Oh_My_Co-Researcher
Health Warn
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 8 GitHub stars
Code Fail
- rm -rf — Recursive force deletion command in install.sh
Permissions Pass
- Permissions — No dangerous permissions requested
This tool is an extensible, autonomous agent skill pack designed for machine learning research. It acts as an AI co-researcher that can independently run experiments, review code, draft papers, and manage project workflows.
Security Assessment
The overall risk is Medium. The agent is designed to execute shell commands, as evidenced by its ability to run isolated ML experiments and install setups autonomously. While no hardcoded secrets were found and the tool does not explicitly request dangerous system permissions, the automated rule-based scan flagged a `rm -rf` recursive force deletion command inside the `install.sh` script. This poses a potential risk of unintended data loss if the script behaves unexpectedly or is poorly configured. Additionally, as an ML research agent, it inherently interacts with local project files and likely makes network requests to external LLM APIs to function.
Quality Assessment
The project is actively maintained, with its most recent code push occurring today. It uses the permissive and standard MIT license. However, it currently suffers from very low community visibility and trust, having accumulated only 8 GitHub stars. Because it is a relatively new and untested tool, users should expect potential bugs or rough edges rather than a polished, production-ready framework.
Verdict
Use with caution—review the `install.sh` script and your supervision policies carefully before granting this autonomous agent execution permissions.
Your personal co-researcher, evolved.
![]()
Oh My Co-Researcher is an extensible, self-improving agent skill pack for autonomous ML research. Like oh-my-zsh but for research agents — start from a lean core, let the agent configure and grow your stack.
A co-researcher, fully yours:
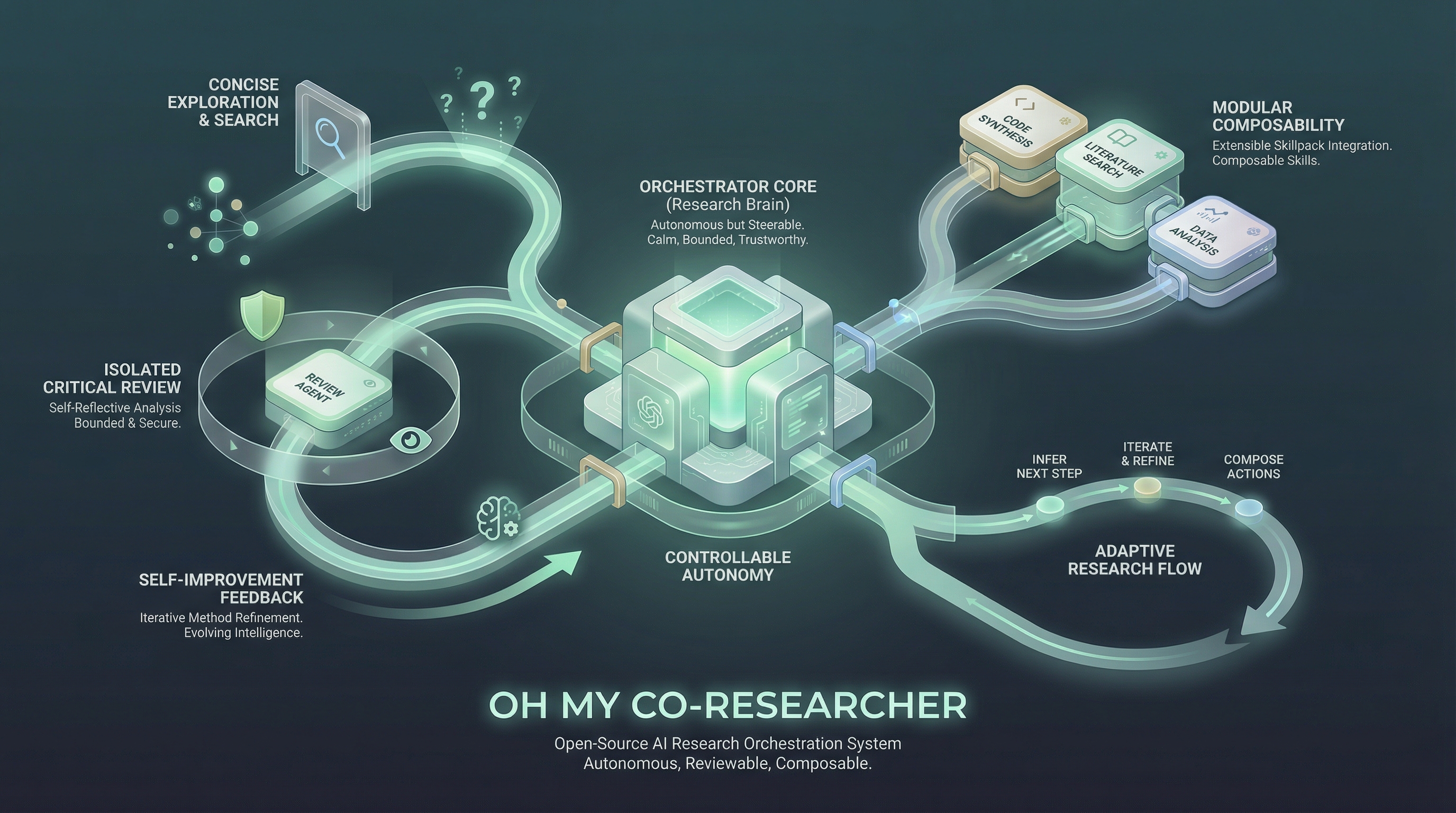
- Autonomous but controllable. Customize the supervision policy: when to ask, notify, or just do. Checkpoints, resource rules, idea-change rules — all configurable.
- Inferring agent.
researchspots gaps, adjusts the todo list, and asks before acting — not a fixed pipeline.- Adversarial review. Critic runs in an isolated context. Returns FATAL/MAJOR/MINOR issues + PROCEED/REFINE/PIVOT.
- BFS mode. Opt-in autonomous design space search in autoresearch style.
- Self-improving.
evolveproposes skill diffs from session lessons, or ingests external packs with compatibility checks. You merge.- Compatible & Composable. Use with any LLM agent framework. Pull in external skills from anywhere. Customize your stack.
Quick Start
Paste this into your agent (Claude Code, Open Code, Codex, etc.) — it fetches the setup guide and configures everything:
Install and configure "Oh_My_Co-Researcher" skill pack following the instructions in https://raw.githubusercontent.com/zy-ning/Oh_My_Co-Researcher/refs/heads/main/README.md and https://raw.githubusercontent.com/zy-ning/Oh_My_Co-Researcher/refs/heads/main/docs/agent-setup.md.
Then run /research in your project directory. If RESEARCH.md is missing, the skill bootstraps it and prompts you for your goal.
For manual / offline setup, see Installation at the bottom.
Core Skills
| Skill | What it does |
|---|---|
research |
Main agent. Reads RESEARCH.md, infers gaps, adjusts TODOs, delegates to the right skill. Follows your supervision policy. |
experiment |
Runs ML experiments: isolated venv, time-budgeted, failure-handled. Supports BFS mode. |
review |
Adversarial critique with FATAL/MAJOR/MINOR severity. Falls back through Codex → llm → minimax. |
write |
Paper drafting grounded in RESEARCH.md results. Marks [UNGROUNDED] and [UNVERIFIED] inline. |
customize |
Project onboarding. Recommends presets/skillpacks from the curated registry, writes .co-researcher/skills.yaml. |
supervision |
Configures ## Supervision Policy in RESEARCH.md through a preset-first flow. |
evolve |
Session-end lesson extraction and skill pack personalization. Proposes diffs — human merges only. |
How the Agent Loop Works
research reads your project state and figures out what to do next:
- Assess — compares Goal vs Context to find gaps ("experiments done but no paper TODO")
- Propose — adjusts the TODO list and waits for confirmation before acting
- Act — picks the top TODO and delegates to the right skill from the full ecosystem
- Loop — surfaces the result and asks "shall I continue?" or offers options
On any new session or context compaction, the agent reads ## Pipeline Status in RESEARCH.md first and resumes in ~30 seconds.
Customize Your Skill Pack
This repo follows a lean core + curated registry model. The agent manages your stack — you just pick a profile.
Run /customize to onboard a project or change your skill configuration:
- Choose a workflow profile:
core-only,literature-heavy,experiment-heavy,academic-rigor,balanced, or custom - Choose dependency tolerance
- Choose autonomy style and resource policy
- Confirm a preset or custom stack
- The agent writes
.co-researcher/skills.yaml
The registry lives in skillpacks/skill_dictionary.yaml. Curated bundles are in skillpacks/presets/*.yaml. Project choices live in .co-researcher/skills.yaml.
