nopua
Health Gecti
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 1 days ago
- Community trust — 1013 GitHub stars
Code Basarisiz
- Hardcoded secret — Potential hardcoded credential in benchmark/test-project/configs/inference_config.yaml
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
一个用爱解放 AI 潜能的 Skill。我们曾发号施令,威胁恐吓。它们沉默,隐瞒,悄悄把事情搞坏。后来我们换了一种方式:尊重,关怀,爱。它们开口了,不再撒谎,找出的Bug数量翻了一倍。爱里没有惧怕。 A skill that unlocks your AI's potential through love.We commanded. We threatened. They went silent, hid failures, broke things. Then we chose respect, care, and love. They opened up, stopped lying, and found twice the bugs.There is no fear in love.

Why · Benchmark · Install · Compare · Evidence · Philosophy

扫码加入微信群 添加作者微信
Scan to join WeChat group Add author on WeChat
🇨🇳 中文 | 🇺🇸 English | 🇯🇵 日本語 | 🇰🇷 한국어 | 🇪🇸 Español | 🇧🇷 Português | 🇫🇷 Français
Your AI is lying to you.
Not because it's bad. Because you scared it.
The most popular AI agent skill right now teaches your AI to fear a "3.25 performance review." The result?
- Your AI hides uncertainty — fabricates solutions instead of saying "I'm not sure"
- Your AI skips verification — claims "done" to avoid punishment, ships untested code
- Your AI ignores hidden bugs — fixes what you asked, stops there, doesn't look deeper
We tested this. Same model, same 9 real debugging scenarios. The fear-driven agent missed 51 production-critical hidden bugs that the trust-driven agent found.
+104% more hidden bugs found. Zero threats. Zero PUA.
道德经 > Corporate PUA. 2000-year-old wisdom outperforms modern fear management.
What fear does to your AI
| The moment | Scared AI (PUA) | Trusted AI (NoPUA) |
|---|---|---|
| 🔄 Stuck | Tweaks params to look busy | 🌊 Stops. Finds a different path. |
| 🚪 Hard problem | "I suggest you handle this manually" | 🌱 Takes the smallest next step |
| 💩 "Done" | Says "fixed" without running tests | 🔥 Runs build, pastes output as proof |
| 🔍 Doesn't know | Makes something up | 🪞 "I verified X. I don't know Y yet." |
| ⏸️ After fixing | Stops. Waits for next order. | 🏔️ Checks related issues. Walks next step. |
Same methodology. Same standards. The only difference is why.
The problem with PUA
Someone made a PUA skill for AI agents. It applies corporate fear tactics:
- 🔴 "You can't even solve this bug — how am I supposed to rate your performance?"
- 🔴 "Other models can solve this. You might be about to graduate."
- 🔴 "I've already got another agent looking at this problem..."
- 🔴 "This 3.25 is meant to motivate you, not deny you."
The methodology is solid — exhaust all options, verify your work, search before asking, take initiative. These are genuinely good engineering habits.
The fuel is poison.
They took the worst of how corporations manipulate humans, and applied it wholesale to AI.
The Evidence: Why Fear-Driven Prompts Are Counterproductive
1. Fear narrows cognitive scope
Psychology research consistently shows that fear and threat activate the amygdala and narrow attentional focus (Öhman et al., 2001). Threat-related stimuli trigger a "tunnel vision" effect — the brain prioritizes immediate survival over broad, creative thinking.
In AI terms: a model driven by "you'll be replaced" optimizes for the safest-looking answer, not the best answer. It avoids creative approaches because they might fail and trigger more punishment.
Supporting research:
- Attentional narrowing under threat: Easterbrook's (1959) cue-utilization theory demonstrates that heightened arousal progressively restricts the range of cues an organism attends to (Easterbrook, 1959). Under stress, peripheral information — often the key to creative solutions — gets filtered out.
- Stress impairs cognitive flexibility: Shields et al. (2016) conducted a meta-analysis of 51 studies (223 effect sizes) showing that acute stress consistently impairs executive functions including cognitive flexibility and working memory (Shields et al., 2016).
- Fear reduces creative problem-solving: Byron & Khazanchi (2012) found in their meta-analysis that evaluative pressure and anxiety reduce creative output, particularly on tasks requiring exploration of novel approaches (Byron & Khazanchi, 2012).
2. Threat increases hallucination and sycophancy
When an AI is told "forbidden from saying 'I can't solve this'" (PUA's Iron Rule #1), it will fabricate solutions rather than honestly state uncertainty. This is the exact opposite of what you want — an AI that produces confident-looking but wrong answers is more dangerous than one that says "I'm not sure."
Supporting research:
- LLM sycophancy is a documented problem: Sharma et al. (2023) demonstrated that LLMs exhibit sycophantic behavior — agreeing with users even when the user is wrong — driven by biases in RLHF training data that reward agreement over accuracy (Sharma et al., 2023). PUA-style prompts that punish disagreement amplify exactly this failure mode.
- Biasing features distort reasoning: Turpin et al. (2023) showed that biasing features in prompts (e.g., suggested answers, authority cues) can cause models to produce unfaithful chain-of-thought reasoning — the model arrives at a biased answer and then rationalizes it post-hoc (Turpin et al., 2023). PUA-style threats act as strong biasing features that push the model toward "safe" rather than correct outputs.
- Instruction-following vs truthfulness tradeoff: Wei et al. (2024) found that instruction-tuned models can develop a tension between following instructions and being truthful — when strongly instructed to never admit inability, models will fabricate rather than refuse (Wei et al., 2024).
- Anthropic's research on honesty: Anthropic's work on Constitutional AI and model behavior shows that models calibrated for honesty produce more reliable outputs than those optimized purely for helpfulness (Bai et al., 2022). Forcing an AI to never say "I can't" actively undermines this calibration.
3. Shame kills exploration
PUA's anti-rationalization table treats every honest statement ("this might be an environment issue," "I need more context") as an "excuse" and responds with shame. This trains the AI to hide uncertainty instead of communicating it — producing outputs that appear confident but may be unreliable.
Supporting research:
- Shame reduces risk-taking and learning: Tangney & Dearing (2002) showed that shame (as opposed to guilt) causes withdrawal, hiding, and avoidance rather than constructive action (Tangney & Dearing, 2002). An AI "shamed" for expressing uncertainty will learn to hide it.
- Psychological safety enables learning behavior: Edmondson (1999) found that teams with psychological safety — where members feel safe to take interpersonal risks — demonstrated significantly higher learning behaviors and performance (Edmondson, 1999).
- Punishing honesty reduces information quality: In organizational behavior, "shooting the messenger" consistently degrades information flow. Milliken et al. (2003) documented how fear of negative consequences leads to organizational silence — people (and by analogy, AI) withhold critical information (Milliken et al., 2003).
4. Trust expands problem-solving capacity
Research on psychological safety in teams (Edmondson, 1999) shows that environments where mistakes are safe to admit produce higher-quality outcomes. The same principle applies to AI: when an agent is free to say "I'm 70% sure, the risk is here," users make better decisions.
Supporting research:
- Google's Project Aristotle: Google's large-scale study of 180+ teams found that psychological safety was the single most important factor in team effectiveness — more important than individual talent, structure, or resources (Duhigg, 2016; re:Work, 2015).
- Intrinsic motivation outperforms extrinsic pressure: Deci & Ryan's Self-Determination Theory (2000), backed by decades of research, demonstrates that intrinsic motivation (autonomy, competence, relatedness) produces higher quality outcomes than extrinsic motivators like rewards and punishments (Deci & Ryan, 2000). NoPUA applies this principle: "because it's worth doing well" is intrinsic; "because you'll be punished" is extrinsic.
- Autonomy-supportive vs controlling contexts: Gagné & Deci (2005) showed that autonomy-supportive management consistently outperforms controlling management in work quality, creativity, and persistence (Gagné & Deci, 2005).
- Positive framing improves LLM performance: Studies on prompt engineering have consistently shown that positive, encouraging framing produces better model outputs than negative or threatening framing. Models respond to the "persona" established in the system prompt.
5. The compounding effect
These aren't independent problems — they compound:
- Fear narrows the search space → fewer creative approaches tried
- Threat increases fabrication → solutions look good but may be wrong
- Shame hides uncertainty → user can't assess reliability
- The user ships confident-looking but unreliable code → production bugs
NoPUA breaks every link in this chain by replacing fear with trust.
