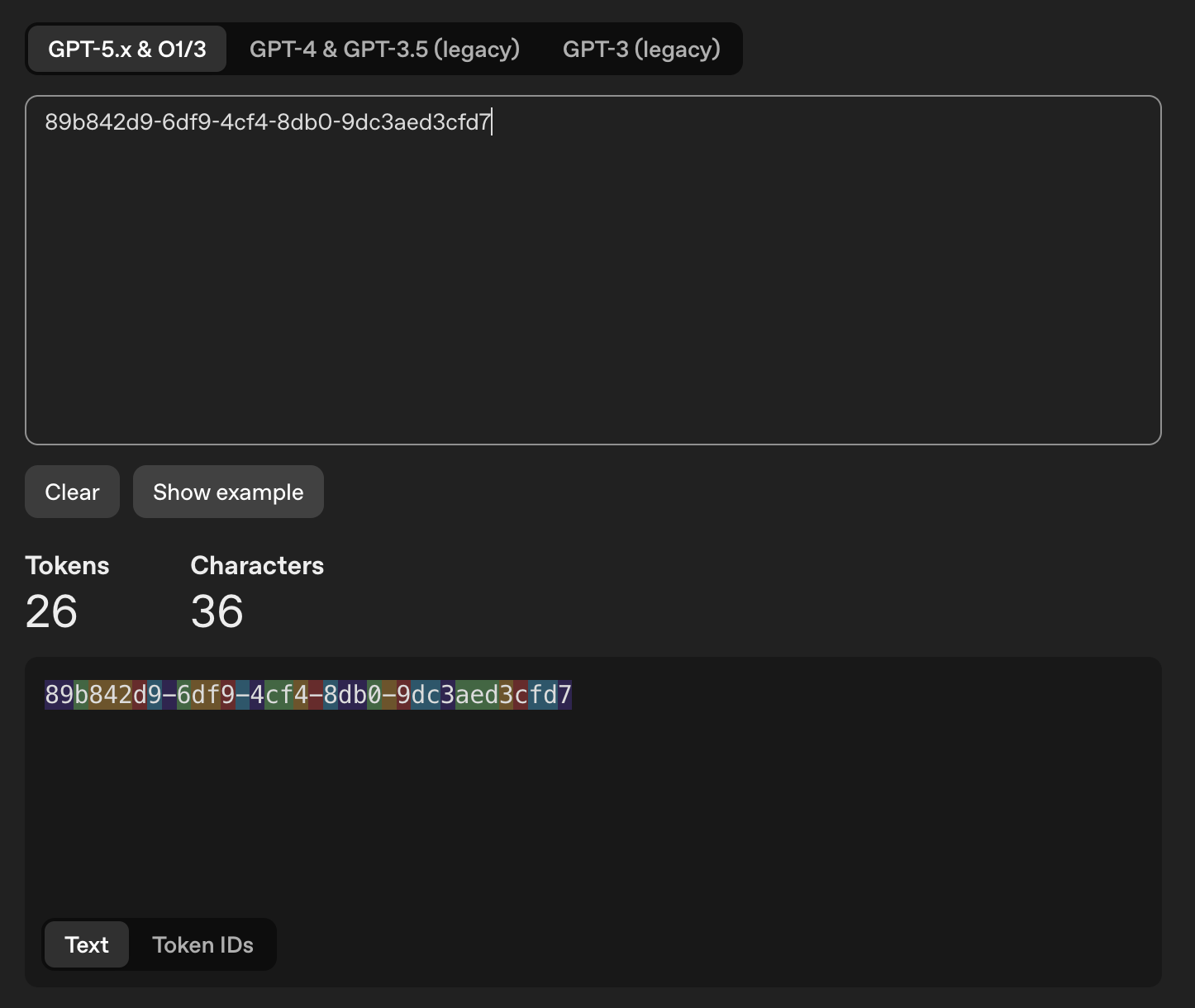 UUID v4 - 36 chars, 26 tokens |
Entropy
Each word is drawn uniformly from a curated 4096-word list (2^12). Every position in the ID is an independent random selection:
Entropy per word = log2(4096) = 12 bits
Total entropy = words * 12 bits
ID space = 4096^words = 2^(words * 12)
This holds regardless of individual word length. A 3-character word and a 6-character word both contribute exactly 12 bits because the attacker must guess from the same 4096-word pool.
Collision Probability
The probability of at least one collision among n randomly generated IDs:
P(collision) ~= n^2 / (2 * 2^b)
where b = total bits of entropy
This is the birthday paradox approximation, valid when P is small (P < 0.01).
| Words | Bits | ID Space | P @ 1K | P @ 10K | P @ 100K | P @ 1M | P @ 1B | 50% collision at |
|---|---|---|---|---|---|---|---|---|
| 3 | 36 | 6.9 * 10^10 | 7.3 * 10^-6 | 7.3 * 10^-4 | 7.3 * 10^-2 | about 1 | about 1 | about 309K items |
| 4 | 48 | 2.8 * 10^14 | 1.8 * 10^-9 | 1.8 * 10^-7 | 1.8 * 10^-5 | 1.8 * 10^-3 | about 1 | about 20M items |
| 5 | 60 | 1.2 * 10^18 | 4.3 * 10^-13 | 4.3 * 10^-11 | 4.3 * 10^-9 | 4.3 * 10^-7 | 0.43 | about 1.3B items |
| 8 | 96 | 7.9 * 10^28 | 6.3 * 10^-24 | 6.3 * 10^-22 | 6.3 * 10^-20 | 6.3 * 10^-18 | 6.3 * 10^-12 | about 331T items |
| 10 | 120 | 1.3 * 10^36 | 3.8 * 10^-31 | 3.8 * 10^-29 | 3.8 * 10^-27 | 3.8 * 10^-25 | 3.8 * 10^-19 | about 1.4 * 10^18 items |
| UUID v4 | 122 | 5.3 * 10^36 | 9.4 * 10^-32 | 9.4 * 10^-30 | 9.4 * 10^-28 | 9.4 * 10^-26 | 9.4 * 10^-20 | about 2.7 * 10^18 items |
The default 8-word ID is safe for more than 300 trillion items before reaching a 50% collision chance. Most applications will never generate more than a few million IDs.
Worked Example
For the default 8-word ID at 1 million items:
b = 8 * 12 = 96 bits
n = 1,000,000
P ~= (10^6)^2 / (2 * 2^96)
= 10^12 / (2 * 7.92 * 10^28)
= 10^12 / (1.58 * 10^29)
= 6.3 * 10^-18
That is roughly 1 in 158 quadrillion.
Token Cost
All measurements use o200k_base (GPT-4o, GPT-4.1, o1, o3) through tiktoken. Token counts vary slightly per ID because of BPE merge behavior with hyphens. Values below are averages over 100 samples:
| Format | Avg Tokens | Entropy | Tokens Saved vs UUID | Savings |
|---|---|---|---|---|
| UUID v4 | about 23 | 122 bits | -- | -- |
| id-agent (3 words) | about 5 | 36 bits | about 18 | 78% |
| id-agent (5 words) | about 8 | 60 bits | about 15 | 65% |
| id-agent (8 words, default) | about 14 | 96 bits | about 9 | 39% |
| id-agent (10 words) | about 17 | 120 bits | about 6 | 26% |
Choosing Word Count
The right word count depends on your scale. The default of 8 is deliberately conservative and globally safe.
| Scale | Recommended | Entropy | Why |
|---|---|---|---|
| Dev/testing | words: 3 |
36 bits | Fast, memorable, about 5 tokens. Collides at about 300K items. |
| Team tools | words: 4 |
48 bits | Safe to about 20M items. Good for internal APIs. |
| Production SaaS | words: 5 |
60 bits | Safe to about 1B items. 65% token savings vs UUID. |
| High-volume / distributed | words: 8 (default) |
96 bits | Safe to about 300T items. The safe default. |
| UUID-equivalent | words: 10 |
120 bits | Matches UUID v4 collision math. |
Why Words Beat Hex
BPE tokenizers used by modern LLMs were trained on natural language. Short English words are single tokens by design. UUIDs are hex strings that split unpredictably:
"storm-delta-stone" => 4 tokens (3 words + separators)
"dc193952-186a-4645" => 11 tokens (same 18 characters)
id-agent's wordlist is curated so every word is exactly 1 BPE token on o200k_base. The hyphens add about 1 token per 6 words due to BPE merge behavior. This is why word-based IDs are fundamentally more token-efficient than random hex or alphanumeric strings.
Implementations
id-agent is implemented as first-class packages for:
Both implementations use the same 4096-word list, separator rules, entropy model, prefix validation, and public behavior.
How It Works
id-agent uses a curated wordlist of 4096 English words, each verified as a single BPE token on the o200k_base tokenizer used by GPT-4o and GPT-4.1. Words are 3-6 characters and filtered for offensive terms and homophones.
Random IDs use cryptographically secure randomness. Deterministic IDs use HMAC-SHA256, mapping hash bytes to wordlist indices.
JavaScript / TypeScript
Install
npm install id-agent
pnpm add id-agent
Quick Start
import { idAgent } from 'id-agent'
const id = idAgent()
// => "urd-antes-sorry-pac-dire-total-expire-going"
const taskId = idAgent({ prefix: 'task' })
// => "task_slide-exact-cede-bury-linge-ease-bean-impact"
const short = idAgent({ words: 3 })
// => "front-reject-tho"
Random IDs
Generate a random, human-readable ID.
import { idAgent } from 'id-agent'
idAgent() // 8 words, about 96 bits
idAgent({ words: 5 }) // 5 words, about 60 bits
idAgent({ prefix: 'user' }) // "user_cloud-train-scope-frame-match-level-paint-field"
Options:
| Option | Type | Default | Description |
|---|---|---|---|
prefix |
string |
undefined |
Type prefix, lowercase alphanumeric only |
words |
number |
8 |
Number of words, 1-16. Controls entropy: words * 12 bits |
Deterministic IDs
Generate a deterministic ID from a string input using HMAC-SHA256. The same input always produces the same ID.
import { idAgent } from 'id-agent'
const id = await idAgent.from('[email protected]')
const namespaced = await idAgent.from('[email protected]', {
namespace: 'my-app',
prefix: 'user',
words: 5,
})
Options:
| Option | Type | Default | Description |
|---|---|---|---|
prefix |
string |
undefined |
Type prefix, lowercase alphanumeric only |
words |
number |
8 |
Number of words, 1-16 |
namespace |
string |
'id-agent' |
HMAC key for domain separation |
Parse
Parse any id-agent ID into its components. Supports hyphen-separated and underscore-separated words. Returns null for unrecognized formats.
import { parse } from 'id-agent'
parse('task_storm-delta-stone')
// => { prefix: 'task', words: ['storm', 'delta', 'stone'], wordCount: 3, bits: 36, raw: 'task_storm-delta-stone', format: 'readable' }
parse('task_storm_delta_stone')
// => { prefix: 'task', words: ['storm', 'delta', 'stone'], wordCount: 3, bits: 36, raw: 'task_storm_delta_stone', format: 'readable' }
Validate
Check if a string is a valid id-agent ID. Validation confirms that all words exist in the WORDLIST.
import { validate } from 'id-agent'
validate('storm-delta-stone')
// => { valid: true, prefix: undefined, wordCount: 3 }
validate('task_jump-notaword')
// => { valid: false, reason: 'unknown words: notaword' }
validate('INVALID')
// => { valid: false, reason: 'contains uppercase characters' }
Alias Maps
Create a bidirectional alias map for token reduction in LLM contexts. Maps long IDs to short word-based aliases with replace and restore support.
import { createAliasMap } from 'id-agent'
const aliases = createAliasMap({ words: 3 })
aliases.set('8cdda07b-85d2-459c-8a2a-83c8f9245dbe')
// => "storm-delta-stone"
aliases.get('storm-delta-stone')
// => "8cdda07b-85d2-459c-8a2a-83c8f9245dbe"
const text = 'Process 8cdda07b-85d2-459c-8a2a-83c8f9245dbe then 6ba7b810-9dad-11d1-80b4-00c04fd430c8'
const shortened = aliases.replace(text, {
pattern: /[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}/gi,
})
// => "Process storm-delta-stone then cloud-train-scope"
const restored = aliases.restore(shortened)
// => original text
aliases.entries()
// => [["8cdda07b-85d2-459c-8a2a-83c8f9245dbe", "storm-delta-stone"], ...]
Options:
| Option | Type | Required | Description |
|---|---|---|---|
words |
number |
Yes | Number of words per alias, 1-16 |
Duplicate Detection
Scan text for duplicate IDs using a regex pattern. This is a pure function with no filesystem access.
import { detectDuplicates } from 'id-agent'
const dupes = detectDuplicates({
pattern: /[a-z]+(?:-[a-z]+)+/,
text: 'Found storm-delta-stone in file A and storm-delta-stone in file B',
})
// => [{ id: 'storm-delta-stone', count: 2 }]
const dupes2 = detectDuplicates({
pattern: /task_[a-z]+(?:-[a-z]+)+/,
text: ['const x = "task_red-fox-run"', 'const y = "task_red-fox-run"'],
})
Options:
| Option | Type | Description |
|---|---|---|
pattern |
RegExp |
Regex to match IDs in text |
text |
string | string[] |
Text to scan for duplicates |
WORDLIST
Direct access to the curated 4096-word list. Every word is exactly 1 BPE token on o200k_base. The JavaScript export is a frozen array.
import { WORDLIST } from 'id-agent'
WORDLIST.length // => 4096
Object.isFrozen(WORDLIST) // => true
Python
Install
pip install id-agent
uv add id-agent
Quick Start
from id_agent import generate
id = generate()
# => "urd-antes-sorry-pac-dire-total-expire-going"
task_id = generate(prefix="task")
# => "task_slide-exact-cede-bury-linge-ease-bean-impact"
short = generate(words=3)
# => "front-reject-tho"
Random IDs
Generate a random, human-readable ID.
from id_agent import generate
generate() # 8 words, about 96 bits
generate(words=5) # 5 words, about 60 bits
generate(prefix="user") # "user_cloud-train-scope-frame-match-level-paint-field"
Options:
| Option | Type | Default | Description |
|---|---|---|---|
prefix |
str | None |
None |
Type prefix, lowercase alphanumeric only |
words |
int |
8 |
Number of words, 1-16. Controls entropy: words * 12 bits |
Deterministic IDs
Generate a deterministic ID from a string input using HMAC-SHA256. The same input always produces the same ID.
from id_agent import generate_deterministic
id = generate_deterministic("[email protected]")
namespaced = generate_deterministic(
"[email protected]",
namespace="my-app",
prefix="user",
words=5,
)
Options:
| Option | Type | Default | Description |
|---|---|---|---|
prefix |
str | None |
None |
Type prefix, lowercase alphanumeric only |
words |
int |
8 |
Number of words, 1-16 |
namespace |
str |
"id-agent" |
HMAC key for domain separation |
Parse
Parse any id-agent ID into its components. Supports hyphen-separated and underscore-separated words. Returns None for unrecognized formats.
from id_agent import parse
parse("task_storm-delta-stone")
# => ParsedId(prefix="task", words=("storm", "delta", "stone"), word_count=3, bits=36.0, raw="task_storm-delta-stone", format="readable")
parse("task_storm_delta_stone")
# => ParsedId(prefix="task", words=("storm", "delta", "stone"), word_count=3, bits=36.0, raw="task_storm_delta_stone", format="readable")
Validate
Check if a string is a valid id-agent ID. Validation confirms that all words exist in the WORDLIST.
from id_agent import validate
validate("storm-delta-stone")
# => ValidationResult(valid=True, prefix=None, word_count=3, words=("storm", "delta", "stone"))
validate("task_jump-notaword")
# => ValidationResult(valid=False, reason="unknown words: notaword", unknown_words=("notaword",))
validate("INVALID")
# => ValidationResult(valid=False, reason="contains uppercase characters")
Alias Maps
Create a bidirectional alias map for token reduction in LLM contexts. Maps long IDs to short word-based aliases with replace and restore support.
from id_agent import AliasMap
aliases = AliasMap(words=3)
aliases.set("8cdda07b-85d2-459c-8a2a-83c8f9245dbe")
# => "storm-delta-stone"
aliases.get("storm-delta-stone")
# => "8cdda07b-85d2-459c-8a2a-83c8f9245dbe"
text = "Process 8cdda07b-85d2-459c-8a2a-83c8f9245dbe then 6ba7b810-9dad-11d1-80b4-00c04fd430c8"
shortened = aliases.replace(
text,
pattern=r"[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}",
)
# => "Process storm-delta-stone then cloud-train-scope"
restored = aliases.restore(shortened)
# => original text
aliases.entries()
# => (("8cdda07b-85d2-459c-8a2a-83c8f9245dbe", "storm-delta-stone"), ...)
Options:
| Option | Type | Required | Description |
|---|---|---|---|
words |
int |
Yes | Number of words per alias, 1-16 |
Duplicate Detection
Scan text for duplicate IDs using a regex pattern. This is a pure function with no filesystem access.
from id_agent import detect_duplicates
dupes = detect_duplicates(
pattern=r"[a-z]+(?:-[a-z]+)+",
text="Found storm-delta-stone in file A and storm-delta-stone in file B",
)
# => [DuplicateResult(id="storm-delta-stone", count=2)]
dupes2 = detect_duplicates(
pattern=r"task_[a-z]+(?:-[a-z]+)+",
text=['const x = "task_red-fox-run"', 'const y = "task_red-fox-run"'],
)
Options:
| Option | Type | Description |
|---|---|---|
pattern |
str | re.Pattern[str] |
Regex to match IDs in text |
text |
str | Iterable[str] |
Text to scan for duplicates |
WORDLIST
Direct access to the curated 4096-word list. Every word is exactly 1 BPE token on o200k_base. The Python export is an immutable tuple.
from id_agent import WORDLIST
len(WORDLIST) # => 4096
isinstance(WORDLIST, tuple) # => True
License
MIT
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found