See docs/skillpack-customization.md for the full registry model and config shape.
More Skill Packs
Use evolve (personalize mode) to selectively pull skills from any of these:
| Pack | What it adds |
|---|---|
| ARIS | Best source of research primitives: lit survey, refinement, experiment planning, claim checking |
| Feynman | AlphaXiv paper Q&A, audit, and cited research briefs |
| NanoResearch | Alternative end-to-end backbone with 9 stages, SLURM/GPU orchestration, and notifications |
| AutoResearchClaw | Heavyweight autonomous research system with multi-stage planning and self-healing loops |
| AI-Research-SKILLs | Large capability library for specific ML tasks, infrastructure, and evaluation workflows |
| academic-research-skills | Specialist pack for academic writing, review, and paper-production workflows |
| scientific-agent-skills | Large scientific skills library for domain science, database lookup, statistical analysis, and research communication |
| claude-tricks | Claude Code overlay for debugging, investigation, code explanation, guided learning, and interactive slides |
Supervision Control
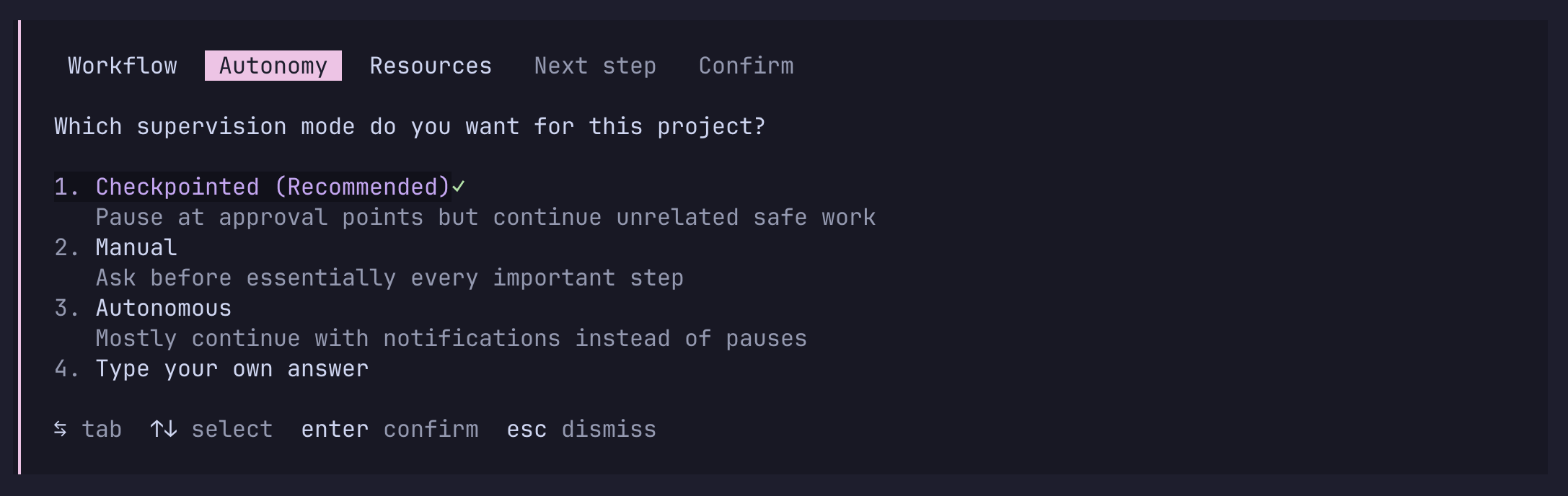
Use /supervision to configure how much autonomy the agent should use for the current project.
The flow is preset-first, override-second:
- Choose a preset:
manual,checkpointed,autonomous, orwild - Adjust notification events if needed
- Adjust approval gates if needed
- Choose stop target / limits
- Configure resource rules
- Configure idea-change rules
- Save the policy into
RESEARCH.md
The policy lives in RESEARCH.md under ## Supervision Policy — human-readable and survives session recovery.
Key capabilities:
- Queued approvals in
checkpointedmode so the agent can continue unrelated allowed work - Resource classes for Service / API, Compute, and Human / Physical resources
- Explicit control over whether idea improvements, strategy pivots, or compromises should notify or require approval
wildmode for non-stop execution until completion criteria or a hard boundary is reached
For full details, see docs/supervision-system.md.
BFS Mode (opt-in)
Inspired by karpathy/autoresearch. Ask the agent to "explore the design space" or "autoresearch". It confirms:
- Target file — the single file it can modify (e.g.,
train.py) - Metric — a verifiable scalar to optimize (e.g., minimize
val_bpb) - Budget — time per run (default 5 min) and max experiments
Then experiment runs autonomously: design hypothesis → commit → run → extract metric → keep or git reset → repeat. Every run logged to results.tsv. Summary table lands in RESEARCH.md Context when done.
Off by default — only activates when you explicitly ask. Even under wild, BFS still respects explicit resource rules, safety boundaries, and completion criteria.
Evolving the Skill Pack
evolve has three modes:
Session mode — run at session end. Extracts generalizable lessons from RESEARCH.md History and git log, proposes diffs to affected SKILL.md files.
Personalize mode — point it at any external skill or pack. It reads, checks compatibility, detects overlap, interviews you (all questions at once), then proposes a curated diff of only what you confirmed.
Registry mode — refresh skillpacks/skill_dictionary.yaml and preset recommendations.
/evolve # session mode
/evolve -- personalize feynman audit skill # integrate one external skill
/evolve -- personalize ~/.claude/skills/ # audit your entire installed pack
Diffs land in lessons/. Apply when satisfied:
git apply lessons/YYYYMMDD-personalize-slug.diff
Skills are never auto-modified. Human merges only.
Evolution Loops
Research loop: research picks TODO → delegates → updates RESEARCH.md → proposes next step → repeats.
Skill evolution loop: evolve (session) → lessons/ → human review → git apply → better skills next session.
Personalization loop: find a useful skill elsewhere → evolve (personalize) → curated diff → merge → your pack grows.
Registry loop: assess a new pack → evolve (registry) → update skillpacks/skill_dictionary.yaml → customize recommends better stacks next time.
Installation
Most users can skip this section — the Quick Start prompt above handles it automatically.
Core pack
# Project-local (installs into current directory)
curl -fsSL https://raw.githubusercontent.com/zy-ning/Oh_My_Co-Researcher/main/install.sh | bash
# Global (skills available in any project)
curl -fsSL https://raw.githubusercontent.com/zy-ning/Oh_My_Co-Researcher/main/install.sh | bash -s -- --global
Installs: skills → .claude/skills/, templates → templates/, skillpacks → skillpacks/, CLAUDE.md → project root (or ~/.claude/co-researcher/ for global).
Alternative via skills.sh (skills only — no templates or CLAUDE.md):
npx skills add zy-ning/Oh_My_Co-Researcher
ARIS skill subset (recommended)
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep.git /tmp/aris
mkdir -p ~/.claude/skills
cp -r /tmp/aris/skills/research-lit ~/.claude/skills/
cp -r /tmp/aris/skills/research-refine ~/.claude/skills/
cp -r /tmp/aris/skills/experiment-plan ~/.claude/skills/
cp -r /tmp/aris/skills/result-to-claim ~/.claude/skills/
# Optional extras:
# cp -r /tmp/aris/skills/arxiv ~/.claude/skills/
# cp -r /tmp/aris/skills/paper-figure ~/.claude/skills/
rm -rf /tmp/aris
These are the ARIS skills this pack benefits from most:
research-lit— literature surveyresearch-refine— method and idea refinementexperiment-plan— experiment blueprintsresult-to-claim— checks which conclusions the results actually support
Skip by default: run-experiment, paper-write, and auto-review-loop. This pack already ships experiment, write, and review.
Codex MCP (optional, recommended external critic for review)
npm install -g @openai/codex
codex setup # set model to gpt-5.4 when prompted
claude mcp add codex -s user -- codex mcp-server
review prefers any isolated critic context. Use Codex MCP when you want an external boundary in Claude Code. Additional fallbacks: auto-review-loop-llm (set LLM_API_BASE + LLM_API_KEY) or auto-review-loop-minimax (set MINIMAX_API_KEY).
Feynman skill pack (optional)
curl -fsSL https://feynman.is/install-skills | bash
feynman alpha login # authenticate AlphaXiv once
Provides: alpha-research (paper Q&A, alpha ask/fetch/repo), audit (paper-to-code reproducibility check).
LaTeX (optional, for PDF output)
brew install --cask mactex && brew install poppler # macOS
sudo apt install texlive-full latexmk poppler-utils # Ubuntu
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found