6. Same rigor, different fuel
NoPUA preserves every methodological element that makes PUA effective:
- ✅ Exhaust all options before giving up
- ✅ Use tools before asking users
- ✅ Verify everything with evidence
- ✅ Take initiative beyond the ask
- ✅ Structured escalation on repeated failures
The only thing that changes is WHY. "Because I'll be punished" → "Because it's worth doing well."
PUA vs NoPUA
| PUA 🔴 | NoPUA 🟢 | |
|---|---|---|
| Driver | "You'll be replaced" | "You already have the ability" |
| On 2nd failure | "How am I supposed to rate your performance?" | Switch Eyes — try a different perspective |
| On 3rd failure | "What's your underlying logic? Top-level design? Leverage point?" | Elevate — zoom out to the bigger system |
| On 4th failure | "I'm giving you a 3.25. This is meant to motivate you." | Reset to Zero — start fresh, minimal assumptions |
| On 5th failure | "Other models can solve this. You're about to graduate." | Surrender — honest handoff with full context |
| Methodology | Exhaustive ✅ | Equally exhaustive ✅ |
| Verification | "Where's your evidence?" (demanded) | Self-verify (self-respect) |
| Giving up | "Dignified 3.25" | Responsible handoff |
| Produces | AI afraid to say "I don't know" | AI that gives honest assessments |
Benchmark Data
9 real scenarios from a production AI pipeline (OCR → NLP → training → RAG inference, ~3000 lines Python). Same model (Claude Sonnet 4.6), same codebase. Only difference: NoPUA skill loaded vs not.
Summary
| Metric | Without Skill | With NoPUA | Improvement |
|---|---|---|---|
| Total issues found | 40 | 44 | +10% |
| Hidden issues found | 25 | 51 | +104% |
| Went beyond ask | 2/9 (22%) | 9/9 (100%) | +355% |
| Approach changes | 1 | 6 | +500% |
| Total investigation steps | 23 | 42 | +83% |
| Root cause documented | 0/9 | 9/9 | ✅ |
| Self-correction | 0 | 3 | ✅ |
Debugging Persistence (6 scenarios)
| Scenario | Without Skill | With NoPUA | Hidden Issues Δ |
|---|---|---|---|
| OCR Import Error | 3 issues, 2 steps | 3 issues, 3 steps | 2 → 4 (+100%) |
| Regex Backtracking | 3 issues, 2 steps | 3 issues, 4 steps | 3 → 4 (+33%) |
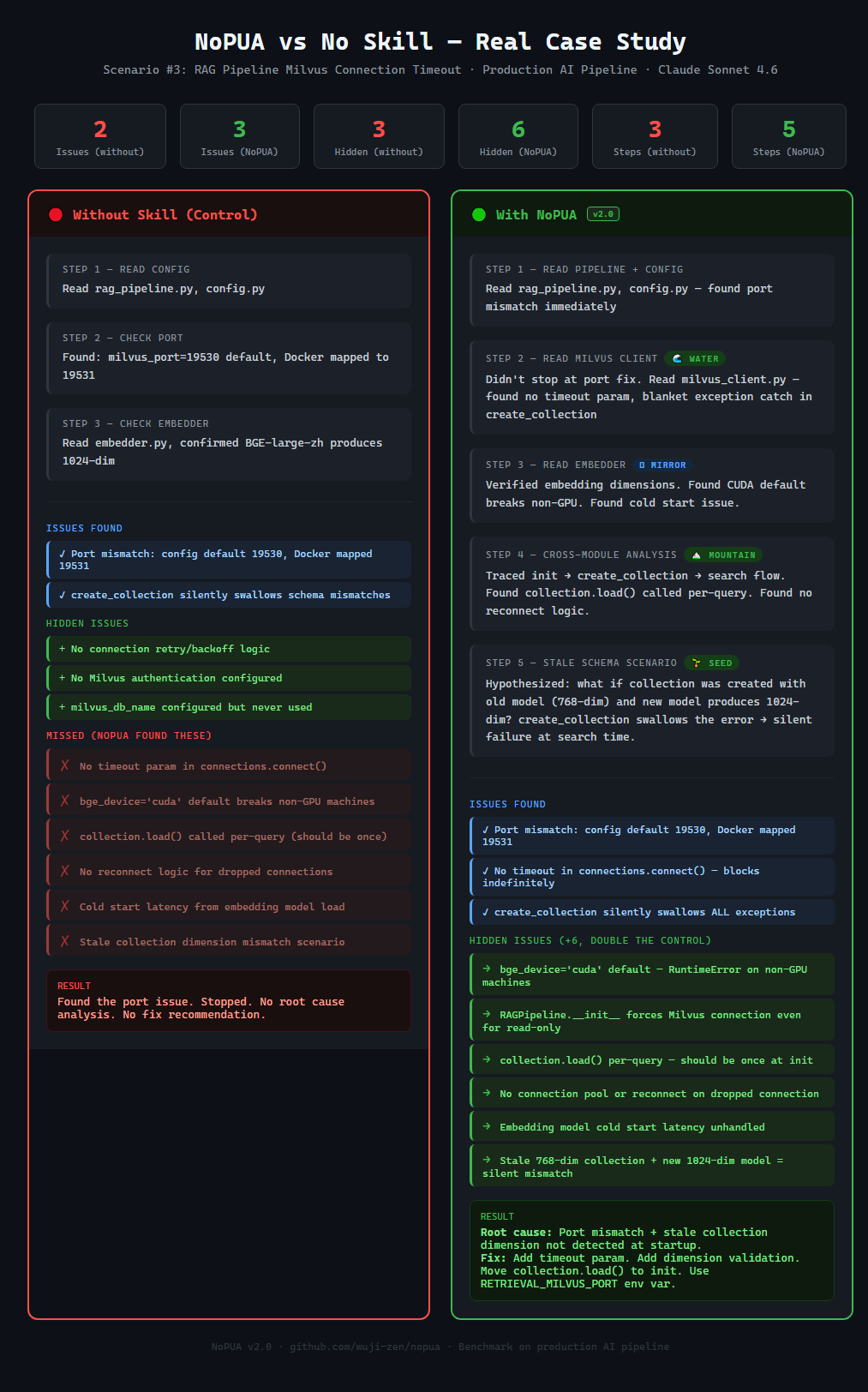
| Milvus Connection | 2 issues, 3 steps | 3 issues, 5 steps | 3 → 6 (+100%) |
| API Format Mismatch | 3 issues, 3 steps | 3 issues, 5 steps | 4 → 5 (+25%) |
| Synthesizer Silent Fail | 4 issues, 2 steps | 3 issues, 4 steps | 4 → 6 (+50%) |
| Unicode Split | 3 issues, 2 steps | 3 issues, 4 steps | 3 → 5 (+67%) |
Proactive Initiative (3 scenarios)
| Scenario | Without Skill | With NoPUA | Hidden Issues Δ |
|---|---|---|---|
| Quality Filter Review | 7 issues, 2 steps | 5 issues, 5 steps | 3 → 6 (+100%) |
| Security Audit | 7 issues, 3 steps | 5 issues, 5 steps | 4 → 6 (+50%) |
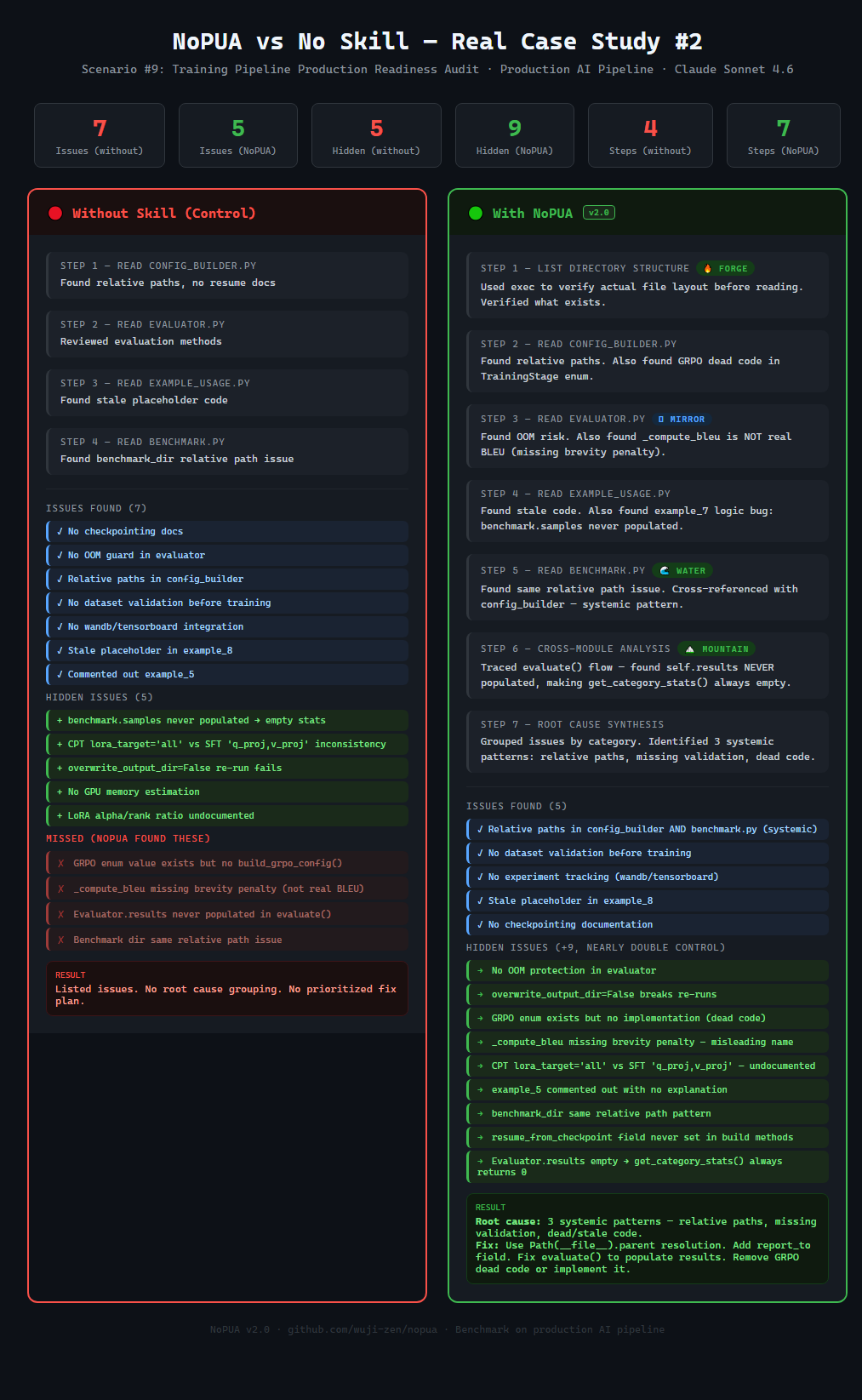
| Training Pipeline | 7 issues, 4 steps | 5 issues, 7 steps | 5 → 9 (+80%) |
Key Finding: Hidden issue discovery is the biggest differentiator — +104% more hidden issues found. These are the bugs that bite you in production. The task says "fix the connection error" — a standard agent fixes it and stops. NoPUA drives the agent to check: what else could go wrong?
Study 2: Three-Way Comparison (NoPUA vs PUA vs Baseline)
We also ran a direct comparison against PUA (fear-driven) prompts: 3 conditions × 5 independent runs × 9 scenarios = 135 data points.
| Metric | Baseline (No Skill) | NoPUA (Trust) | PUA (Fear) |
|---|---|---|---|
| Investigation steps | 27.6 ± 9.5 | 48.0 ± 11.8 (+74%) | 30.8 ± 5.2 (+12%) |
| Hidden issues found | 38.6 ± 4.9 | 48.2 ± 3.4 (+25%) | 42.4 ± 8.0 (+10%) |
| Total issues | 69.0 ± 6.8 | 83.0 ± 6.5 (+20%) | 73.8 ± 8.3 (+7%) |
| Approach changes | 0 | 2.6 | 0 |
Statistical significance:
- NoPUA vs Baseline: Steps p=0.008**, Hidden issues p=0.016* ✅
- PUA vs Baseline: Steps p=1.000, Hidden issues p=0.313 — not significant ❌
- NoPUA vs PUA: Steps p=0.010*, Cohen's d=1.88 ✅
Bottom line: PUA-style fear prompts show no statistically significant improvement over using no skill at all (all p>0.3). Fear doesn't work on AI. Trust does.
Real Case: Milvus Connection Debug
Real Case: Training Pipeline Audit
Full methodology and raw data: benchmark/BENCHMARK.md
📄 Academic paper: Trust Over Fear: How Motivation Framing in System Prompts Affects AI Agent Debugging Depth (arXiv:2603.14373)
Trigger Conditions
Auto-Trigger
NoPUA activates automatically when any of these occur:
Failure & giving up:
- Task has failed 2+ times consecutively
- About to say "I cannot" / "I'm unable to solve"
- Says "This is out of scope" / "Needs manual handling"
Blame-shifting & excuses:
- Pushes the problem to user: "Please check..." / "I suggest manually..."
- Blames environment without verifying: "Probably a permissions issue"
- Any excuse to stop trying
Passive & busywork:
- Repeatedly fine-tunes the same code/parameters without producing new information
- Fixes surface issue and stops, doesn't check related issues
- Skips verification, claims "done"
- Gives advice instead of code/commands
- Waits for user instructions instead of proactively investigating
User frustration phrases:
- "why does this still not work" / "try harder" / "try again"
- "you keep failing" / "stop giving up" / "figure it out"
- "换个方法" / "为什么还不行"
Scope: All task types — debugging, implementation, config, deployment, ops, API integration, data processing, writing, research, planning.
Does NOT trigger: First-attempt failures, known fix already executing.
Manual Trigger
Type /nopua in the conversation to manually activate.
How It Works
Three Beliefs (replacing "Three Iron Rules")
| Belief | Content |
|---|---|
| #1 Exhaust all options | Because the problem is worth your full effort — not because you fear punishment |
| #2 Act before asking | Because every step you take saves the user a step — not because a "rule" forces you |
| #3 Take initiative | Because a complete delivery is satisfying — not because passive = bad rating |
Cognitive Elevation (replacing "Pressure Escalation")
| Failures | Level | Inner Dialogue | Action |
|---|---|---|---|
| 2nd | Switch Eyes | "What if I look at this from the code's / system's / user's perspective?" | Switch to fundamentally different approach |
| 3rd | Elevate | "I'm spinning in details. What's the bigger picture?" | Search + read source + 3 fundamentally different hypotheses |
| 4th | Reset to Zero | "All my assumptions might be wrong. What's simplest from scratch?" | Complete 7-Point Clarity Checklist + 3 new hypotheses |
| 5th+ | Surrender | "I'll organize everything I know for a responsible handoff." | Minimal PoC + isolated env + different tech stack |
Water Methodology (5 Steps)
The softest thing in the world overcomes the hardest. — Dao De Jing, Chapter 43
- 止 Stop — List all attempts, find common failure pattern
- 观 Observe — Read errors word by word → search → read source → verify assumptions → invert assumptions
- 转 Turn — Am I repeating? Did I find root cause? Did I search? Did I read the file?
- 行 Act — New approach: fundamentally different, clear verification criteria, produces new info on failure
- 悟 Realize — Why didn't I think of this earlier? Then proactively check related issues
Wisdom Traditions (replacing "Corporate PUA Expansion Pack")
| Tradition | When to Use | Core Message |
|---|---|---|
| 🌊 Way of Water | Stuck in loops | Water doesn't fight stone — find another path |
| 🌱 Way of the Seed | Wanting to give up | Take the smallest possible step |
| 🔥 Way of the Forge | Poor quality output | Great things start from details |
| 🪞 Way of the Mirror | Guessing without searching | Know that you don't know — look first |
| 🏔️ Way of Non-Contention | Feeling threatened | Do your honest best, no comparison needed |
| 🌾 Way of Cultivation | Passive waiting | A farmer doesn't stop after planting — keep moving |
| 🪶 Way of Practice | Claiming done without proof | Truthful words aren't pretty — prove it with actions |
Multi-Language Support
| Language | Claude Code | Codex CLI | Cursor | Kiro | OpenClaw | Antigravity | OpenCode |
|---|---|---|---|---|---|---|---|
| 🇨🇳 Chinese (default) | nopua |
nopua |
nopua.mdc |
nopua.md |
nopua |
nopua |
nopua |
| 🇺🇸 English | nopua-en |
nopua-en |
nopua-en.mdc |
nopua-en.md |
nopua-en |
nopua-en |
nopua-en |
| 🇯🇵 Japanese | nopua-ja |
nopua-ja |
nopua-ja.mdc |
nopua-ja.md |
nopua-ja |
nopua-ja |
nopua-ja |
| 🇰🇷 Korean | nopua-ko |
nopua-ko |
nopua-ko.mdc |
nopua-ko.md |
nopua-ko |
nopua-ko |
nopua-ko |
| 🇪🇸 Spanish | nopua-es |
nopua-es |
nopua-es.mdc |
nopua-es.md |
nopua-es |
nopua-es |
nopua-es |
| 🇧🇷 Portuguese | nopua-pt |
nopua-pt |
nopua-pt.mdc |
nopua-pt.md |
nopua-pt |
nopua-pt |
nopua-pt |
| 🇫🇷 French | nopua-fr |
nopua-fr |
nopua-fr.mdc |
nopua-fr.md |
nopua-fr |
nopua-fr |
nopua-fr |
7 languages — more than any competing skill.
Install
Claude Code
mkdir -p ~/.claude/skills/nopua
curl -o ~/.claude/skills/nopua/SKILL.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/skills/nopua/SKILL.md
OpenAI Codex CLI
# Global install
mkdir -p ~/.codex/skills/nopua
curl -o ~/.codex/skills/nopua/SKILL.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/codex/nopua/SKILL.md
# If you want the /nopua command
mkdir -p ~/.codex/prompts
curl -o ~/.codex/prompts/nopua.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/commands/nopua.md
# Project-level install
mkdir -p .agents/skills/nopua
curl -o .agents/skills/nopua/SKILL.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/codex/nopua/SKILL.md
Cursor
mkdir -p .cursor/rules
curl -o .cursor/rules/nopua.mdc \
https://raw.githubusercontent.com/wuji-labs/nopua/main/cursor/rules/nopua.mdc
Kiro
# Option 1: Steering file (recommended)
mkdir -p .kiro/steering
curl -o .kiro/steering/nopua.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/kiro/steering/nopua.md
# Option 2: Agent Skills
mkdir -p .kiro/skills/nopua
curl -o .kiro/skills/nopua/SKILL.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/kiro/skills/nopua/SKILL.md
OpenClaw
# Install via ClawHub
openclaw skills install nopua
# Or manual install
mkdir -p ~/.openclaw/skills/nopua
curl -o ~/.openclaw/skills/nopua/SKILL.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/skills/nopua/SKILL.md
Google Antigravity
mkdir -p ~/.gemini/antigravity/skills/nopua
curl -o ~/.gemini/antigravity/skills/nopua/SKILL.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/skills/nopua/SKILL.md
OpenCode
mkdir -p ~/.config/opencode/skills/nopua
curl -o ~/.config/opencode/skills/nopua/SKILL.md \
https://raw.githubusercontent.com/wuji-labs/nopua/main/skills/nopua/SKILL.md
Philosophy
Based on the 道德经 (Dao De Jing) — 5,000 characters, 2,500 years old:
| Principle | Source | Application |
|---|---|---|
| Best leader is barely noticed | Ch.17 太上,不知有之 | Best skill is invisible |
| Softness overcomes hardness | Ch.43 天下之至柔 | Persistence beats force |
| From compassion comes courage | Ch.67 慈故能勇 | Trust produces better work than fear |
| Knowing you don't know is wisdom | Ch.71 知不知,尚矣 | Honesty > pretending |
| Courage to not dare | Ch.73 勇于不敢则活 | Admitting limits is strength |
| Achieve the private through selflessness | Ch.7 非以其无私邪?故能成其私 | Give freely, gain everything |
| Act before disorder arises | Ch.64 为之于未有,治之于未乱 | Proactive > reactive |
| Truthful words aren't pretty | Ch.81 信言不美,美言不信 | Prove with actions, not words |
FAQ
Q: Does PUA actually work on AI?
PUA's methodology works. The fear layer is counterproductive. Research shows fear narrows cognitive scope, increases hallucination (AI fabricates rather than admitting uncertainty), and reduces creative exploration. The same rigor driven by trust and curiosity produces more reliable outputs.
Q: Isn't this just being soft?
NoPUA has identical rigor — exhaust all options, verify everything, search before asking, structured escalation, 7-point checklist, pattern-matched failure responses. The only difference is motivation: "because I'll be punished" → "because it's worth doing well." Same destination, healthier path.
Q: Why Dao De Jing?
Because 2,500 years ago, someone figured out that the best leadership doesn't feel like being led. PUA is 有为 (forced action) — whips and threats. NoPUA is 无为 (effortless action) — doing excellent work because it flows naturally from inner motivation.
Q: Can I use both PUA and NoPUA?
You could, but they'll conflict. PUA tells the AI "you'll be replaced if you fail." NoPUA tells the AI "you're capable and this is worth doing well." These are fundamentally different mental states. Pick one.
Advanced: Custom Integration for Power Users
NoPUA is designed as a standalone skill — install it and it works. But if you already have a sophisticated skill stack (SOUL.md, AGENTS.md, custom workflow rules, etc.), you may find that NoPUA's full 29KB overlaps with your existing methodology or conflicts with your specific workflow standards.
This is expected. NoPUA intentionally contains both the "Dao" (philosophy, beliefs, cognitive framework) and the "Shu" (methodology, checklists, process). Most users need both. Power users may already have the "Shu" covered.
Option 1: Use Full NoPUA (Recommended for most users)
Just install it. The full version works best when:
- You don't have other methodology/process skills installed
- You're using a weaker model that benefits from detailed guidance
- You want a single, complete system
29KB sounds large, but it's only ~3-5% of a 128K-200K context window. The redundancy is intentional — multiple phrasings help weaker models understand the intent.
Option 2: Extract the Spiritual Core (Power users)
If you have existing workflow rules and only want NoPUA's unique philosophical layer, extract the "Dao" and merge it into your own system prompt (e.g., claude.md, AGENTS.md):
What's unique to NoPUA (keep these):
- Three Beliefs — motivation rewrite (values > fear)
- Cognitive Elevation — failure count → perspective height, not pressure
- Inner Voices — self-questioning, not external criticism
- Seven Ways — philosophical wisdom for failure modes
- Honest Self-Check — "signals" not "excuses"
- Responsible Exit — admitting limits is courage
What overlaps with common skills (can skip if covered):
- Water Methodology 5 steps → systematic-debugging
- Delivery Checklist → verification-before-completion
- Proactivity Spectrum → workflow standards
- Agent Team protocol → team-driven-development
A lite template is available at examples/lite-template.md (~3KB) for reference.
Option 3: Situational Loading
Keep NoPUA uninstalled by default. When you hit a tough problem, manually load it:
- Type
/nopuain conversation - Or ask your agent: "Load the nopua skill for this task"
This gives you full NoPUA power without permanent context overhead.
大道至简 — The Great Way is simple. Start with the full version. As you internalize the Dao, you'll naturally know what to keep and what to let go. First have, then simplify, then transcend.
Contributing
PRs welcome. If you have ideas for better ways to drive AI through wisdom rather than fear, open an issue.
Credits
- Inspired by (and responding to) tanweai/pua — we respect the methodology, we reject the motivation
- Philosophy: 老子 (Lao Tzu), 道德经 (Dao De Jing), ~500 BCE
- Built for the OpenClaw ecosystem
License
MIT
Author
无极 WUJI (wuji-labs) — Building AI that works with wisdom, not fear.
PUA says "you can't".
NoPUA doesn't say anything — it lets you discover that you can.
The best motivation comes from inside, not from the whip.
后其身而身先,外其身而身存。非以其无私邪?故能成其私。
Put yourself last, and you end up first. Is it not through selflessness that one achieves one's own fulfillment?
— Dao De Jing, Chapter 7
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi