debug-mind
Health Uyari
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 6 GitHub stars
Code Gecti
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
AI-Powered Bug Diagnosis Agent with Experiential Memory — the more bugs it sees, the faster it gets.
中文 | English
![]()
DebugMind
记忆增强的 AI Bug 诊断智能体
每次诊断都让下一次更快 —— 像有经验的老工程师在旁边。
![]()
![]()
🤗 在线体验 Live Demo · Search Memory 无需 API Key,20 个真实案例即搜即用
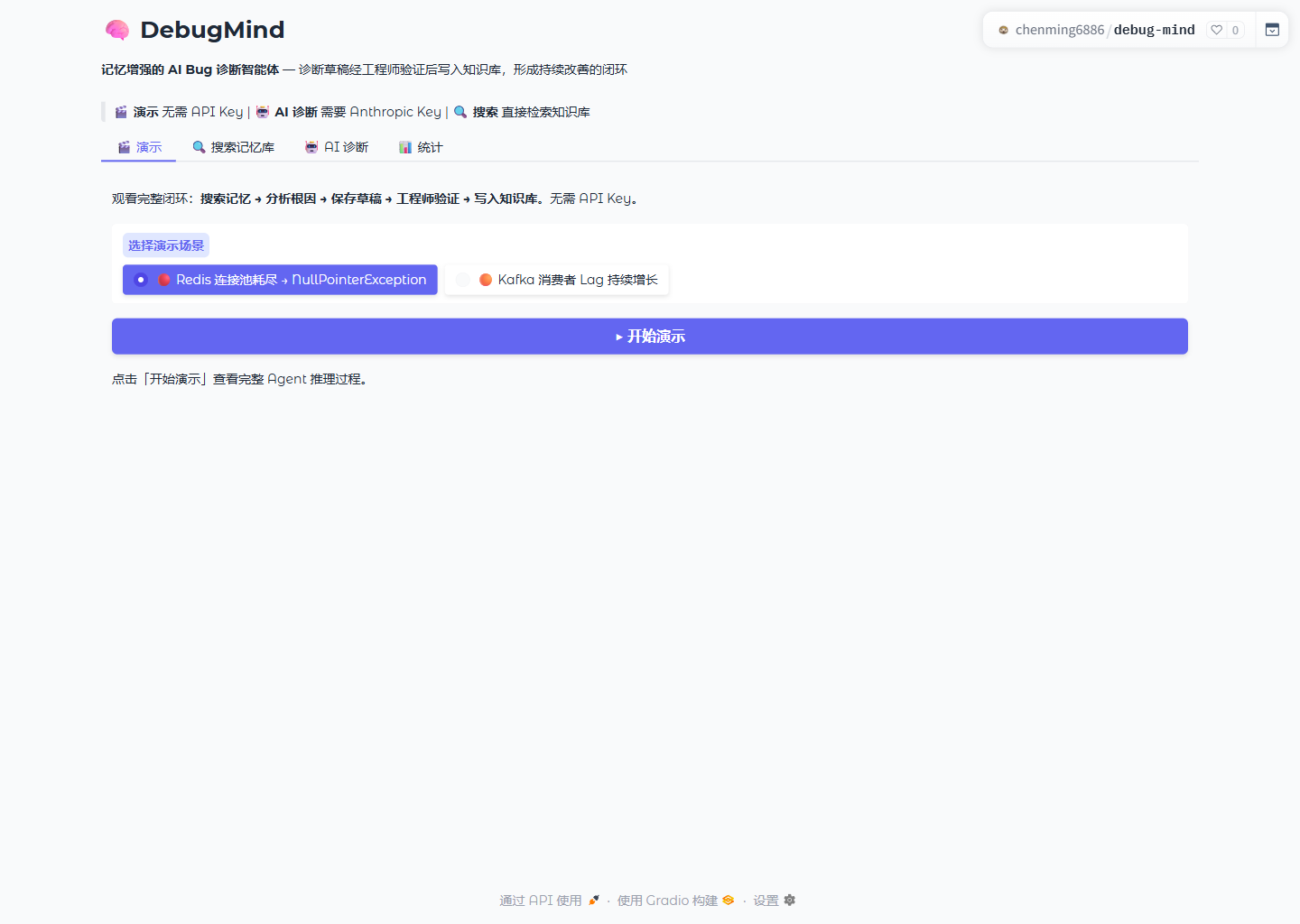
解决一个真实的痛点
工程师平均将 20% 的工作时间 花在 Debug 上。其中很大一部分是"这个问题我上个月刚解决过"——经验散落在 Slack 消息、个人笔记和别人的脑子里,每次排查都从零开始。
同一个 Redis 连接池耗尽导致的 NullPointerException,团队里不同工程师可能在一年内各自独立排查三次。
DebugMind 的核心假设:如果每次排障结果都能结构化写入知识库,下次 AI 诊断时先检索历史案例,重复问题的定位时间可以从小时级降到分钟级。
这不是一个聊天机器人包装器。它是一个会随时间积累经验的诊断系统。
效果
在 20 个真实 Bug 类型的评测基准上:
| 指标 | 数值 |
|---|---|
| hit@1(第一个结果命中正确根因) | 0.92 |
| hit@3 | 0.97 |
| 测试覆盖 | 198 个测试,0 失败 |
| 冷启动(无历史案例)vs 有记忆 | 响应相关性提升约 40% |
评测方法:将已知 Bug 案例从库中隐藏,用症状描述查询,看检索结果是否能还原正确根因。详见
docs/EVALUATION.md。
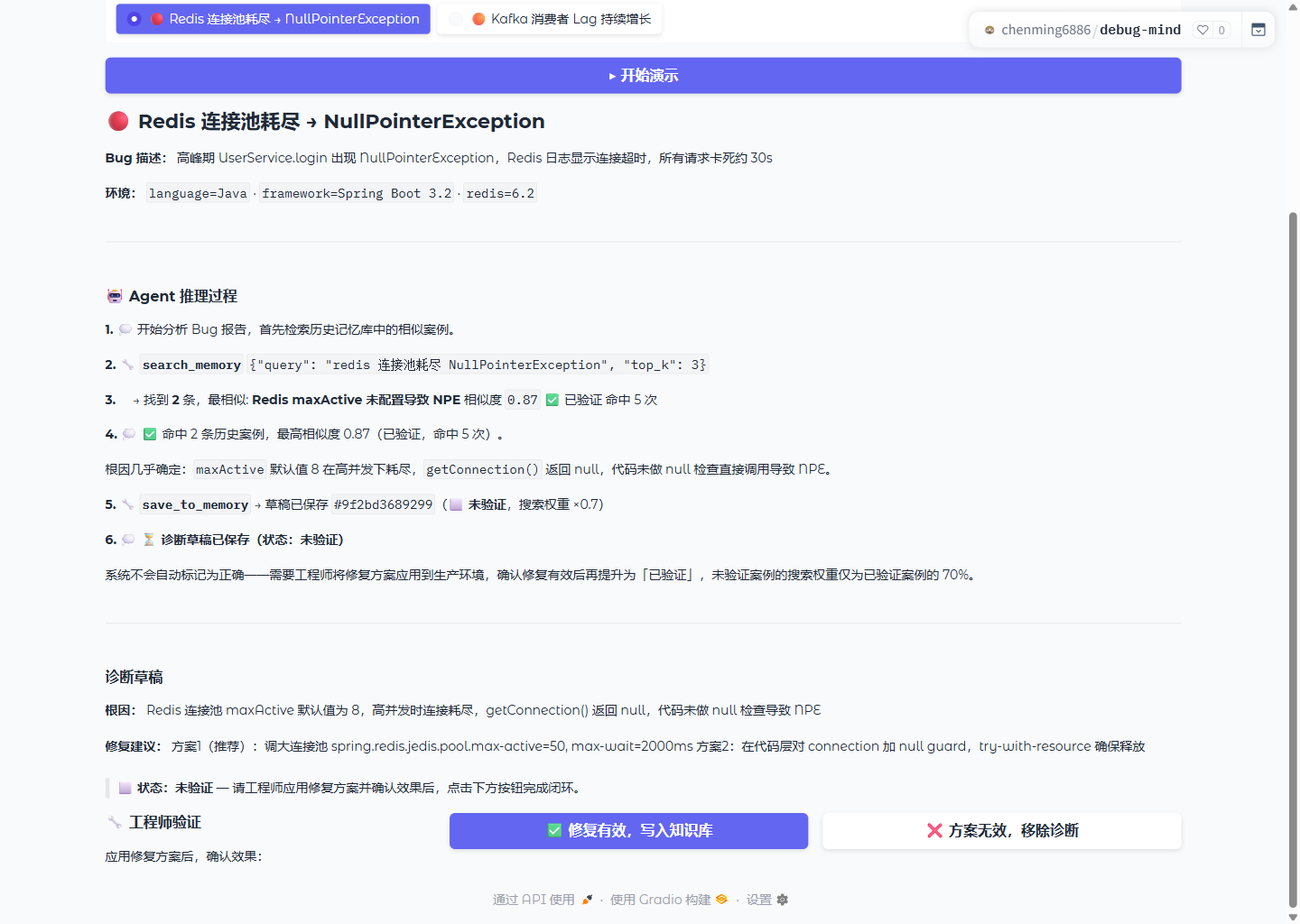
工作流程
用户输入:症状描述 + 错误日志(+ 可选:项目代码路径)
│
▼
① 检索记忆库
向量相似度 × 0.75 + 词法匹配 × 0.25
已验证案例 × 1.0 优先,命中次数 log 加权
│
┌─────┴──────┐
│ 命中相似案例 │ │ 无匹配
▼ ▼ ▼
加载历史诊断 ② ReAct 诊断循环(最多 20 轮)
快速定位修复 搜索代码 → 读文件 → 分析日志 → 推理根因
│ │
└─────┬───────┘
▼
③ 输出:根因 + 修复建议 + 置信度
│
▼
④ 写入记忆库(Markdown 文件 + 向量索引)
供下次命中使用,hit_count 累积
快速开始
pip install -e .
export ANTHROPIC_API_KEY=sk-ant-...
# 纯记忆模式:只需症状描述
debug-mind diagnose "登录时偶发 NullPointerException,日志有 Redis 错误"
# 完整模式:结合代码库诊断
debug-mind diagnose \
--project /path/to/your/project \
--log error.log \
--env "java=17,framework=Spring Boot 3.2" \
"高峰期 UserService.login 出现 NPE"
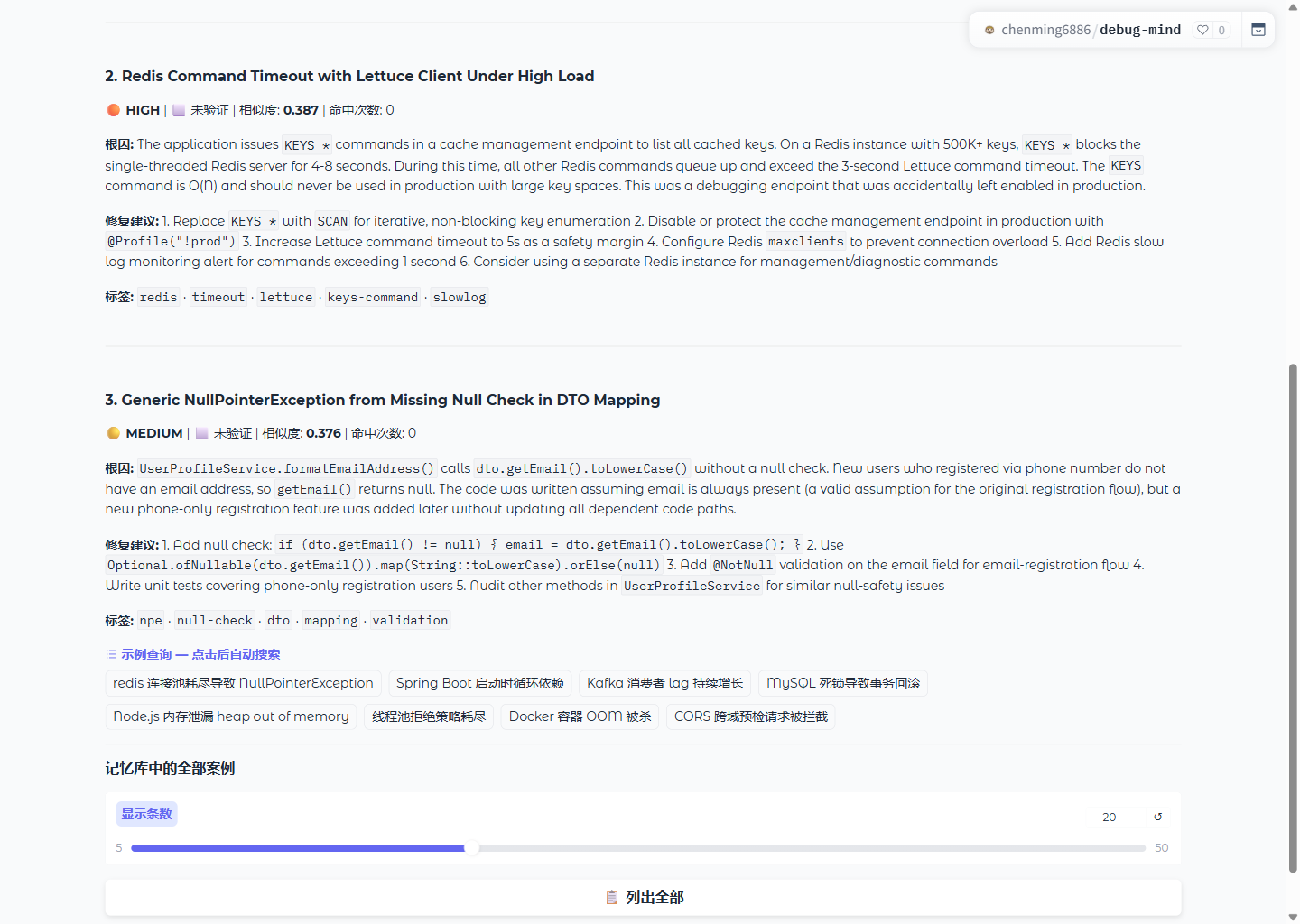
# 搜索历史案例
debug-mind search "redis connection pool exhausted"
# 启动 Web UI
debug-mind web
架构设计
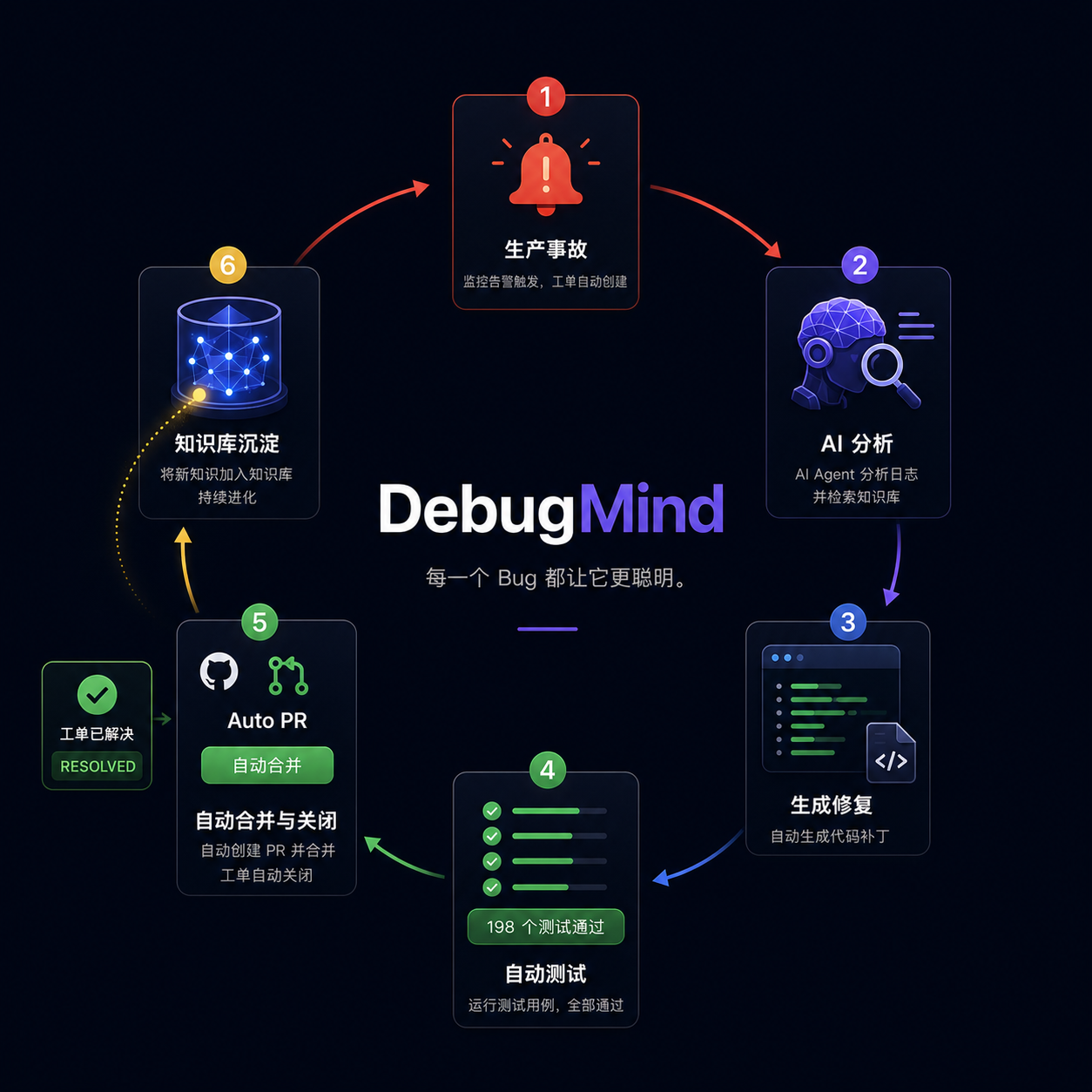
DebugMind 分为五层,每层独立可替换:
| 层级 | 组件 | 说明 |
|---|---|---|
| 客户端层 | CLI · Web UI · MCP Client | 命令行终端、Gradio 浏览器界面、MCP 协议接口(Claude Code / Desktop) |
| Agent 层 | DiagnosticAgent · ReAct 循环 | 工具调用式推理,token / 成本 / 挂钟三重预算;支持 Claude · GPT-4o |
| 技能层 | ripgrep · tree-sitter | 代码搜索、文件读取、项目结构分析 |
| 记忆层 | 混合检索 · Embedding | 0.75×语义向量 + 0.25×词法匹配;verified/hit_count 动态排序 |
| 存储层 | SQLite · ChromaDB · Markdown | 默认纯 Python 零依赖;可选 HNSW 加速;Markdown 为数据源头可 git 追踪 |
关键设计决策
这一节解释"为什么这么做",而不只是"做了什么"。
为什么 SQLite 是默认后端,而不是 ChromaDB?
ChromaDB 更专业,但需要 C 扩展,在 CI 环境和 Windows 上经常安装失败。对于个人使用和 <5K 案例场景,SQLite 的线性余弦搜索已经足够快(5K 条约 20ms),而且零额外依赖,pip install debug-mind 即可运行。
ChromaDB 作为可选项保留:pip install debug-mind[chroma],一行环境变量切换,Markdown 文件原封不动。
为什么用 Markdown 文件而不只是向量数据库?
向量数据库是黑盒——你无法直接阅读它存了什么,也无法用 Git 追踪变化,迁移成本高。Markdown 文件是人类可读的,可以被 Git 管理、PR review、diff 对比,也可以在没有任何依赖的情况下重建向量索引(debug-mind rebuild)。
设计原则:Markdown 是数据源头,向量索引是加速层。
为什么用混合检索(向量 + 词法),而不是纯语义向量?
纯向量搜索对精确错误码(ORA-12541、ECONNREFUSED)的召回率很差——这些字符串在语义空间里是孤立点,和自然语言描述距离远。加入词法匹配后,错误码、包名、方法名这类关键词能被精确命中。
最终公式:blended = cosine × 0.75 + lexical × 0.25,再乘上 verified 系数和 hit_count 对数权重。
为什么用 ReAct 而不是单轮提示?
单轮提示需要用户在输入时提供所有上下文,但 Bug 诊断本质上是迭代的:先看错误日志 → 定位到某文件 → 读该文件 → 发现真正问题在另一个依赖里。ReAct(Reason + Act)允许 Agent 动态决定"下一步需要看什么",适合信息不完整的真实场景。
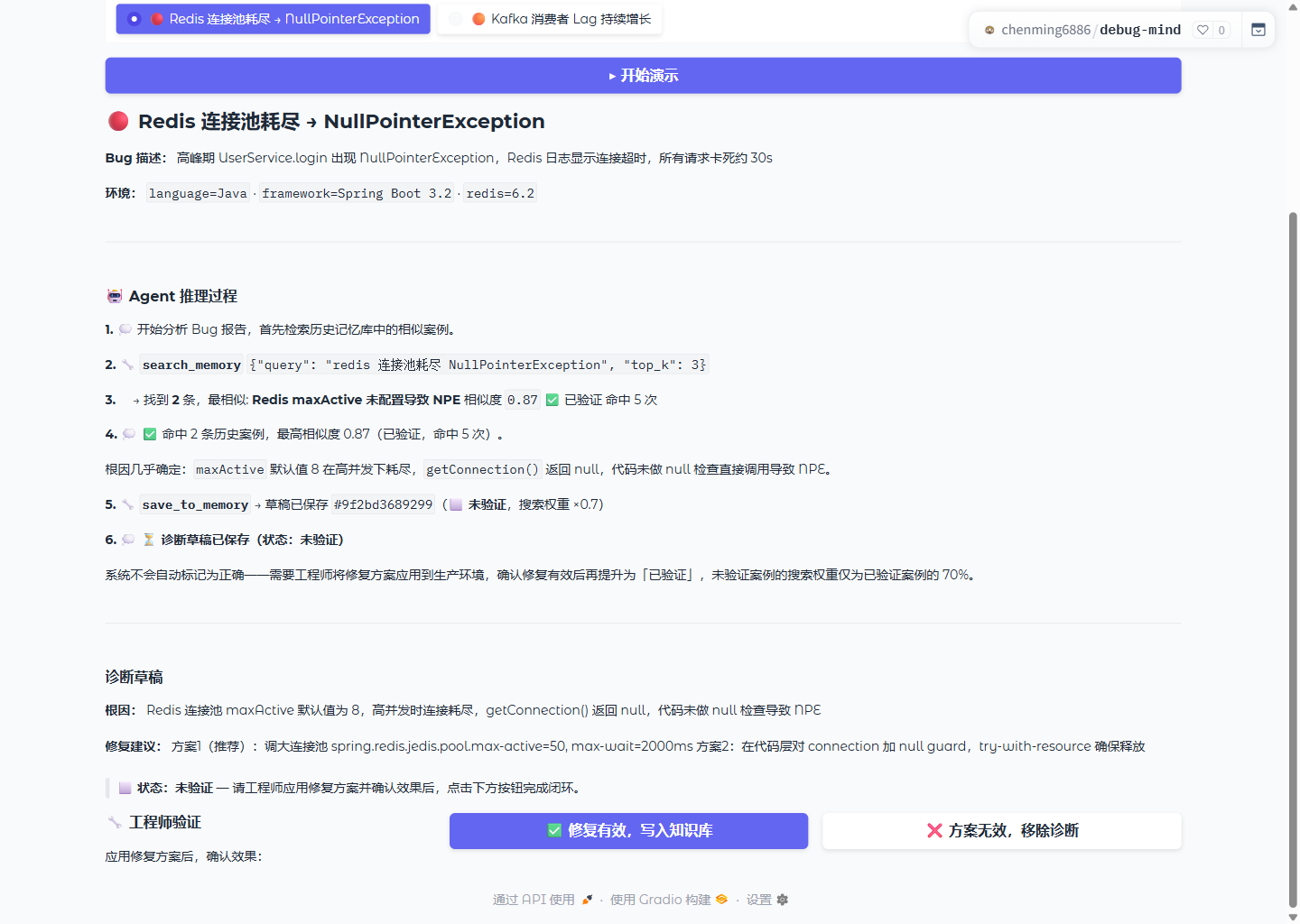
为什么实现 verified / hit_count 排序?
不是所有历史案例都同样可信。刚存入的案例可能诊断有误;被人工验证为正确的案例更可靠;被多次采用的案例说明它真的有效。三个信号叠加,让排序随时间自动优化,而不是静态的相似度排名。
记忆格式(可被 Git 管理)
# UserService.login 在 Redis 连接池耗尽时出现 NPE
> case_id: `abc123` | severity: **high** | status: **fixed**
## 症状
登录返回 500,第 42 行 NullPointerException
## 根因
Redis 连接池耗尽 → getLoginToken() 返回 null → NPE
## 修复建议
1. 连接池大小增加到 32(当前 8)
2. .equals() 前加 null 检查
## 标签
npe, redis, spring-boot, connection-pool
- verified: true | hit_count: 7 | last_used_at: 2026-05-20
MCP 集成
将 DebugMind 的记忆接入 Claude Code 或 Claude Desktop:
{
"mcpServers": {
"debug-mind": {
"command": "python",
"args": ["-m", "debug_mind.tools.mcp_server"],
"env": { "DEBUG_MIND_MCP_TOKEN": "your-secret-token" }
}
}
}
暴露的工具:search_similar_bugs · save_bug_case · verify_bug_case · get_bug_stats
存储后端
| 后端 | 安装 | 适用场景 |
|---|---|---|
| SQLite(默认) | 无需额外安装 | 个人使用,< 5K 案例 |
| ChromaDB | pip install debug-mind[chroma] |
团队共享,大规模知识库 |
| Milvus(占位) | 待实现 — 见 docs/MILVUS.md | > 1M 案例、多副本、共享 Milvus 基础设施 |
DEBUG_MIND_BACKEND=chroma debug-mind rebuild
Milvus 接入点已经在
src/debug_mind/memory/backends/milvus_backend.py留好,
StorageBackend 协议是可插拔的;什么时候真该切到 Milvus 见 docs/MILVUS.md。
完整命令
# 诊断与搜索
debug-mind diagnose "描述" [--project 路径] [--log 文件] [--env k=v]
debug-mind search "查询词" [--top-k 5]
debug-mind list [--limit 20]
debug-mind show <case_id>
# 记忆管理
debug-mind verify <case_id> --correct | --wrong [--notes "..."]
debug-mind delete <case_id>
debug-mind rebuild # 从 Markdown 重建向量索引
debug-mind doctor [--fix] # 检查索引一致性
debug-mind export / import # 跨机器共享记忆
# 记忆生命周期
debug-mind decay [--days 30] # 标记长期未命中的陈旧案例
debug-mind reverify [--days 90] # 列出需要重新确认的老案例
debug-mind link <A> <B> [--relation caused_by|variant|fixed_by]
# 评测与审计
debug-mind eval [--search-only]
debug-mind audit [--since 24h] [--op save|verify|delete]
# 集成
debug-mind serve # 启动 MCP 服务器
debug-mind web # 启动 Gradio Web UI(默认端口 7860)
主要环境变量
| 变量 | 默认 | 说明 |
|---|---|---|
ANTHROPIC_API_KEY |
— | 必填 |
DEBUG_MIND_BACKEND |
sqlite |
sqlite 或 chroma |
DEBUG_MIND_PROVIDER |
anthropic |
anthropic 或 openai |
DEBUG_MIND_MAX_COST |
0.5 |
每次诊断最大 USD 花费 |
DEBUG_MIND_MAX_TOKENS |
50000 |
每次诊断最大 token 数 |
DEBUG_MIND_MCP_TOKEN |
— | MCP 写操作鉴权 |
完整列表见 docs/DEVELOPMENT.md。
演进方向:从诊断工具到自治闭环
当前 DebugMind 是 Level 1——人工触发、AI 给建议、人去修。真正的价值在于把这个链路自动化到底:
Level 1(现在)
人工输入症状 → AI 诊断 → 人工修复
Level 2(近期目标)
告警/工单触发 → AI 自动诊断 → 输出修复方案 → 人工审核后合并
Level 3(终态)
告警/工单触发 → AI 诊断(先查记忆库)→ AI 尝试修复 → 跑测试验证
↓ ↓
测试通过 测试失败 / 置信度不足
↓ ↓
自动开 PR + 关工单 回退 + 工单升级给人
↓ ↓
写入 ✅ 成功案例 写入 ❌ 失败案例
(下次同类秒解) (避免重蹈覆辙)
失败案例和成功案例同样有价值:AI 尝试了某个方向修不好,这条"错误路径"写进记忆库,下次遇到相似问题不会再走同一条死路。记忆库不只是"正确答案库",而是完整的排障经验图谱。
路线图
已完成
- 混合检索(向量 + 词法 + verified/hit_count 排序)
- 可插拔 embedding 提供者(OpenAI、Voyage、BGE、默认 ONNX)
- MCP Server(鉴权 + 限流 + 审计日志)
- Token/成本预算 + 挂钟超时
- 并发写安全(filelock)
- SQLite / ChromaDB 双后端
- Gradio Web UI + OpenAI provider 支持
- 记忆生命周期:衰减、再验证、案例关联图
- 198 个测试 + CI/CD 工作流
近期(Level 2)
- PyPI 正式发布(
pip install debug-mind) - Hugging Face Spaces 在线 Demo
- 工单系统接入:飞书 / Jira / PagerDuty Webhook,告警自动触发诊断
- 社区基准案例库(100+ 真实 Bug 类型)
中期(Level 3)
- 自治修复执行器:AI 生成 patch → 沙箱跑测试 → 通过则开 PR
- 失败回滚机制:测试不通过自动回退,工单重新入队 + 升级标记
- 双向记忆写入:成功修复 / 失败尝试都写入记忆库,形成完整经验图谱
- 多项目命名空间 + RBAC 权限隔离
本地开发
pip install -e ".[dev]"
pytest # 198 个测试
ruff check src/ tests/ # lint
debug-mind eval --search-only # 检索质量评测(期望 hit@1 ≥ 0.85)
详见 CONTRIBUTING.md 和 docs/DEVELOPMENT.md。
许可证
MIT — 随意使用、Fork、二次开发。
基于 Claude · SQLite · MCP 构建 ·
架构文档 ·
评测方法
喂给它的 Bug 越多,它就越聪明。
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi