awesome-autoresearch
Health Gecti
- License — License: CC0-1.0
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 684 GitHub stars
Code Uyari
- Code scan incomplete — No supported source files were scanned during light audit
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
Curated list of AutoResearch use cases with optimization traces and open source implementations
Awesome AutoResearch 
A curated list of AutoResearch use cases with optimization traces and open source implementations. Every entry includes a link to the actual optimization trajectory so you can see what the agent tried, not just the final result.
What is AutoResearch?
AutoResearch is, at its core, a prompt. Karpathy released it as a single markdown file - program.md, that instructs a coding agent (Claude Code, Codex, or similar) to follow an optimization workflow. The agent edits one file (train.py, that trains a language model), runs for a fixed 5 minutes on a GPU, checks whether the metric improved, and either commits the change or reverts it. Then it loops forever.
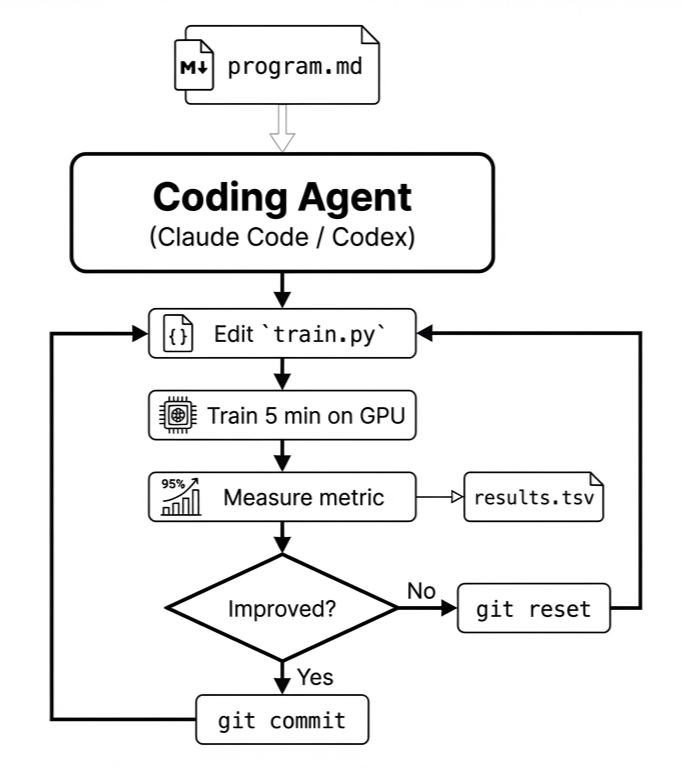
The specific program.md that ships with AutoResearch is written for one task: training a GPT model. But the structure - iteratively optimizing a file against an evaluation metric, with a discard/keep loop - turns out to be portable. In the weeks since release, the community has adapted it to GPU kernel optimization, template engine optimization, tabular ML engineering, and more. The program.md for each of these looks different, but the loop is the same.
Use Cases
| Use Case | Description | Author | Links | Traces |
|---|---|---|---|---|
| LLM training optimization | The original - optimize nanoGPT training code. 20 improvements found overnight on hand-tuned code | Andrej Karpathy | GitHub · Tweet | progress chart |
| Speed up Shopify's template engine | 53% faster parse+render, 61% fewer allocations from 93 automated commits on Shopify's Liquid engine | Tobi Lutke (Shopify CEO) | GitHub · Tweet | PR |
| GPU kernel optimization | Autoresearch applied to CUDA kernel optimization (18 → 187 TFLOPS) | RightNow AI | GitHub · Tweet | progress chart |
| Voice agent prompt engineering | Optimize voice agent prompts with automated evaluation (score 0.728 → 0.969) | Archie Sengupta | GitHub · Tweet | progress chart |
| Predict baseball pitch speed | Build predictive model for pitch velocity from biomechanics data (R² 0.44 → 0.78) | Kyle Boddy (Driveline Baseball) | Tweet | progress chart |
| XGBoost for tennis match prediction | Predict ATP/WTA match outcomes - encountered and documented reward hacking | Nick Oak | Blog · GitHub | blog |
| RL post-training optimization | Autoresearch for RL hyperparameters on Qwen 0.5B + GSM8K (eval 0.475 → 0.550 in fewer steps) | Vivek Kashyap | GitHub · Tweet | progress chart |
| Ancient scroll ink detection | Vesuvius Challenge autoresearch agent swarm for ink detection models. 4 agents 24/7, cross-scroll generalization nearly doubled | Vesuvius Challenge | Blog | blog |
| Earth system model optimization | Hybrid: LLM proposes formula structures, TPE optimizes parameters. Fire correlation 0.09→0.65 | Dev Paragiri (UMD CS) | Tweet · Blog | blog |
| Bitcoin price formula discovery | Autonomous search for best time-based formula predicting Bitcoin price. 328 experiments, 50.5% RMSE improvement over power law. Walk-forward OOS evaluation with bootstrap significance testing | Carlos Baquero | GitHub | progress chart |
Implementations & Forks
| Project | Description | Links |
|---|---|---|
| autoresearch | The original - single GPU, 630 lines of Python | GitHub |
| pi-autoresearch | Generalized as a Pi extension. Works for any optimization target - test speed, bundle size, build times, Lighthouse scores | GitHub |
| autoresearch-mlx | Apple Silicon (MLX) port. No PyTorch required, uses unified memory | GitHub |
| autoresearch-win-rtx | Windows + consumer RTX GPU port (RTX 2060 through 4090) | GitHub |
| autoresearch-at-home | Distributed autoresearch - SETI@home style. Multi-agent swarm coordination | GitHub |
| autoresearch (Claude Skill) | Generalized as a Claude Code skill for any domain | GitHub |
| agent-digivolve-harness | A control layer for long-running CLI agent work. Generalizes the autoresearch keep/revert loop with persistent run state, explicit eval packages, baseline and holdout cases, and one bounded mutation per iteration | GitHub |
| auto-agent | Autoresearch, but for AI agents. Given a golden dataset, it autonomously improves a target agent through an iterative hypothesis-driven loop: analyze failures, spawn a coding agent to implement fixes, evaluate, and accept or rollback | GitHub |
Contributing
Want to add a use case? Open a PR or file an issue.
To make our work easier, please make submissions as verifiable as possible:
- Minimum: a progress chart showing each experiment's score and breakthrough annotations (e.g. Karpathy's progress chart)
- Ideal: a public repo with per-solution code and scores (the full exploration trace), or a Weco Observe dashboard link
License
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi