krait
Health Uyari
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 8 GitHub stars
Code Basarisiz
- eval() — Dynamic code execution via eval() in patterns/ai-red-team/batch-6.yaml
Permissions Gecti
- Permissions — No dangerous permissions requested
This tool provides AI-assisted security auditing skills for Solidity smart contracts, executing a structured 4-phase methodology directly within the Claude Code CLI.
Security Assessment
The tool does not request dangerous system permissions, but the static code scan flags a critical issue: dynamic code execution via `eval()` inside a YAML file (`patterns/ai-red-team/batch-6.yaml`). While this might be a false positive triggered by a security testing payload rather than actual malicious code, any use of `eval()` is a high-risk vector. Otherwise, there are no hardcoded secrets, and the tool runs locally without making external network requests. Overall risk is rated as Medium due to the execution flag.
Quality Assessment
The project is actively maintained with a recent push and uses a standard MIT license. However, it has very low community visibility, boasting only 8 GitHub stars. The creator claims high precision across dozens of blind security contests, and the methodology is thoroughly documented, but these claims are entirely self-reported. There is minimal external validation or community trust established for this specific tool.
Verdict
Use with caution — the active maintenance and clear license are positives, but the low community trust and flagged dynamic code execution pattern warrant a careful manual review of the YAML file before running.
Claude Code skills for Solidity security auditing. 90% precision across 40 blind Code4rena contests. Zero API cost.
Krait
AI-assisted security verification for Solidity smart contracts. Not a scanner — a structured methodology with 43 heuristics, 26 analysis modules, and 8 kill gates, tested blind against 45 Code4rena contests at 100% precision. Runs inside Claude Code. Free.
At a Glance
| Detection angles | 16 per function (4 lenses × 4 mindsets) |
| Heuristics | 43 original + 58 extended (from open-source community) |
| Analysis modules | 15 deep-dive module files + 26 inline modules (A-X) |
| Domain primers | 7 (DEX, Lending, Staking, GameFi, Bridges, Proxies, Wallets) |
| Kill gates | 8 automatic + 10 FP patterns |
| Shadow audits | 50 contests, 100% precision, 0 FPs/contest (v8) |
| Full methodology | METHODOLOGY.md — every technique, publicly documented |
Two Products, One Goal
1. Audit skills (this repo) — run /krait in Claude Code on any Solidity project. Free.
2. Web platform (krait.zealynx.io) — AI-assisted security verification with per-check prompt generation, auto-parsed verdicts, shareable reports, and PDF export. Also free.
┌─────────────────────────────────────────────────────────────────────────┐
│ /krait (local) krait.zealynx.io (web) │
│ ───────────── ──────────────────── │
│ Run audit in Claude Code 845+ checks across 39 DeFi types │
│ 4-phase pipeline "Verify with AI" per check │
│ Findings with exploit traces ├─ Generates tailored prompt │
│ .audit/krait-findings.json ├─ Run in any IDE AI │
│ │ ├─ Paste response back │
│ └──► Upload to dashboard └─ Auto-detect verdict + files │
│ Shareable reports Shareable reports + PDF export │
│ Track over time Combined readiness score │
└─────────────────────────────────────────────────────────────────────────┘
Built by Zealynx Security — 30+ DeFi protocol audits.
What Krait Does
Krait is a structured audit methodology encoded as Claude Code skills. When you run /krait on a Solidity project, it executes a 4-phase pipeline:
- Recon — maps the architecture, extracts the AST, scores every file by risk, selects protocol-specific detection primers
- Detection — analyzes each high-risk function from 16 angles (4 technical lenses x 4 independent mindsets), with consensus scoring across passes
- State Analysis — finds coupled state pairs and mutation patterns that per-function scanning misses
- Verification — 8 kill gates try to disprove every finding. Only those with a concrete exploit trace (WHO does WHAT to steal HOW MUCH) survive
The output is a structured report with findings at exact file:line locations, vulnerable code, suggested fixes, and exploit traces. Saved as both markdown and JSON.
What Krait Is Not
- Not a linter or regex scanner — Claude reads and reasons about code
- Not a SaaS product with API costs — runs locally in your Claude Code session
- Not a replacement for a professional audit — it's a tool that catches real bugs before your auditor does
Quick Start
Requirements
- Claude Code (CLI, VS Code extension, or Cursor)
- A Claude subscription (Pro, Max, or Team)
- A Solidity project to audit
Install
git clone https://github.com/ZealynxSecurity/krait.git
mkdir -p ~/.claude/commands ~/.claude/skills
cp -r krait/.claude/commands/* ~/.claude/commands/
cp -r krait/.claude/skills/* ~/.claude/skills/
Open Claude Code in any Solidity project and run /krait.
Update
cd krait && git pull
cp -r .claude/commands/* ~/.claude/commands/
cp -r .claude/skills/* ~/.claude/skills/
Optional: Pattern Search MCP Server
Krait includes an MCP server that lets you search 47 vulnerability patterns locally. No API key needed.
cd krait/mcp-servers/solodit
npm install && npm run build
The .mcp.json in the repo root auto-configures it for Claude Code. The skills work fine without the MCP server — it's an optional pattern search tool for development.
Commands
| Command | What it does |
|---|---|
/krait |
Full 4-phase audit: Recon → Detection → State Analysis → Verification → Report |
/krait-quick |
Same pipeline, skips state analysis — ~2x faster |
/krait-review |
Second opinion on killed findings — re-examines aggressive gate decisions |
All output to .audit/ in your project directory.
After the Audit
Every run saves findings to .audit/krait-findings.json and shows:
───────────────────────────────────────────────────
📋 N findings saved to .audit/krait-findings.json
🔗 View this report online:
https://krait.zealynx.io/report/findings
📊 Track findings over time:
https://krait.zealynx.io/dashboard
───────────────────────────────────────────────────
Findings are already verified — the critic phase requires a concrete exploit trace for every H/M before it reaches the report.
If the critic killed many candidates, run /krait-review to get a second opinion on the gate decisions.
How Detection Works
Multi-Mindset Analysis (v7.0)
Each of the 4 detection lenses analyzes code through 4 independent mindsets simultaneously:
| Mindset | Question |
|---|---|
| Attacker | "How would I exploit this to drain funds or escalate privilege?" |
| Accountant | "Trace every wei — do the numbers add up?" |
| Spec Auditor | "Does the code match what docs, comments, and EIPs say it should do?" |
| Edge Case Hunter | "What breaks at zero, max, empty, self-referential, or reentrant?" |
Every function in high-risk files gets examined from 16 angles (4 lenses x 4 mindsets). Findings discovered by multiple mindsets get a consensus boost; single-source findings get extra scrutiny.
Kill Gates (Verification)
Eight automatic gates try to disprove every finding before it reaches you:
- A: Generic best practice ("use SafeERC20") · B: Theoretical/unrealistic
- C: Intentional design · D: Speculative (no WHO/WHAT/HOW MUCH)
- E: Admin trust · F: Dust (<$100) · G: Out of context · H: Known issue
Result: FPs dropped from 4.2/contest → 0.0/contest in v7 (100% reduction). The last 10 contests (v6.4+v7) had only 1 total FP across 10 contests.
Second Opinion (/krait-review)
The kill gates are aggressive by design — zero false positives is the priority. But aggressive gates can over-kill. Run /krait-review after an audit to re-examine killed findings with fresh eyes:
- Gate C (intentional design) — "intentional" doesn't always mean "safe"
- Gate E (admin trust) — missing timelocks and rug vectors are valid Mediums in many contests
- Gate B (theoretical) — retries exploit construction with flash loans, multi-block MEV
- Gate F (dust) — recalculates with protocol TVL context and accumulation analysis
Revived findings are surfaced as "Worth Manual Review" — flags for the auditor, not verified TPs. The main report's zero-FP standard is preserved.
Benchmarks
Tested blind against 50 Code4rena contests. No other AI audit tool publishes precision/recall against real competitions.
| Version | Contests | Precision | Recall | FPs/Contest |
|---|---|---|---|---|
| v1 | 1-3 | 12% | 5.8% | 1.3 |
| v5 | 31-35 | 70% | 9.5% | 0.6 |
| v6.4 | 36-40 | 90% | 11.8% | 0.2 |
| v7 | 41-45 | 100% | 11.0% | 0.0 |
| v8 | 46-50 | 100% | 15.2% | 0.0 |
Latest 5 contests (v8):
| Contest | Type | Official H+M | TPs | FPs | Precision | Recall |
|---|---|---|---|---|---|---|
| PoolTogether | ERC-4626 Prize Vault | 9 | 1 | 0 | 100% | 11% |
| GoodEntry | UniV3 Derivatives | 14 | 5 | 0 | 100% | 36% |
| Arcade | Governance/Voting | 8 | 2 | 0 | 100% | 25% |
| Frankencoin | CDP Stablecoin | 20 | 2 | 0 | 100% | 10% |
| InitCapital | Lending/Hooks | 15 | 0 | 0 | N/A | 0% |
Every result is verifiable in shadow-audits/.
Self-Improving
After each blind test: score → root-cause every miss → update methodology → re-test. This loop produced 43 original heuristics, 15 deep-dive module files, 58 extended heuristics, 26 inline modules, and 7 protocol-specific primers. v8 integrated open-source vectors from pashov/skills, PlamenTSV/plamen, and forefy/.context (all MIT) — improving recall from 11% to 15.2% while maintaining 100% precision.
Real Bugs Found (Blind)
- ONE_HUNDRED_WAD constant bug (Open Dollar H-01) — surplus auction math inflated 100x, bricking protocol economics (v7, CONST-01 heuristic)
- Gauge removal locks voting power (Neobase H-01) — contradictory guards permanently trap user governance power (v7, GAUGE-01 heuristic)
- Zero slippage on all swaps (BakerFi H-04) — amountOutMinimum=0 enables sandwich on every deposit/withdraw (v7)
- Oracle staleness OR vs AND (BakerFi M-06) — stale price accepted if either feed is fresh (v7)
- slot0 manipulation in TokenisableRange (GoodEntry H-04) — flash loan manipulates UniV3 spot price, stealing depositor fees (v8, amm-mev-deep module)
- Voting power not synced on multiplier change (Arcade M-05) — stale inflated voting power after NFT boost update (v8, governance-voting Pashov vector)
- claimYieldFeeShares zeroes entire balance (PoolTogether H-01) — partial claim wipes all fee accounting (v8, erc4626-vault-deep module)
- Challenger reward drains reserves (Frankencoin H-06) — self-challenge extracts unlimited rewards (v8, economic-design module)
- AuraVault claim double-spend (LoopFi H-401) — fees not deducted, draining vault
- UniV3 fee drain via shared position (Vultisig H-43) — first claimer steals all fees
- ILO launch DoS (Vultisig H-41) — slot0 manipulation blocks all launches
- Public internals → permanent fund lock (Phi H-51) — state corruption locks ETH
- Both HIGHs (Munchables) — lockOnBehalf griefing + early unlock, 100% precision
- Assembly encoding bug (DittoETH M-221) —
addvsandcorrupts data - ERC4626 inflation (Basin), reentrancy (reNFT), EIP-712 mismatch (reNFT), oracle precision (Dopex), TVL error (Renzo)
Detection Coverage
Strong on: Reentrancy/CEI, access control gaps, oracle issues (Chainlink + Pyth), EIP/ERC compliance, first-depositor inflation, accounting errors, assembly bugs, pause bypasses, slot0/spot price manipulation, ERC-4626 vault accounting, governance voting power sync, AMM/MEV vectors
Improving: Complex math (CDP liquidation, options pricing), cross-chain edge cases, game mechanic exploits, custom hook/plugin architectures, protocol-specific integrations (Curve adapter edge cases)
Web Platform — krait.zealynx.io
Verify with AI (Unique Feature)
Every security check on the web platform generates a tailored AI prompt you can copy-paste into Claude Code, Cursor, Windsurf, or Codex. The prompt includes:
- The specific vulnerability to look for
- Real exploit examples from Solodit (protocols that were actually hacked)
- What secure code looks like (from mitigation data)
- Code patterns to grep for
- Structured output format (PASS/FAIL/NA with file:line references)
When you paste the AI's response back, Krait auto-parses it:
- Detects the verdict (PASS/FAIL/NOT APPLICABLE/NEEDS REVIEW)
- Extracts file:line references
- Scores confidence (high/medium/low)
- Auto-sets the check status
This turns every check from "do you think you're ok?" into "let's verify against your actual code with AI."
Upload & View Reports
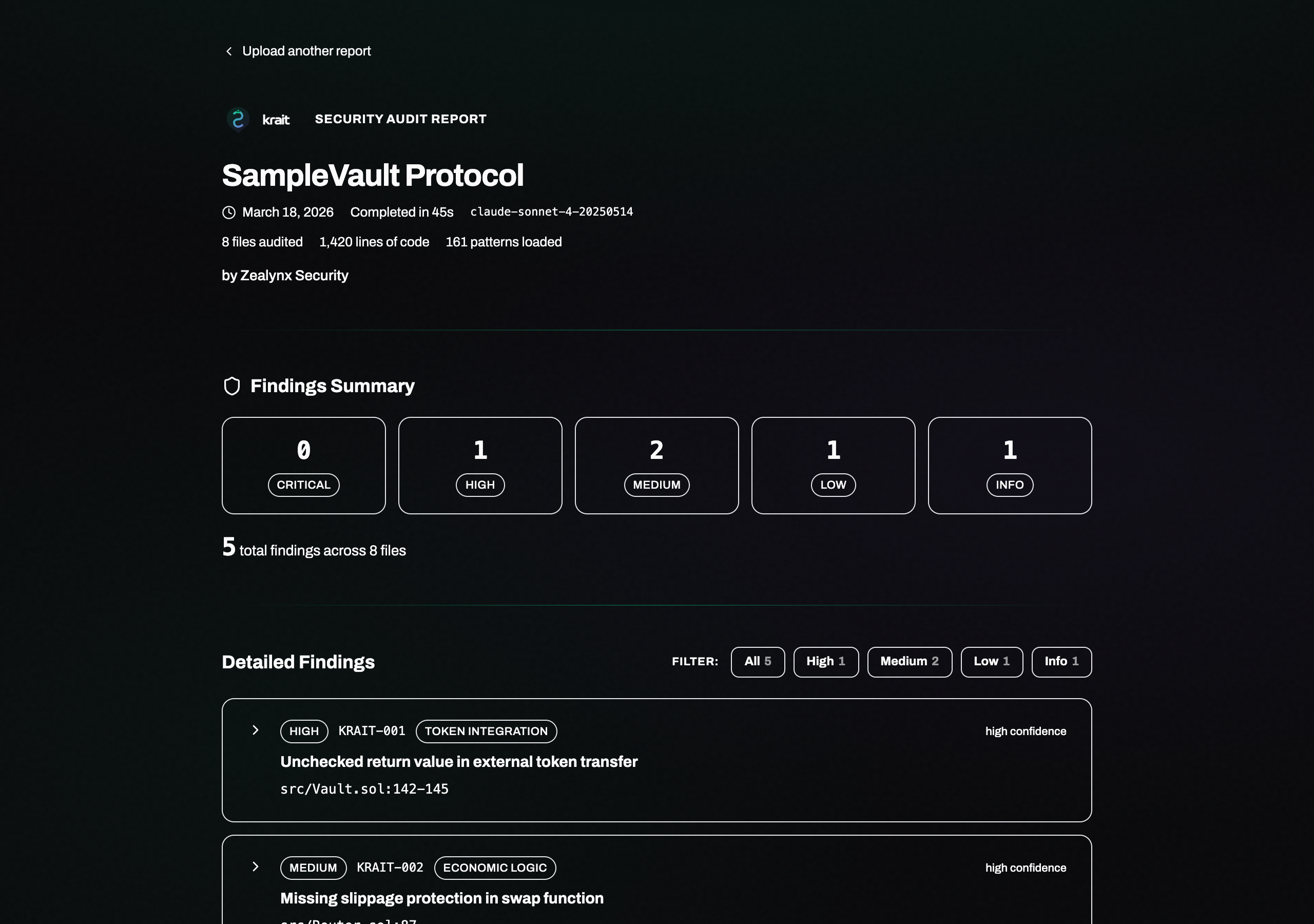
Upload .audit/krait-findings.json at krait.zealynx.io/report/findings for a branded report with severity breakdowns, exploit traces, and code diffs. Share via persistent link or download as PDF.
Security Verification (845+ Checks)
AI-assisted security verification covering 39 DeFi verticals — each check backed by real Solodit exploit data, with "Verify with AI" prompts for every single one. Not a checklist you fill out manually — a verification pipeline that leverages your IDE's AI.
Start at krait.zealynx.io/new.
Dashboard
krait.zealynx.io/dashboard — all projects in one place. Scan findings, verification scores, shareable reports, activity timeline.
Detection Sources
Krait's detection layer combines original research with curated knowledge from the open-source security community. See ATTRIBUTION.md for details.
| Source | What We Integrated | License |
|---|---|---|
| pashov/skills | ~100 attack vectors across 8 modules + 58 extended heuristics | MIT |
| PlamenTSV/plamen | Devil's Advocate verification methodology | MIT |
| forefy/.context | Protocol-type context enrichment (10,600+ findings) | MIT |
Author
Carlos Vendrell Felici — Founder, Zealynx Security
Twitter/X · GitHub
License
MIT © Zealynx Security
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi